Sifting Through The Noise, Advanced Threat Analysis
Show transcript [en]
hello everyone uh the topic for my presentation is going to be sifting through the noise uh my name is David Sher and I work as a data engineer at alphatex uh on the sphere project sphere is a threat intelligence system uh which uh makes it easier for blue teams to analyze and understand threats as well as mitigate them better so what does sifting through the noise mean well at least for my purpose it means understanding and categorizing a very noisy data specifically when it comes to web service logs um the visual here is not very clear because of the quality I'm going to try to zoom in so for example like uh if you've had if you've ever checked any
server logs you would see something like this on the left and what we want to do is uh go from that into something that is a bit more structured and makes it easier for people to understand so a high level overview about this uh is uh all of the steps that we're basically we can take into making this possible the first step as always in any uh data engineer project is uh data collection this this for our purpose is done using sensors to collect and uh format logs to make it easier for us to parse the second step is basically storage any database will do for this purpose uh for example post SQL MySQL or
any nosql database that will depend on uh what kind of queries you want to do and how you want to uh basically retrieve this data uh the third step is data processing uh this processing can happen using different methods uh which uh I will go into more detail later on uh however it will also depend on what you are trying to do uh depending on your purpose uh and the last part is interpretation for interpretation we can have a mix of automatic and as well as uh Manual Labor uh kind of interpretations uh however to do this manual interpretation easier for many people it's essential to have it visualized and uh visible in a way uh to
make it uh much easier to understand so this is how most people think data engineering works and to an extent it's true for a lot of people who uh work for it as well however uh the all these methods that are essentially used do have something underneath and are uh un understood by people who who have done the harder work for most of us uh so uh for our first step which I mentioned uh meaning the collection of the data we use something called decoys now what are decoys a decoy is a system or a service that monit and logs incoming and network traffic uh decoys can be as simple or Advanced as you want them to be but uh
this will always depend on your task and what kind of data you are trying to retrieve or from what kind of service you are trying to retrieve that data for my rule of Thum is that uh for example you do not want to make it over complicated and uh uh waste a lot of time into making something so realistic because uh at the end of the day uh someone might still figure it out a good way to make a good decoy is to basically put a login screen on it uh for example a lot of firewalls or vpns have a login screen which means that uh uh this will in some way uh entice threat actors into thinking that they
are dealing with a legitimate system uh not everyone can fall pre to this of course uh with enough effort if you for example interact with this decoy and try to see the different kinds of requests and responses that you get from it uh you are uh somehow you can somehow notice that there's some discrepancy from a real system on the decoy however there are ways to mitigate that as well but uh for most purposes uh a login screen is just fine we can also add some more fun things into it for example we can uh see some specific recent exploit that happened in that system and we imitate the response that that's that system would give so using
that uh we can make threat actors into thinking that they've actually achieved their exploit and now they're pinging the beacon to get access but that will never happen of course this is a good way to waste a threat actor's time as well as collect very good uh threat data basically uh so how do we make sense of this noise uh obviously a lot of this data that we collect from these decoys uh have are very noisy uh you can try to understand them manually and go through them and that's one way to do it but that is a task which is very hard and takes a lot of time and effort which means uh we have to look into more
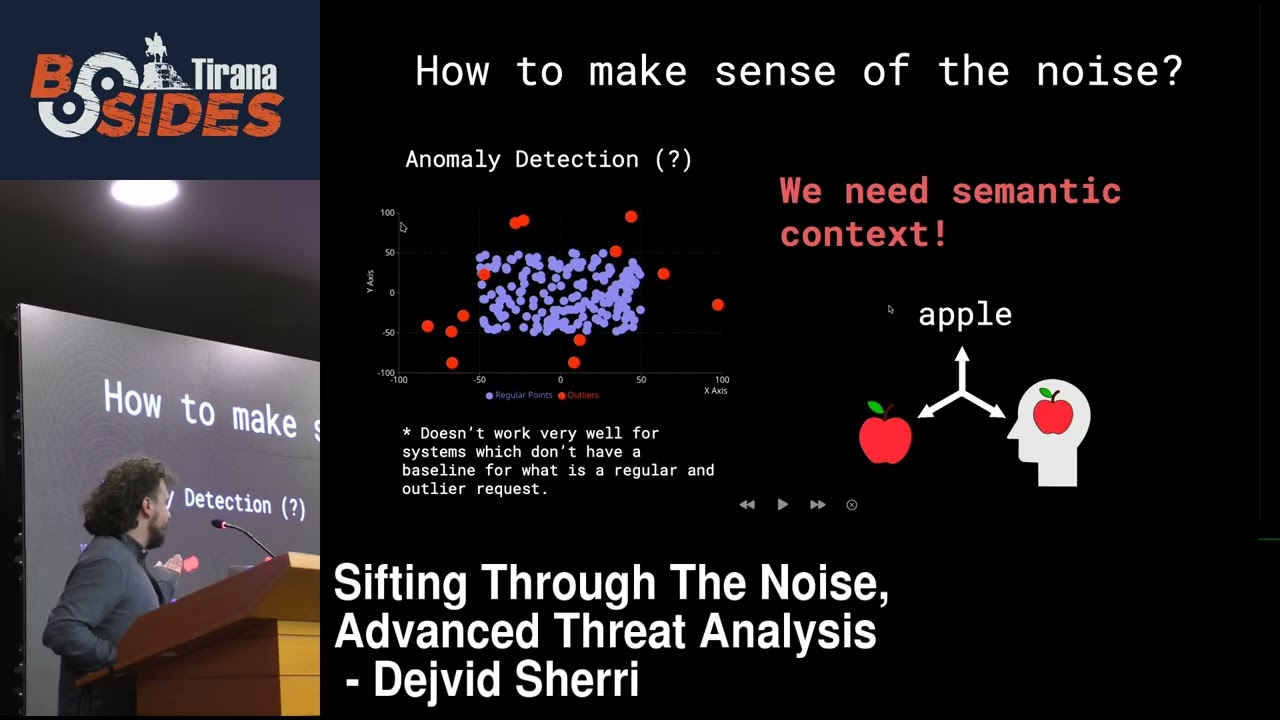
automatic ways to do this one of the ways that I've seen is anomaly detection and I try to understand uh how anomaly detection could work in this case uh however that's that doesn't really work in our purpose because a lot of this data is not for a real system and a lot of the responses we give are not the real one so we cannot know a good way to understand what is for example uh an anomaly or not uh for this specific uh use case for the logs themselves we need to understand semantic context uh which means uh it's very hard to to explain but basically semantic context just means uh what we understand as humans uh relating to the words and
uh uh in that way uh even the logs themselves when they are written they are written to be human readable but they are in most of the cases it's very hard to read them as as a person and to make the semantic context understanding uh at least somewhat automatic we can use uh a lot of different other methods methods which I'll get into uh right now so first of all we need to get into a bit of the specifics of what makes an exploit and uh that works through uh identifying where the exploit can be contained in this log data usually when we look at web server logs for example uh PHP or uh engine x what
whatever web service that you want to look at they do not uh actually uh register or log everything that's part of every request because uh to be fair it's a lot of data that can go through uh this means that you have to go a bit deeper and make uh make sure that you have captured everything from this request that you you you got into your decoy and usually the highlighted points that I have uh mentioned here usually might might contain some kind of exploit but that's not always necessary if we look at one specific case which is a very recent exploit uh it's uh this cve 2024 for 4577 which is an exploit that happens on
the PHP CGI and it's an argument in t uh uh what we can infer from this this uh log that we have collected here I know it's not very visible uh but let me zoom in okay so what we can infer from this we can see that uh the request query steering itself is the actual exploit which is doing the malicious thing and in the form data we have collect it's where the uh cell is being contained okay so knowing this context that each one of the different parts can have the exploit or contain it uh I went into researching into many different articles and different research papers that uh I managed to find and one of them is
actually linked here so if anyone wants to take a look at this article uh if you get the slides later you can you can check it out because a lot of these things are very extensive and would be very hard to explain in 30 minutes uh but essentially this is a high level overview of what kind of different ways that we can use to to do some sort of automatic analysis for this data uh what I actually went with was specifically clustering and uh after considering many different methods I realized that uh specifically clustering is very important because all of this data can be uh uh very uh very noisy and it can have uh a lot of things uh which
means that we need to have some way to categorize them and find uh which uh which kind of uh log can be similar to the others that is what essentially clustering does it clusters logs that are very similar to each other and adds them to a group and this means that it can reduce the amount of automatic or manual labor from uh I don't know thousands into maybe tens of uh manual text or automatic ones so uh here is where I've actually uh want to show something that I've uh built for for this specific presentation at least uh I needed to find some way to try all the different methods that I mentioned and uh like actually adding them to the
database and querying it back to see if if the clustering worked uh was very tedious so I decided to put it all into this fancy DUI using pqt and P openl I also really wanted to make uh make it easier for me to uh somehow tweak the values and see how that reacts with the data itself and uh right now I'm going to show you the specific DOI so uh because I couldn't really uh demonstrate this live although that was my preference uh I recorded this video of uh specifically one of the feature extractions and the visualization itself is happening uh here in the 3D space so uh what's essentially uh this part uh uh what
essentially clustering does is split it into many different different uh clusters uh this is done through first of all uh extracting the semantic context from it which is uh you it can be used with many different methods so you have to do feature extraction you can use tfidf which is used in many search engines uh or uh what I what is the new thing and uh even large language models use it uh is embeddings and embeddings seems to be the answer at least for for this case even though tfidf had some some uh achievement to it but it still wasn't enough to actually split everything as as uh tidy let's say uh after you've embedded it uh after
you have embedded the log which is essentially just a a sentence uh which tells you a bunch of information after you've embedded it it splits itself into not split but it projects itself in a higher Dimension uh and using that uh we can use DB scan uh which is the clustering method itself and DB scan uh makes the clustering however uh through the embeddings we can reproject the higher dimensional points which can go depending on what kind of model you're using uh it can go from 5 512 1024 and uh in this case I actually used the 512 model uh however I would have to to basically remove parts of the request itself itself to make it to make it
actually do the embedding because some of the requests went on too long and there was like a lot of parts in in that uh in that request itself so here is just some examples as you can see uh the requests themselves have a lot of a lot to it in Parts however we can see that for example this one has been split into this specific endpoint and it's not only endpoint specific it actually takes the whole log and sees the similarity between each each uh different logs and add adds them to the cluster so this was uh this was the uh first version of of this visualizer uh I'm actually have worked very recently hard to try to make it ready for today
and to have it open source for everyone to check out uh but but that wasn't the case and the code really needs some reworking so hopefully in the next few weeks I will I will have it ready and uh maybe you can ask me for the GitHub and I'll be happy to to share it
um so as I showed before uh trying all the methods is is very important uh especially because a lot of people have worked on these problems before and uh that means that there are solutions to our problems uh before we even uh thought what the problem was a lot of people have done a lot of work for for this kind of thing uh some promising Concepts that uh to look into which I found interesting was for example fine-tuning of base embeddings model so you take the log data that you want to do specifically and use that to uh to fine-tune your model to make it more efficient into uh to do the specific uh embedding for that kind of data we can
use uh after we've clustered all this data we can use some sort of regex to see exploits uh to extract some specific kinds of exploits for example path reversal you can easily see it because of the dots and slashes uh and uh automatic tagging through language models this is something which I've experimented with uh still still needs work I think uh I don't and if you're interested I think it's something that uh it is good to look into uh so this was a very short and uh very fast-paced uh overview of how this could work clearly there's a lot of research that has gone uh into into the people that have first of all made all of these
models for example in the previous one uh I had all the all mpet Bas V2 uh this this is the research paper that actually saved my project because uh it explained things in a way which it was very easy to understand there's also a link to this paper paper um and at some point I was really stuck because none of the methods when I was doing the tweaking manually uh were working and not to the extent that I really wanted and this paper had uh some way of uh actually uh uh using uh other models to which were machine learning models to uh sort of optimize the Epsilon value which is a value that is essential when
you're using the cluster clustering algorithms and basically uh decides how the clustering will be done it's it's it's a simple value of from uh 0 to one for example uh so that was uh my talk thank you everyone for attending
Related talks
 20:58
20:58 30:27
30:27 55:35
55:35 45:10
45:10 43:57
43:57 24:21
24:21