Red Teaming: A New Perspective for Intern Projects
Show original YouTube description
Show transcript [en]
[Music]
[Music]
All right. Hello. Hello. How you guys feeling this Sunday morning? I know, right? True Bides truthers here today. Love to see it. Love to see it. Uh thank you guys for coming out. I really appreciate you guys uh taking the time to listen to us uh yap about our project that we've been working on. It's called Red Teaming, a new perspective for intern projects. Um uh I'm Mia Hagood and I'm Kenyan Chambers. And uh let's get started. So first we'll give you guys an introduction of who we are. Then we'll give an overview of the summer internship that both of us participated in. We'll talk about blackbox red teaming and white box red teaming research we conducted. And finally we'll
talk about innovations and conclusions from our work. And at the end if anyone has questions you can come and talk to us at any time. So I'm Mia Hagood. I graduated from Virginia Tech um in spring 2024 majoring in computer science. In 2023, I started as a summer intern at Practis Engineering Technologies. And then after I graduated, I came back to participate in Practis's internship again. And then finally after that, uh, I started as a full-time employee and that is what I'm doing now. I'm Kenyan Chambers. I graduated from Buoie State University in December of 2023. Uh before then I did an internship at practis in 2023 and they brought me back for the 2024 internship. Uh after
that they brought me on full-time and here I am today. Okay, so to give some background on our internship, um, in 2024, last summer, Kenyan and I participated in practic's soft summer software internship program. And the objective of our project was to identif uh design facial and speech-based identity recognition systems for access control. Along with that objective, we had a few requirements. The first of which was to be able to identify three authorized users. The second was not relying on remote services to run such as the cloud. And our final requirement was to be resilient to adversarial attacks which are techniques designed to manipulate or exploit a system using carefully crafted inputs or data. Uh so to meet our requirements of
avoiding any reliance on any one cloud service or uh creating the fully remote solution uh we deployed our machine learning models onto Arduino nano or microcontrollers uh specifically the nano uh 33 BLE sense light. Uh and this device handled the face and voice identification entirely on the device itself and communicated using Bluetooth low energy. Um, we utilized the camera module that came with the actual device kit and the proximity sensor and microphones that were located on the device board in en order to uh collect the necessary data that we needed in order to be successful for our project. Um and while the Arduinos provided the lowcost standalone operations that we needed in order to be successful, uh we
encountered some hardware constraints related to the actual quality of the output of the samples that we were getting. Uh for example, um the low memory on the device, 1 megabyte of flash storage, 256 kilobyt of RAM uh on the entire device. That's small in terms of the sensor quality uh pretty moderate compared to anything that Mia and I were used to. Um and but the as you'll see later on in this presentation, the images that we were getting from the camera and the quality that we were getting from the microphones was pretty bad. But uh this shaped our divine our design process and our performance of the models and the our ability to deploy them onto the Arduinos themselves.
um our data collection methods. Despite it all, the platform was pretty crucial for us reaching our project goals. And in order to meet those project goals, uh the interns were split into three groups with three specific uh tasks. Uh there was a face team tasked with designing face- based identity recognition systems. uh voice team to tasked with designing a voice-based identity recognition system and a red team to test the resiliency of both of our solutions and uh explore different adversarial attacks. And while each team focused on their own specific tasks, uh we also collaborated effectively by uh sharing progress and findings over the summer. Um for example, we all had a daily stand-up meeting where we would share
updates and blockers and be able to talk with mentors directly. uh the face and voice teams collaborated especially when we were building out our physical rigs for our uh Arduino setups and I'll pass it off to you. So in order to ach in order to achieve the first requirement of identifying three uh three authorized users, the face and the voice teams collected hours of data from both our Arduinos as well as online data sets to represent the identities of our three authorized users as well as unauthorized users. Each team pre-processed their data to ensure clean and standardized inputs for models. And then they labeled each sample as one of the authorized users or unauthorized to
create training data sets for machine learning models. The teams achieved their facial and voice-based identification by specifically training neural networks. These are a type of machine learning model that mimic the human brain. So you give the model data, it produces an output or prediction based on parameters like weights and biases. And then as you give it new data, it iteratively adjusts its parameters to train and improve its performance over time. As a result, neural networks are great at learning patterns from vast amounts of data without needing predefined rules. And they're very good at adapting effectively to new environments or inputs. After weeks of training um and testing iterations of our models, the face identification model was able to
achieve 97.8% 18% accuracy while the voice identification model was able to achieve 96.1% accuracy. Uh the models were or after the models were trained uh they were optimized and compressed in order to be deployed onto the Arduinos to satisfy our second requirement of non-reliance on the cloud. Uh each team designed their physical rigs to make data collection and model testing more efficient across development. Uh the face rig was designed for uh three separate Arduino camera modules uh inferencing or taking pictures concurrently uh to capture the face data. We had one for our front angle and then two for our side profile images as you can see in the image on the what's that the left um and the
voice team also built a rig for three Arduinos collecting voice data in parallel. Uh then a user would activate a session by um activating the proximity sensors on all three Arduinos by waving their hand in front of the device. Our third our third requirement which was to be resilient to adversarial attacks presented us with a challenge unlike any previous internships or school projects that we had participated in before and it involved implementing red teaming. Traditionally to us, we knew red teaming as a process for testing cyber security effectiveness by simulating attacks on a system. However, this project showed us that there can be threats and adversaries to magic or manage in any industry beyond just cyber
security and for our case machine learning making red teaming a significant piece of any design process. As a result of our red teaming, we unveiled vulnerabilities that could have been overlooked in a traditional internship approach and we will present the vulnerabilities and mitigations that we found during our internship and our red team research. So in summary, our teams successfully designed lowcost accurate solutions that met the project's objectives and requirements. We were able to identify up to three authorized users using face and voice. We were able to function remotely from the cloud and we were resilient to adversarial attacks. In addition, we had the opportunity to present our projects at the AFCIA summer internship presentation competition where our phase team even
won best technical for their work. Next, we're going to discuss the red teaming research that we did during and after our internship. So first we will talk about blackbox red teaming which is primarily what was done during our summer. Blackbox red teaming is when attacks are simulated without knowledge of the internal system. So in our case the machine learning code uh training data set model parameters etc. Basically, as attackers, we can't see inside of our system. And this unveils vulnerabilities that can be exploited from outside of our network. There are a few advantages. The first of which is that you are sharing the enduser's perspective. This is someone who would be using our identity control system without knowing how we
were able to achieve it, not knowing anything about the models that we used or training data, etc. And so basically um you're not seeing anything behind the scenes while doing this type of testing. You also are able to reveal functional vulnerabilities and conduct this testing in early stages of testing which is beneficial because it means you can do it without having a fully perfected or trained model. The one limitation that we found however is that blackbox red teaming can miss internal code vulnerabilities and edge cases. So in the early stages of building out our face model, I was on the face team. Uh the red team identified some factors related to uh environmental elements that impacted the quality of our
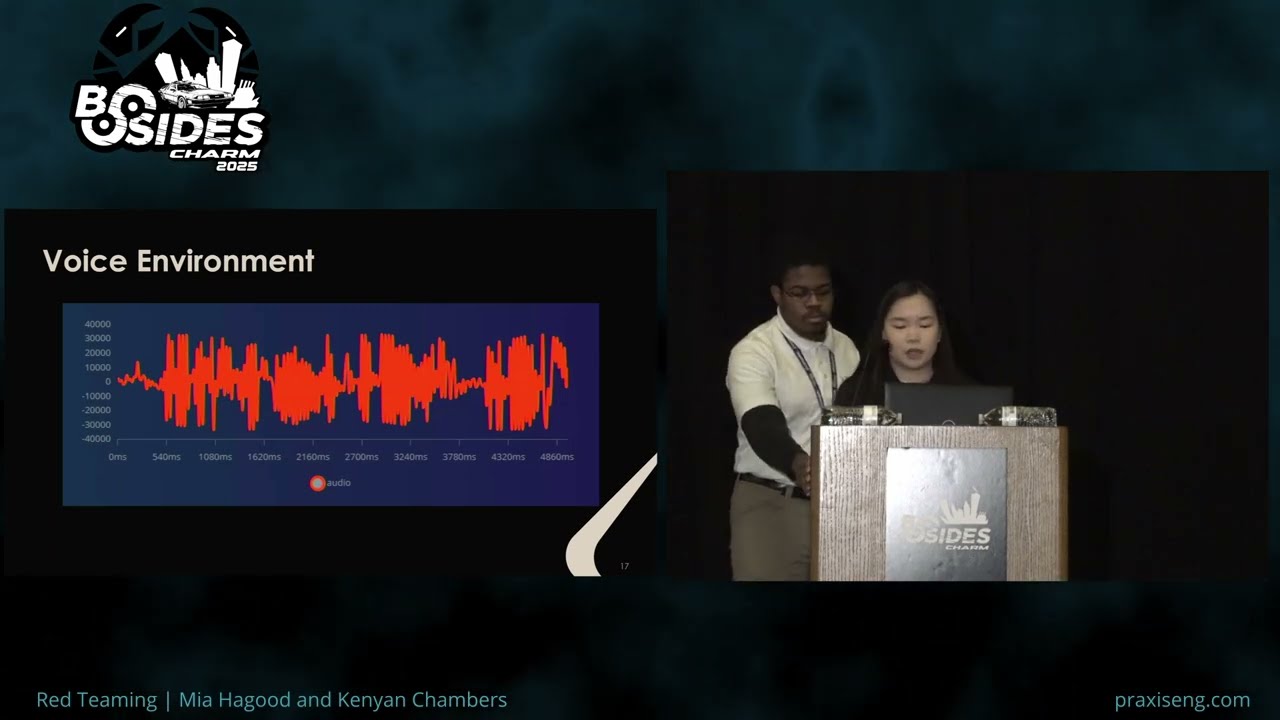
predictions pretty early on. Uh that being maybe distance to the camera, changes in background sure color and lighting, etc. And these factors introduce noise into our data set causing our model to form erroneous clusters for samples under the same label rather than a unified cluster uh samples for each or rather than a unified cluster of data for each sample based solely on facial features. Uh label by the way is the value that the model tries to predict for a sample. So shown here we see multiple samples uh for a label called authorized user uh three. So due to the model's inconsistent predictions, uh, samples under a label were sometimes being mclassified simply because maybe he was
too close to the camera or maybe the light was bouncing off his face in a weird way. So to mitigate the interference that we were getting from the distance, shirt color, and background, we employed a cropping script to decrease the padding around the subject's face. And this would encourage the model not to prioritize anything external and eliminate most nonfacial features. Uh variations in lighting also led to the formations of erroneous clusters. Uh so to address this, we integrated light bars into our setup in order to standardize the lighting across the entire uh sample set. We also captured images under a different range of uh uh different controlled background lighting uh in order to increase the diversity of our
uh sample set. And this uh made our model more robust to understanding like okay what exactly is a face versus honing in on any one specific lighting pattern. Uh we tested this by we put sticky notes on the side of our faces when we were uh doing inferencing in order to hide some of the uh contours that were bouncing off of the uh our faces in any max lighting conditions. And uh our prediction still graded out pretty nicely. So by making these adjustments and minimizing the model's dependency on anything environmental, uh we promoted more accurate clustering based solely on facial features. Um and any further red teaming for these our standardization techniques proved unreliable for them.
So, similar to the face team, red team was able to exploit vulnerabilities in the data collection and testing environments for the voice model. So, I'm going to play two audio samples that were collected of authorized users voices earlier on in our process. So, here's our first sample. So, I got a peach milkshake and I I thoroughly enjoyed it. It wasn't bad. And now, let's compare that to our second sample. or a little earlier, but big sad. So, between these two 5-second samples, we were able to identify several differences, such as the volume that our first authorized user spoke at compared to our second, background noises that would play during the clips, as well as different amounts of silence and
pausing. Um, we noticed our second authorized user tended to stop speaking a lot earlier than our first one. So with smaller data sets, these inconsistencies are easier for a model to overfitit toward, which means that the model could correlate voices to inaccurate features. For example, if the red team played or spoke really loud, the model might decide that has to be the first authorized user because all of his audio clips were significantly louder than the others. This was the vulnerability that our red team discovered and exploited. They had realized our model was focusing too much on features or noises that weren't a direct product of the authorized voice itself. So we mitigated this by standardizing
our data collection and improving our training data quality. First, we standardized the distance that a person could record their samples from by using the Arduino's proximity sensor to activate the microphone for recordings. This ensured that samples were within a standard volume range um no matter what room or environment the t the sample was taken in and even across several weeks of testing. We also made sure that the training data for all of our authorized users was balanced, meaning equal amounts of samples and equal lengths of clips um for each authorized user. We realized that if we had significantly more data for one user compared to the others, the model would overfit predictions towards that one label
instead of equally identifying patterns for each individual. Finally, we also ensured that our training data covered potential environmental scenarios. So, as we recorded samples, we made sure to include different varieties of background noises, um, silences and pauses throughout our clips, different volumes of speech, as well as trying out different emotions. After making these improvements, our red team could no longer use the environment related tricks to interfere with our model's predictions, and therefore, our model was more resilient to those attacks. Uh so next we're going to talk about how racial bias impacted our data collection methods. Uh on the left is our authorized user, one of our authorized users. Uh we'll call them authorized user one. And on the right are some
subjects that are representative of our unauthorized data uh for one of our side profile cameras. Uh we got this data from a reference angle site that where users typically artists would orient a 3D model or a 3D uh yeah 3D model at different angles in order to get a list of subjects facing at that specified angle. Uh so early in the process of deploying our face model uh the red team intentionally explored some arbitrary inputs by uh submitting side profile images of authorized users at a variation of different lighting and uh ang or lighting conditions in different angles in order to stress test our new uh standardization techniques. Um, and our authorized uh, Asian male uh, even
at the intended angles uh, triggered an odd amount of false negatives. And this uncovered an issue in our training data due to our collection methods that uh, the unauthorized side profile data for that camera disproportionately represented Asian people. And that skewed distribution led to an our authorized Asian male being uh, classified as an unauthorized user. I did not cherrypick these images. uh uh when we collected the data initially and we went back and we looked at it over twothirds of the data consisted of like Asian samples. Uh so what does this mean? Right? Biased data whether arising from flaws in your collection, selection or labeling uh will severely impact the fairness of your model. Right? And models trained on
bias data amplify those data or or amplify those biases. Uh often underperforming for underrepresented groups or over represented groups. Um and it highlights how the models or how biased data restricts the model's capacity to learn any meaningful patterns. Right? And the impact of biased data extends to how models define their decision boundaries. Uh which can result in some pretty poorly placed separations in bias data sets. So for example, if all dogs in a data set are golden retrievers, uh the model might learn a bad rule like having floppy ears uh makes you equal to a dog, right? So such oversimplified boundaries can make the model vulnerable to any sort of adversarial attack, which we'll get into
a little bit later. Uh so to address these challenges, we improved the diversity of the data set by refining the unauthorized class in our project uh to include a more diverse range of uh samples with different ethnicities uh different genders and uh different lighting conditions to ensure better generalization and reduce the amount of false negatives that we were getting. Uh we also audited our data sets. We examine the data sets for any skewed distributions or underrepresented groups to ensure the fairness and equity of our model predictions after red teaming. Second, a second vulnerability that the red team exploited for our voice model was using AI deep fakes. They gathered audio samples of our authorized users
around the office and they used artificial intelligence to generate fake audio clips of them speaking um whatever they decided that they wanted us to say. They found that they could then play those deep fake samples and be recognized as an authorized user by the model even though they weren't even using live audio or human voice. So, here's an example of an inspirational artificial clip that was created to mimic our first authorized user. It's never too late to find your voice. It's about courage. And then here's a real audio sample of something he would actually be saying to our model. Crazy crazy good data set. I think it's definitely going to like overpower what So although our earlier model wasn't
able to detect the first clip as unauthorized or artificial, we noticed difference between we noticed differences between the samples. Like for example, when we looked at the audio waves, we could tell there were differences um when there were pauses between words. So for the artificial samples, the silences were just perfectly horizontal because there was no noise being picked up at all. Whereas in a real scenario, there would be natural background noise that was being picked up by the mic. So even if the user was pausing between words in the clip, the audio wave still showed some frequencies being picked up. So if we as humans could identify these patterns, our neural network could definitely have the ability to pick up
patterns and recognize AI generated non-human voices. And we tested that hypothesis by incorporating deep fakes into our models training data set. And as a result, we did successfully mitigate the risk of AI deep fake voices. um when our red team would generate new AI clips and try to play them to the model, it would be able to accurately label them as unauthorized because having the AI voices in the training uh taught the model to recognize those patterns and realize that this isn't an authorized user regardless of whether it's a human or not. All right. So, next we're going to talk about our white box red teaming techniques. Uh so, white box red teaming is a software testing method where the
internal structure, logic, and code implementation of a system are evaluated. Uh so, unlike blackbox testing, you got to have a pretty uh deep understanding of the underlying source code behind uh your system. So, now the box is open and we can see inside of it. Uh so some advantages to whitebox are that it ensures the code functions as intended by looking at things like uh security vulnerabilities, logic errors and uh performance issues and some limitations are that uh as your programmer in our case our model uh grows in complexity uh testing every possible branch or input scenario becomes a little impractical. uh also whitebox testing looks more at the internal code or model structure in our
case rather than any userfacing issue or real world edge case. So uh our objective as a red team was to stress test our model beyond any like standard unit testing of hyperparameters. Uh we wanted to explore how to manipulate and deceive our model using these things called adversarial examples which allow us to manipulate the input slightly uh to change the components of a of a certain model classification and M is going to talk a little bit more. Okay. So I'll now go into the model vulnerability that we as the red team were able to exploit. So, as stated earlier um when discussing racial bias, biased data often fails to represent the full diversity or complexity of a
problem space. And so, models trained on such biased data may learn inaccurate feature relationships that result in underfitting, which is where the model oversimplifies and fails to capture true patterns in the data. And this can cause important features to be skipped. So for neural networks including the ones that we implemented um they often rely on activation functions to decide which features are important for making predictions. We used rectified linear units or the relu activation function for um our case and this is popular for deep learning because of its computational efficiency and training ease which aligned great with the Arduino controllers microcontrollers that we were using for our project. ReLU is a simple function that outputs
zero or a linear transformation um function therefore creating a a continuous decision boundary made of linear regions. Um however these linear regions are rigid and more prone to underfitting and therefore exploitable biased data. So in the image that we have here there is a decision boundary dividing the purple and the yellow regions. And the majority of the points that are in the purple region are green while the majority in the yellow region are blue. We want to emphasize that there are points misidentified specifically those that are uh located right on the decision boundary. So if you look at where the regions are split up there are blue dots in the purple region and green in the yellow region
which is incorrect. And this reveals the vulnerability of the RLU activation function which we'll discuss how can be how we can exploit that as the red team specifically in our next slide. So uh Mia was explaining that we can create adversarial examples that intentionally exploit those linear regions. Right? Since the model's understanding was very black and white, any small intentional change to an input can shift it across a decision boundary which leads to a very high confidence uh mclassification. Uh so over here on the left uh we could see the data and around it is formed a decision boundary right and if we zoom in uh let's say for this or for this example uh the green data
points are representative of images of green apples right the blue data points are representative of images of blueberries uh so even though we're very close to the decision boundary uh over like right by the line uh and near other O's or green apples any slight change to that input can shift that O into X territory or green apple or blueberry territory. Uh so for example, this could be something like shifting a few of the green pixels on the uh image of the green apple that the model weighs very highly in its decision to say this is an image of a green apple. What if we made those pixels slightly bluer? Right? Uh so also the upper left and lower right
hand corners of the image on the right um show up as very confidently being classified as green apples and blueberries respectively. Right? Even though we've never seen any data over there at all. So this linear peacewise family of models uh forces or or family of functions forces the model to be very competent in these regions that are very far from the decision boundary. So by nudging inputs just enough for samples on either side of that decision boundary to cross over, uh we can get a very high confidence prediction for any image perturbed with a very uh carefully chosen amount of noise. And if we could force a apple to look like a blueberry to the model, we can absolutely force an
unauthorized user to show up as an authorized user. And we could do that using this algorithm called the fast gradient sign method. So before we talk about that, talk a little bit about gradient descent. Uh what is gradient descent? Right? It's used during training to help a model learn by adjusting its internal structure. So its weights and its biases. Uh and and it does this in order to reduce error. Uh so uh this was a GIF. Uh, it's not a gift now, but you guys are smart. So, uh, let's picture a ball rolling down a hill, right? It's rolling, it's rolling, it's rolling. The model's getting better, better, and better. And until it the ball settles at the bottom of the
hill, uh, that's your best case model, right? So, the lower the ball is on the hill, the better the model, right? FGSM or the fast gradient sign method flips this idea in that it's not used during training, it's used after training on essentially the same math that's used to compute gradient descent. Uh, and it does this in order to make adversarial examples. So, FGSM looks at how much the model's output would change if we tweak the input just a little. It's done like I said during using the same kind of math. uh but instead of calculating that gradient with respect to the model's weights, it calculates the gradient with respect to the input image. Uh so let's
say or not the input image but just the input, right, for both of our cases. But let's say you know for an example, you have an image and you zoom in and there's a bunch of pixels, right? Each pixel is assigned a vector and that vector points in the direction uh of the or the direction that reduces error the most for that model. Right? The model assigns that vector. Uh so FGSM uses the gradient of the loss function with respect to that input image in order to say uh how much change or it tells you how much changing each pixel uh affects that loss, right? And then it takes the sign of that gradient to ensure that the
pertubation for each pixel is the same size. And the sign function then nudges each pixel in the direction that increases the loss the fastest. Right? And that change is controlled by a very small value. It's a unit interval. So between 0 and one called epsilon. Uh so let's say we have an epsilon of 0.005, right? a very tiny number, right? If we apply that epsilon to every vector for every pixel and nudge it in that direction by a factor of 0.05 uh positively or negatively in the direction for any pixel that increases the loss for that specific pixel. Uh that's what FGSM does and it freaks the model out, right? But it's not enough of
a change for the human eye to notice. Uh the image looks normal to us, right? But the model sees something that's very different and it'll make a very competent but very wrong prediction based on that sample that it's getting. And that's the power of FGSM is that it exposes how sensitive these models are uh to any sort of feature detection. Right. Okay. So now I'm going to show how we used FGSM to create adversarial examples. The first will be for the face model. So first we start with a clean data sample. There's been no tampering and our model is able to see that it's an unauthorized user. Then we use the FGSM algorithm to create a perturbation
filter that would look like this. And using the epsilon value that Kenyan discussed, we can change the opacity of this filter. So the lower that the epsilon is, the lower the opacity will be and therefore the more imperceptible the changes are going to be when we overlay that with our clean sample. So we take our um filter, lower the uh epsilon as much as we can while still maximizing error, and we overlay that with the clean sample to create our adversarial example. And our goal which is to maximize error can be seen. Um we were able to achieve that here because our model saw the what was you what used to be unauthorized user as authorized now. And so we would
consider this attack as the red team successful. So here's another example for the voice model instead. The process is pretty much the same except just a different type of input data. So this is what the input data looks like for the voice model. This is called a spectrogram and um this is how our model is able to extract features for audio. Then we use FGSM to create our perturbation filter. We lower the epsilon as much as we can while maximizing the error in the predictions and overlay that with our clean sample to create our adversarial example. And we had a successful attack here because now our model sees that originally unauthorized sample as an authorized
user. There were a few ways that we came up with to mitigate the risks of these types of attacks. The first of which was training on adversarial examples. So we incorporated adversarial examples into the training data sets of both of our models. And similar to administering a vaccine, training on a mix of both clean and adversarial examples protected the models against new FGSM attacks in the future during testing. And as a result, it increased our prediction accuracies when facing adversarial examples and it decreased their error regardless of how small the epsilon value was or imperceptible the changes were to our human eyes. Uh so another mitigation technique that we used was called label smoothing. Uh
that's just a regularization technique which just means that we had a penalty to Weber loss function that we use. Uh we used categorical cross entropy which was really good for our uh multiclass classification use case. uh at the end of the neural network we get a soft max which gives us a probability distribution or the likelihood that a sample fits into each class and the largest value is the highest probability right but the process of giving uh super high importance to the most likely class however pushes the rest of the classes to very small values so that probability distribution loses any sort of relativity. Uh so for example here we aim to predict the percentage chance
that one of these pictures is of authorized user one right who has the red border. Um and we can see on the left the hard labels uh say that authorized user one is 100% uh for that image but for the other two it's 0%. Right? which you'd think would be really good, but it leaves no room for the model to assign probabilities for any of the other labels based on some of the features or more complex features that it needs to extract. Right? The model isn't generating features to its full potential. Uh and we maybe we want the model to think that an image of authorized user one and authorized user two, which is me, uh maybe we wanted to
say uh these two are more similar because they're both wearing glasses, right? or maybe authorized user one and authorized user three are more similar because they're lighter skin tones, right? We want the model to learn relative similarity between these classes, right? And in doing so, the model might understand which features are uh more important for differentiating between those classes. So in order to do this uh we smooth the labels, we uh scale a temperature gradient and then we divide it by the model's predictions in order to soften those labels and reduce overcompetence. And that's coupled with this mitigation technique called defensive distillation. Uh distillation uses larger more accurate models called teacher models to train these smaller more efficient
student models on their output. Uh the teacher model is a normal uh much larger model that generates the soft labels uh using the temperature gradient stated uh in the previous slide. And the student model is encouraged to learn a broader range of predictions based on the soft labels that it gets from the teacher model which results in a distillation loss. And this lowers the competence for any extreme predictions and helps handle some of the noise that's generated. Uh so relating back to the adversarial examples that exploit those sharp decision boundaries. uh distillation makes those boundaries more flexible and it makes it harder for adversarial examples to push those inputs across that decision boundary. Uh so for this
example we could see a legitimate or on the left we could see a legitimate sample X and an adversary Xstar try to make a change to its input to mislead the model. uh making an adversarial example, right? The adversar's goal, as stated before, was to use the gradient with respect to the input image to find a point very close uh to the legitimate sample, but on the opposite side of that decision boundary, right? Which causes the model to make an incred the model to make an incorrect prediction. Uh but if we push that boundary further away from that legitimate sample, uh it's harder for that small change to cross that boundary. And that's what we see
happening on the right. Okay. So now let's go through the testing results that we saw when using our adversarial examples. So first to establish our baseline, we have the accuracies that our models achieved at the end of the summer internship, which just to reiterate were 97.18% for the face model and 96.10% for the voice model. Then after creating adversarial examples, we first tested how well our clean models could predict those um samples. And as you can see, it significantly decreased the performance of our models. The face model was less than 60% accurate and voice was less than 15, which to us was very um concerning when we first saw it. But fortunately, we had researched some
mitigations that we could apply to try and improve our performance. So we first incorporated adversarial examples into our training and then tested and that really improved the import performance of our models. Um the face model was able to get back to an 80.5% and the voice model to 72.27%. And then finally to further improve our accuracies we implemented defensive distillation and label smoothing and were able to achieve 90.0 04% for face and 76.67% for voice. The biggest takeaway of these results for us was that although the final accuracies were less than our initial models clean uh our initial clean models accuracies, we considered this better performance because we knew that our models were now more resilient to the adversarial
attacks that we'd been researching. And we also believe that it's a reflection that our original accuracies might have been inflated and our model wasn't actually as good as we had previously thought. Uh so now we're going to talk a little bit about our project outcomes. Um uh this was our first time ever implementing an adversarial thinking perspective as recent college graduates. Uh we learned how to better evaluate the resiliency of a design. uh identify BR or identify vulnerabilities and mitigate them. Uh red teaming the model helped us realize or highlight vulnerabilities related to you know biases overfitting underfitting uh data data collection, standardization and the training quality that might have otherwise gone unnoticed had we taken
the same approach that we used in school and other internships. Uh so integrating red team in or red teaming into our internship project uh better prepared us as future engineers to create more robust uh and secure machine learning solutions. Uh I'm not going to pretend like I'm the most uh I'm like I'm the best machine learning guy. I barely know anything about it. But uh just learning what we can do to make more secure solutions in the future uh really helped us out and I'm glad that practis gave us the opportunity to do that. So in conclusion, we believe that you all should start thinking and incorporating red teaming and adversarial thinking into your future
design processes, even if it's not specifically for cyber security or pen testing. Red tech red teaming significantly helps manage and mitigate risks from third parties or adversaries. And it strengthens the overall resiliency of your solutions. Everyone can benefit from incorporating red teaming into their design processes. And the earlier that it's introduced to young developers mindsets, the better because then they'll be applying adversarial thinking throughout their process rather than just treating it as an afterthought or maybe ignoring it altogether. So next time that you are planning an internship, software training, or any other sort of design process, you should incorporate red teaming into your process. So thanks again everyone for coming to our talk and if you have questions we'll
be up here or around the conference. [Applause] So how long did it take after you've gotten everything done? Um how much of a sample vocal do you need? So if you were to add authorized for what how long of a process is it for them to be added? Oh man. Uh like I said, these aren't these Arduinos aren't exactly like great at collecting samples. Uh for us as the face team um inferencing uh took so long uh like 10 seconds per picture and we had to get like 500 for each model. Uh so that's days days of just collecting data. Um I mean I guess that's the grind, right? But um I don't know if it
was any different for you was it? Um so for the voice team uh similar to face team it did take um quite a lot of time to collect all of our examples for our three authorized users we had over three hours I believe of audio um total so for each person and that was of course split into clips of 5-second length so that the model could like you know process it a bit easier but actually collecting those samples took even more than three hours. It took weeks when you consider um us fine-tuning our collection methods as well as cleaning those data samples because sometimes we would just mess up and our sample would be like useless
because we didn't actually speak during it or we like dropped the Arduino or something like that. So my question is if you were to add a fourth person you got all this training done adding a new person to the authorized list. Yeah. How would you need would you need three hours of one person's vocals to the authorized list? Uh the voice. Yes. Ideally, because our goal was to have balanced amounts of data for each authorized sample. So if we had like only one hour for a fourth person, the model would likely not equally recognize patterns for that fourth person because it had so much data for three other people compared to that one person. Uh
if that makes sense. Yeah. And for I mean face we did look at ways that we could collect data you know faster um mainly by taking pictures with like our laptops or something and then uh changing them or or compressing them or posterizing them to reduce the amount of color on that image so that it could be processed by the actual model on the Arduino. But uh I mean some of those also sort of breach into like okay like your your manufacturing data sort of and you want it to be taken with the actual model. So I mean there's like a sort of happy medium that you have to get when you're when you're doing that. Uh for us
uh the longer we did it and the more standardiz or the more standardization techniques that we used um collecting data wasn't as hard later in the process. So uh normally you wouldn't need like 300 samples maybe like 50 right to make the model work but we just want it to be more robust. So hope that answers your question. Go ahead. I have a few questions. first when you implemented um the distillation it have any negative side effects to the actual model. Uh yes actually. Um h [Music] the it kind of made it worse initially and then we had to go back and then start uh scaling some of the hyperparameters just to see okay can we
hit like a baseline like good quality or a good predict good prediction I guess. Um, it wasn't bad. It was actually made by the same guy that made uh FGSM, the distillation techniques. Uh, but getting it to rebound was actually pretty easy. It was just scaling a few hyperparameters. We added a few um uh regular or regularizers to the um one of the dense layers for the actual um model. So, uh getting it back to like working good wasn't like hard at all. And I guess also um when you were testing the defakes, did you notice anything else with the audio fakes? Like a malicious actor does overlay background noise by it. Did you guys do any facial
testing? Um so for the voice, yes, we did think about if they overlaid background noise. Um the red team didn't actually test it, but as the voice team when they were testing defects, we did think about that as an option. Um, but we um, like I said, the background noise was just one pattern that we were able to pick out as humans. But the benefit of using neural networks is that they often can find patterns that humans can't even recognize. And so, um, even when the red team started creating completely new deep fakes that we hadn't seen before. So I don't actually know all the defects that they used to test, but when they were testing new ones, our
model was able to pick them out pretty well. Even if they tried like incorporating new scenarios that they could think of because um our belief is that our neural network was picking out better patterns that than we even could. So yeah, and uh also to answer your question, a lot of um like this the tweaking that we did was just adjusting the temperature gradient that we would divide by the uh the predictions. So it was just figuring out like which one was good for that. Uh that's pretty much it. But after that distillation wasn't like too hard to start tweaking. But um and I don't believe that they tested AI deep fakes on the face model. Just
answer that second part.
Uh I wouldn't say so would you? Uh what do you mean by tools like? [Music] So for example, let's say we're using [Music]
Do you want to answer? Uh we deployed these using a software called Edge Impulse. Uh I believe it was made by Google once they brought TensorFlow in order to deploy a lot of their uh models onto machine or edge devices. um in terms of like spotting security vulnerabilities while we were coding uh it made the code for us and then after that we uh sort of modified the code to fit our use case a little bit better. Uh while you know security vulnerabilities while in the IDE or like identifying any of those we didn't really like do that. You have anything to say or add to that or Yeah. Yeah, I mean we did like um
extract the code later on when we were making the ad adversarial examples, but we also didn't do that during that part either.
So this project facial recog
I don't feel as
comfortable that I guess I guess it's developed to a higher standard than
Um, well, for the voice model, I definitely feel more mindful of like when I'm using my voice for any sort of software that like might be recording it or like when websites ask for permission for your microphone, things like that, I guess. or uh if they ask for audio clip to record. Um because now I know that you can use a pretty modest amount of real data to create AI versions of yourself. So that's one way that it changed my mindset. Uh for me, I mean uh both me and Mia work around people in a cleared space. uh and you know everyone's sort of conscious of not having their picture taken or like not having any like facial
data shared with any sort of one like site. So I mean just seeing that uh especially when trying to collect like random samples you no one was in the office and uh wanted to do that. So I mean just seeing why I guess uh for things like adversarial examples and uh how easy it is to implement that into any model. Um I guess it's sort of opened my eyes to uh why people are sort of guarded against just sharing image data of themselves. I I still use my face to unlock my phone though. So I'll tell you
what. Do you think you could use
uh I wouldn't say much more advanced. Um our solution was mainly just a lowcost solution. Uh no, before us I guess no one had really tried doing uh face identity recognition or uh any significant voice identity recognition on these like resource constrained edge devices. Uh it's not really something that a lot of people do. Um so like that was sort of our like uh like our pitch, right? was that we wanted to be able to get something close to an industry standard while also, you know, not breaking the bank. Uh, and would I say that it could be used in place of any of these like like Apple Face ID? Go ahead. Oh. Uh, would I say
that it could be used in place of any of that Apple Face ID or anything like that? No. Uh but for a very specific use case of like access control to maybe like a skiff door or something like that. Uh I think it could definitely be be implemented with like a few more years of development. But uh yeah I hope that answers your question and I can get you answered my question but I was asking why that's pretty big there. Is it or because and also no value because skip. Why that? Oh, we were interns. Yeah, we were we were broke, right? Uh yeah. No, we just wanted to honestly we just wanted to see if we could do it,
right? And that's sort of the fun of it all is being able to take, you know, like boogers and tape and make something really special out of it. But yeah, I think another big like emphasis for us was because it's supposed to be kind of designed for a cleared environment, we can't be relying on cloud which could be more susceptible to other, you know, adversarial threats. So having it be remote makes it more secure in that way. Yeah. Well, thank you so much. Thank you.
Related talks
 18:35
18:35 52:42
52:42 54:29
54:29 25:38
25:38 43:19
43:19 52:09
52:09