Is AI Ready For AML In DeFi? A Look Into Transaction-Level Risk Analysis
Show transcript [en]
All right. So, what a lovely c crowd we have here. So, just to clarify, so thank you for the introduction. Uh, so you guys might be wondering what's AML and DY. So, just let me clarify that AML means anti-moneyaundering and D5 means decentralized finance. that's in the web 3 ecosystem that's consist of all our cryptocurrency and all that stuff. So all right so who am I? I am Yosh Nimbar. I have just completed my cyber security from the University of Birmingham. Uh thank you. The topic that I'm going to discuss is uh one of the thesis that I have uh done during my masters. It's uh testing if uh the current money laundering uh uh like
current machine learning models can uh correctly and accurately predict u moneyaundering patterns or not. So I have worked as a software developer for 2 years uh at at FISV. I do bug bounty sometimes. I I am a learner and the thing that you see in the end moods cakes wishes that's just a cute little way of showing my location. Uh you can check that out later on. So that's the GitHub link uh of my thesis and the LinkedIn and all right let me start. So the decentralized exchange as we know the crypto world uh it's experiencing a huge spike in the number of amount of money that's going into the space but also we are exper uh experiencing a lot
of uh attacks or in the D5 world. So we can see that the largest attacks or crypto hacks that we have seen uh in the world yet that the humanity has seen came in the last 5 years. And you guys might be wondering how these people the attackers are moving the money to and fro. That's the money laundering part. So the question the need is that we need to stop these transactions happening before the money is transferred because if the money gets transferred then like decentralized is uh it's anonymous so we can't u find the person in the end. So the money launderers use various techniques as shown. Uh it consists of uh switching the chains uh then swapping
the tokens you they use mixers or tumblers as we uh say it's a kind of tool that they use for mixing the bad coins along with the valid ones. Along with that they use dusting like they uh send minute amount of money to each and every wallet and then they transfer the uh funds forward. These all will be a bit clear dusting uh in the next slide. They also use gambling platforms, centralized exchange, decentralized exchange uh privacy coins such as Monero and also NFTTS. This is just a small example of the Roninbridge hack and one was the bybit hack. This each node that you see is a wallet in the web 3 ecosystem and each
line is a transa sorry transaction. So it gets complex really fast. This is just a small snippet but uh it's more complicated than this. So my whole research was based on three questions. Uh are the current machine learning models effective? Is it viable if we put it in the production environment? And let's see how the realtime performance is. So uh what I did this is uh just a uh high level overview of like where my uh solution or where the machine learning model would come like the crypto wallet would initiate a transaction. The machine learning model or the tools that we have would check for the income uh transactions and its past history for that particular wallet
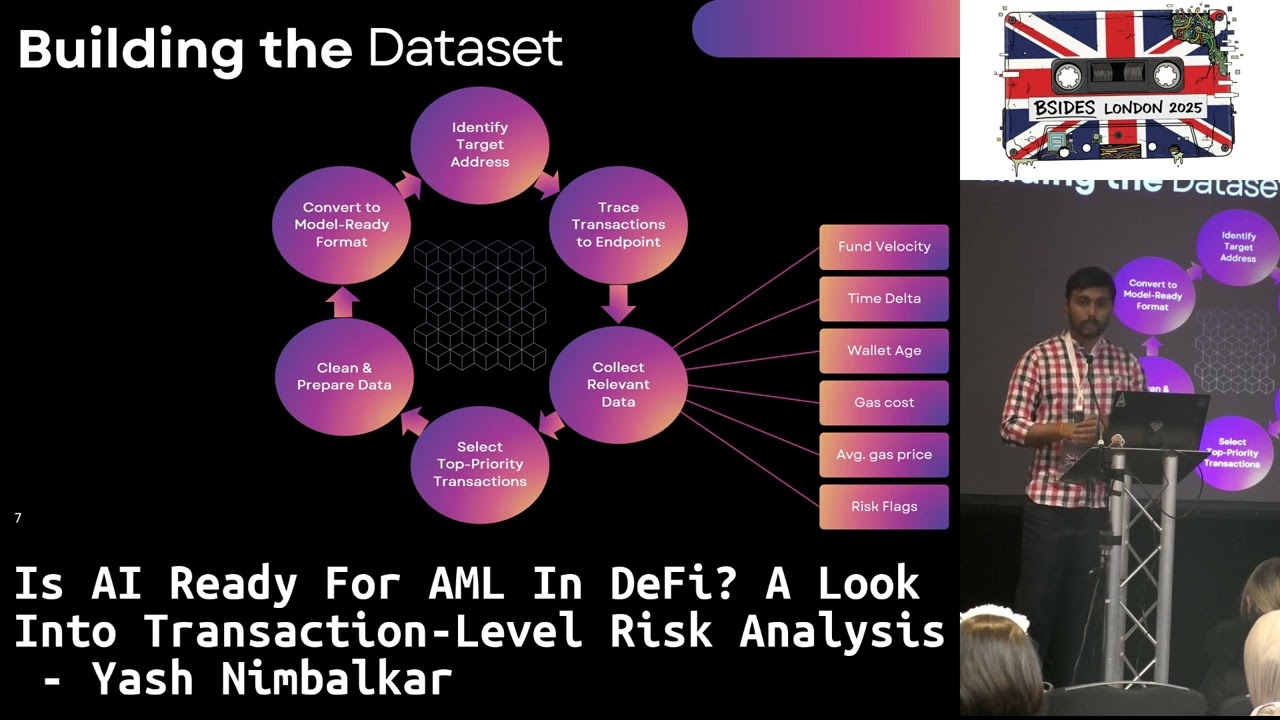
and if it follows a moneyaundering pattern the wallet then it would mark it as illicit and it would stop the transaction or else the transaction would get approved and the money would get transferred. This should be the ideal scenario. So let's see if that worked in my case. So first of all there was one big issue I I wanted to train the machine learning models but uh there was only one publicly available data set that I could find for that was by elliptic and that was for bitcoin back from 2019. So I had to build my own data set for training the models. So first of all I identified target addresses addresses such as attackers addresses centralized exchange
and other trusted and also illegal or illicit uh addresses. Then I traced the transactions to endpoints such as centralized exchange, decentralized exchange bridges mixers sanctioned address and non attackers wallets. This is because after we go from centralized exchange or bridges the money we can't like after mixers it's really hard to trace the money. So what I did I traced the money until that point just so we know the pattern. Then after collecting the traces I collected the relevant data such as the what uh by what speed the funds are being transferred the time between the fund transfer, how new is the wallet. Uh because whenever attackers transfer the funds, they use automated systems. They create new wallets in a snap. So if it's
a new wallet, if the funds are being transferred really fast, attackers want to transfer the money quickly. So they spend huge amounts of money on the gas cost and that's how I was able to collect the relevant data. Then I sorted the uh transactions in the from top to down like depending on the amount that was being transferred then as every machine uh learning model needs I cleaned prepared and converted that data so that I could train the models. So during my testing I tested a few machine learning models both traditional and graph based. uh traditionally included included random forest and the graph based ones were graph sage graph attention network and the graph isomorphism network.
So well after testing after all the training and testing was done these were the results that I found which were mostly expected from my end I would say uh we can clearly know that the traditional machine learning model like random forest won't be able to capture the intricate details of u the transaction patterns like as you you would have seen in here. So as you can see these are nodes and graphs. So basically the graph neural networks should have been should learn these patterns quite easily as compared to another model such as random forest and that's what I saw in the results as well. Okay, as you can see the GIN graph isomorphism network this model performed the most uh
in most of the scenarios um it gave better results than the other models and this is because these models graph neural networks learn relationships as compared to random forest. This is one of the key point that I was able to find and GIN is one of the advanced graph neural network model out there. Well, there can there are others in development like uh nowadays people do use hybrid models such as G and G jin. So, but that didn't work out as the way I thought. But it's all right then. Looking at the production viability, currently Ethereum processes around just the Ethereum blockchain, it processes around 1.5 million transactions every day as of August and out of that
only.14% are illicit. Like unless it's a big hack, the average number of illicit transactions are quite less. So the machine learning models that we use needs uh to have a precision of almost 99.99%. So that it would u clearly block only the illicit and not the legit transactions and thus it would not cause any collapse of the D5 economy. So but as you saw Jin gave an gave a precision of just 95%. And that would result in around 75,000 false positives a day and that would be a quite headache for the legit users. For the third research question, I wanted to look at the real-time performance and I was able to see for the pre-processing of the data and for the
whole all the models to give out the outputs. It took less than a second as you can see but it was the tracing step that varied like from 5 second to almost 500 second for each wallet. So that was the thing that uh was a major bottleneck for my uh testing and uh building the data set or like for the model to determine if it's a malicious or not. And so we can conclude from this part that the models are actually pretty fast and they are reliable uh not so reliable but in terms of speed but it's the tracing architecture that needs optimization. So for the future work what I wanted to suggest is that the data set needs to be
expanded. Like right now I do have almost 200 traces of u legit and illicit transactions uh consisting of around 60,000 wallets or something that's quite small. uh the data pipeline needs to be optimized like I can create a Ethereum node itself and the tracing would be much faster. Advanced model architecture needs to be developed for the graph neural networks and if there are any other models that can be achieve better accuracy and metrics than we saw right now. Humans can be added in the loop as well like uh uh machine learning there is a form called feedback learning as well. So humans can give the feedback if this is a a malicious transaction or not.
Adversarial robustness testing like nowadays adversaries are developing really complex ways to uh launder the money. So the machine learning models that we train need to be advanced enough to be able to detect these new techniques day by day. And my testing was uh only related or related to Ethereum. But uh we can extend this data set and the models to other blockchains as well. And that was it. So if you got any questions uh regarding this then I would be happy to answer. >> Yes ma'am. Thank you.
>> Blockchain right? Yes. So the only publicly available data set was from elliptic as I mentioned that was from 2019 at the that was for bitcoins. So that was quite uh um old I would say. So that was not what I needed. So I had to create my own data set. and >> question here. >> Well, there are other commercial commercially available companies as well. But uh these companies try and keep the data with themselves or they sell the data which uh unfortunately for me since it was my dissertation project I uh I did not buy that data but they do provide uh the data sets the com it's but the commercial
Well, for me, I test uh I looked at the other models uh available publicly like the companies uh which are which truly use these models but uh they they have it closed source and um I was unable to know what kind of model they are using. So
Mhm. Well, since it was a really small data set, like as I mentioned, it was just 200 traces of both listenit and illicit transactions. It was quite fast. I would say like 5 to 10 minutes of uh training on my own laptop but uh like the time uh as the data set would expand obviously the time to train would get increased. Yeah. Thank you. >> Yes. >> Thanks. Um really good presentation really interesting. um when you when you had the statistics um around attempting to block any transactions on the blockchain, I was wondering whether you would actually need to go that far. Like could you actually just target the ones that were going to an exchange when the
attack is trying to convert the money back into fiat um as opposed to going through the whole blockchain? Well, there are uh really there are some a few companies out there who do provide these kind of services uh like they do block transactions if they find if they are they are illicit or not. But uh since this was my own data set and my own finding uh I would say yes to your question there are a few companies and exchanges who partner with the other companies as well. So yeah there are solutions to this. Thank you so much. Another round of applause.
Related talks
 28:37
28:37 47:15
47:15 33:48
33:48 49:41
49:41 34:45
34:45 10:48
10:48