Bug Hunting with Static Code Analysis
Show transcript [en]
so I'm going to be here today talking about hunting for bugs with static code analysis so let's have a look at the problem why we're actually here what do we care about um software developers are human they make mistakes they screw up and there's been quite a lot of that lately over the last few years um you know we got a heart bled Shell Shock the ghost GB SE buug was pretty bad too um just to pick a few out of the air um and now that they've got nice fancy logos it makes nice and easy to make a presentation about them um but mistakes means bugs bugs mean vulnerabilities overall we want fewer bugs that's what
we're here for so who am I uh I'm Nick Jones I work for MWR info security as a security consultant most of my time spent on web application security or infrastructure assessments and but in a previous life I was a commercial software developer working with embedded systems so I've got a bit of an understanding of uh both sides of the coin there um and I've done some work developing bespoke static Canal analyzers for clients during that time as well so what we're going to be going over today um the problems of application security why we're actually here talking about it um Regular Expressions paes control flow graphs and then just a quick look into why you might be interested in these
tools and how you can best use them uh both as Bug Hunter security consultant or what have you uh and also from the point of view of software developers so to start off what's the problem here we're really looking at throughout the talk I'm going to refer to uh a company as a case study um m events who've been uh developing a new online events management platform and they've got a website they've got mobile apps they've got a backend that's someone built in some horrible embedded platform uh all in all it's a real mix of stuff and the developers are average quality not completely terrible but equally uh they're not particularly hot either uh they've got no in-house
security expertise uh and so they're Contracting out to try and find people to help them um so if they want to find and fix all their bugs where do we start um there's a few different methodologies and mindsets you can apply to this and broadly speaking they break down into two categories you have static analysis and dynamic analysis so static analysis is looking at an application without actually executing it you're reviewing the code or the binary uh or otherwise digging into what the application is built of without actually executing it on the platform it's designed to run on so this typically breaks down into sort of code review reverse engineering analysis of the binaries you get handed
so on and so forth and Dynamic analysis on the other hand is your more traditional penetration testing um you execute the application you interact with it as it's executing you try and find bugs that way so fuzzing and typical functional testing tampering that kind of thing all falls under Dynamic analysis given the talk title I'm sure it won't surprise people to find out we're going to be focusing on static analysis and for the most part we're going to be talking about code review um how to use static analysis techniques to analyze source code so how do we do code review you can either do it manually or you can build yourself a all to do it in
the manual sense you give it to some smart security people who understand how to look for bugs in source code um they read through it try and find some bugs um you know often you'll find quite a few that way and the other approach is to build yourself a tool uh pass your code into the Tool uh and let the tool understand and reason with the code in order to spot issues that it can understand so from a manual perspective um I'm sure a few of you have seen things like this crop up in Co before someone shout out what sort of bug are we looking at here yeah buffer overflow fantastic um so that's a nice easy one um you know
you got a couple of lines of code there it's immediately obvious when you read it um likewise if anyone's done any Android security they'll tell you that um setting javascripts enabled on your web views generally doesn't end terribly well so again single line nice and easy to spot your problem then becomes it's really expensive doing this on large Cod bases I've pulled some numbers off the internet for a few major projects um latest estimates for Windows and Mac coming at about 45 million lines of code 86 million lines of code respectively um the new F35 they reckon about 24 million lines of code overall um and paying a security consultancy to sit down and read through 86 million
lines of code to try and find bugs in it is a really expensive way of doing it um and to give you an idea of how many bugs that might be um Steve McConnell who wrote C complete says estimate 10 to 20 defects per thousand lines of code uh seems a little high to me but we'll go with that anyway which means Windows we're looking at about 6 700,000 bugs about 1.3 million for Mac OSX and our brand spanking new fighter is going to have somewhere between 3 and 400,000 and that's it's a lot of bugs so how do we cut that down without spending silly amounts of money on Security Consultants to do this um we use static code analysis
tools uh so essentially you build tool tooling to automatically search your code uh to try and find security issues uh that you can write rules essentially for um so you've got typically got a very high upfront cost uh you're either buying in a commercial tool the commercial tools get really expensive depending on the scale you're using them at um or you're developing something yourself and these tools are not trivial to develop which I guess is why the commercial Ones cost so much and so as a result and there's a fairly serious upfront cost to it but once you've built it it's enally free you've got to run it but the actual uh the cost to run it is pretty much
negligible um and you can catch a lot of the low hanging fruit automatically as we'll see later on so uh bit of a warning here um in order to get our heads around how a lot of these tools work there's going to have to be a bit of computer science theory apologies to those of you who've done compiler courses already equally apologies to those of you where I'm trying to fit I don't know two semesters worth of compiler Theory uh into about 15 minutes and this is going to move quite quite fast broadly speaking we're going to have to cover language types autometer and then how you build paes from autometer um so what is a language
um it's a set of strings of symbols of some description uh that are constrained by a set of rules rules are usually defined by grammar um so this can be SED for human languages just the same as it said can be can be saided for programming languages um and a BL called n Chomsky who some of you will probably have heard of uh came up with a a hierarchy of the different kind of constraints that apply to different types of languages um so we're mainly going to be focusing on the bottom two regular and context free that's where most programming languages fall into um so we're going to start off with regular languages first um taking a look at
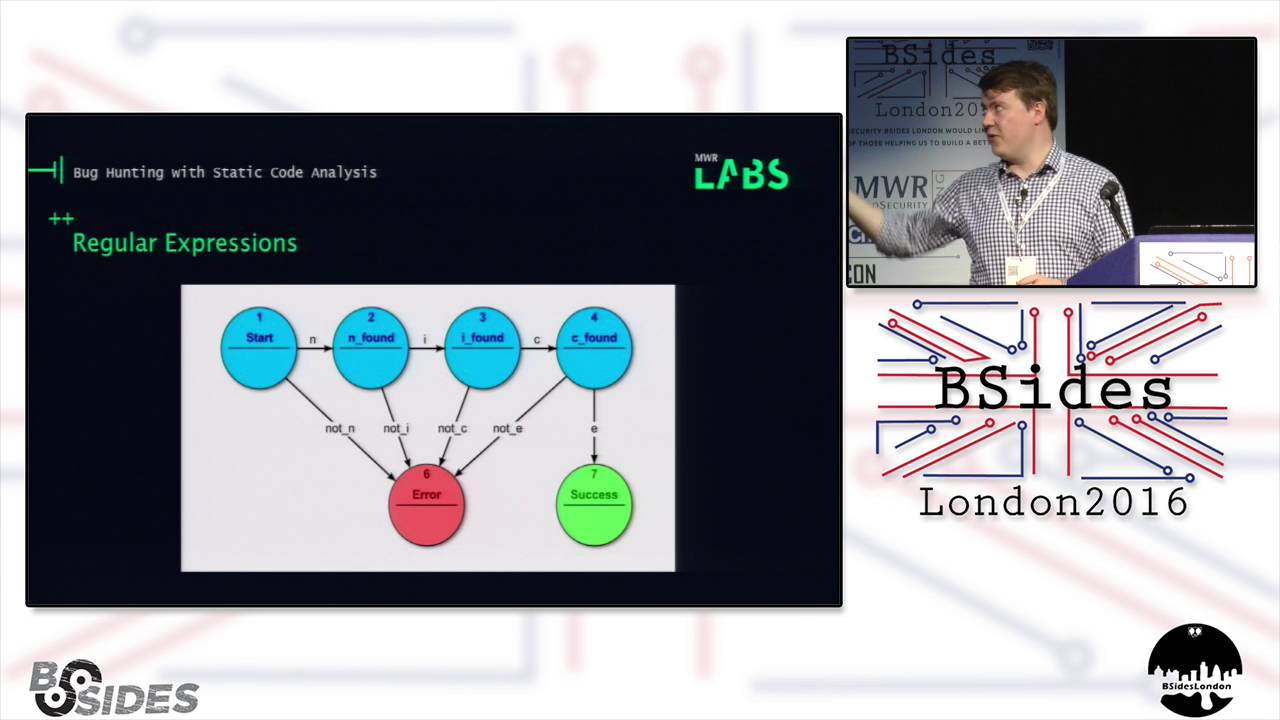
regular expressions in that context as well um so like I say regular languages um which can be paed by regular Expressions I'm sure most of you come across regular Expressions already um here we're talking about them in the classic sense rather than the modern R expression paes that you'll have used no doubt in uh a number of languages python Pearl what have you um the modern ones are generally a lot more powerful than the classic Model and can do things like backtracking but generally speaking uh the same kind of limitations that I'm going to be talking about here uh are a problem for them and so broadly speaking regular Expressions act as a finite autometer which is a finite State
machine um in simple terms if any of you have used those you have a list of states and a list of transitions that can be made between your States and you process your input till you either reach the end or you error out um so very basic regular expression paa looking for the word nice um so you have your starting character is it an N if so move on to state two if not you move out to your error state which here is six um you know and so on and so forth looping through until you either reach success or error um obviously if you start using wild cards and so on and so forth your
state machines get a bit more complicated but broadly speaking it boils down to the same thing so how do regular Expressions help us you can match code Snippets that look like problems you already aware of um and there's a few advantages to that uh especially in the context of regular Expressions they're very quick and easy to write comparatively low cost if you're a security consultant who wants to get a feel for how ropia codebase is or you're looking for the really really obvious bugs in some code this is probably where you start and basically boils down to does my c code match this very specific known issue that I understand and I've been able to write a
rule for so maybe someone's using some bad libraries so you can scan through and find any import statements for bad libraries calls to known dangerous functions if you know if you're you're looking through the code and there's calls to stru copy everywhere that's probably bad um and likewise known security misconfigurations uh so as we talked about earlier enabling job scripts on web views and Androids is bad so we write ourselves a regular expression that looks for uh set javascripts enabled calls uh and lo and behold when you run your Rex over your codebase you find this line so you know that's bad you can go fix it there's another example here um we've got some debug statements and they're
wrapped in a guard you've set a constant somewhere that states whether the the application is in debug mode or not uh and what you care about here is whether you're logging in a production environment now your Rex looking for print F statements which is what we're assuming uh is being used to log here um is going to quite happily find all three of those prfs so youve got a couple of problems here though regular Expressions can't count you have no way to maintain State classically they can't back Trace if you're using a modern reg expression they can to some degree or another um but the issue here then is if we go back to the previous code you've actually got
three issues turning up for what is essentially still one and it's actually not one because you've got uh it's a false positive because you've got your your debug guard in place um so in order to check to see whether the developers remembered to put the guard in place you've got a couple of different options um you can check backwards line by line through your code file until you reach either the beginning of the line or the appropriate statement um which is inefficient and prone to false negatives because sometimes you'll catch guards uh that might not actually necessarily apply to what you're looking at um or you check the X many previous lines you know you
pick an arbitary number five lines 10 lines what have you um but that will tend to lead you into uh a good good number of false positives because you're only checking so far um and as I said you gener generating three alerts for the same missing God so the fundamental problem here is regular expressions are not designed for pausing programming languages regular Expressions mostly only match regular languages most programming languages are context free so the next one up the hierarchy uh in chomsky's language hierarchy um and so instead of regular Expressions we use pauses so context free languages are a superet of regular languages as I said um and they're defined as anything that can be
accepted by push down autometer which is a little bit like finite autometer as we discussed previously only this time around you have a stack which means that you can decide your transitions within your state machine both based on the input and also whatever it is that you last popped onto the stack and you can push and pop to the stack as you need um kind of a a brief idea of of how these work you're reading in some characters off an input tape you have a stack both of those inputs together decide where you're moving next within your finite State machine so how does this then apply to a paa paas are generally an implementation
as a push down autometer in some form or another um and you convert text in the form of human readable source code uh into some kind of hierarchical data structure usually either a PA tree or an abstract syntax tree um the basic difference there is a PA tree contains every single token uh so you'll include brackets and so on and so forth whereas an abstract syntax tree mely uh purely holds on to uh the information that is important to actually build the program um several different types of paers um I'm not really going to go into the detail there um it's not terribly relevant for for this um the one thing to say though is that most PES operate
in two separate stages so you have something that chops your input up into uh the tokens um or strings with an understood meaning so you know your your keywords in your language or your um your braces or your variables or what have you um and then once you've finished Lexing your input uh you then run a paer over it in order to construct your your tree of some description um you can combine both it's not usually done for programming languages um so as an example um we're going to run Alexa over the uh dbug guard example I used previously uh and you can see there the leex has picked up different types of keyword words function calls uh
variables and so on and so forth um and so then once you've Lex it successfully you can pass it into your paa and the paer here starts reading from the top discovers it's got an F statement so you create an F block next up you find yourself uh an open curly brace which means you now know that you're starting a new code block so from there all of your printest statements are then attached to that code block which is then closed off once you then find that final bracket now the real power here is that you understand the position of your printf statements within the code so you can check back up the tree rather than
reading line by line without really understanding the context a this is a lot faster because if you're searching back up uh the tree of source code uh that's an awful lot faster than reading back through a thousand line text file um but B it provides the opportunity for far fewer false positives because you have a much greater understanding of context so now that we've built an abstract synex tree what do we do from there you've got a few options really um at a basic level you can search it for dodgy function calls um DB guards as we mentioned previously that that kind of thing is quite easy to do um checking for questional inputs um works the same
as in regular Expressions but there are a few other advantages here and a you've got fewer false positive as I mentioned the other thing is it stops you accidentally paing comments that kind of thing um generally makes things a bit nicer um but where this becomes really powerful you know that's fairly basic functionality is then when you start looking at control flow graphs and taint analysis so let's take a look at control flow graphs what is a control flow graph it's a representation using graph notation of the paths that might be traversed through the program at any point um so you build essentially a representation of the possible execution paths that can be taken um each basic
block is used as a node and we're defining a basic block here as something with a jump Target at the start and a jump at the end um so in the context of an if statement for example if you look at a over on the left there we have an if else Branch at the top which then takes two different paths depending on the uh the variable you input uh and then ends up at the same point at the end of it as you would expect an IFL statement to um in the context of B here what we've actually got is a while loop or similar uh you've got some kind of loop variable that has it iterate
between the top and second node repeatedly and then when you reach your uh your end condition you then jump out to the the third node highlighted um in the case of C similar um only this time around what we've got actually is a a brake clause in your wall Loop or what have you uh that allows you to jump out to your end condition uh at a different point to the initially specified end condition when you started the loop um and finally D is where someone's decided to get fancy and there's a two entry points into the loop um because someone's thrown a goto in uh somewhere up in the top block um so that
unfortunately uh is something we see on a fairly regular basis there's still plenty of go-to kicking about um so but why should I care about these what can we do with this and the big really powerful thing here is it allows you to trace the execution without running the application um so you can use this in the context of um disassembled malware binaries if you're not happy running malware funly enough um then that's quite a powerful tool there um but also in the context of trying to find SQL injection cross-site scripting buffer overflows uh these kind of vulnerabilities uh you can use it to trace the endpoint of data back to where it originally came from um which we'll
see in a second uh the real yes so the powerful thing here really is that if the data was sanitized several function calls ago back in another source file you can trace your way back up the control flow graph in order to find whether the data was sanitized or not between the user inputting it and actually being used in the application uh and that's really quite powerful so as an example here I've just thrown some PHP up on the board um we've got a login function of some sort that decides whether a user is logged in or not um that then calls a query function the query takes some input uh and Returns the result of the
query so your analyzer pauses the code scans right the way through uh discovers there's this mysqli query statement kicking around down the bottom um at first glance that looks pretty bad uh you know you've got variables just being plunked straight into an SQL query without any kind of filtering um but because the analyzer hasn't got the context at this point uh it doesn't immediately flug it so what it does uh it says okay so what function am I in uh you know this function login query has been called uh and we can see that as part of that function call the the two variables that we're passing now into the uh the query statement have been
passed in there so what you then do is look for where that function was called we know that was up here um so from there you can see okay so again this username and password's been passed in um where's that come from that's come from the original function called here um again username and password being passed in and that came from here and at this point the analyzer understands that uh dollor poost variables are coming in from uh the user there's no filtering going on that's just straight in from uh from the web server and so at that point your analyzer can flag there's been no sanitization this is probably an SQL injection Vector uh so you know you
should go do something about it we'll flag this now um so if you just run a Rex over it and looked for query strings where you just passing those in in this context you'd have found it and that's great but equally uh I've seen plenty of code where people sanitize user input as soon as they get it and then pass it in down uh at a later point which point your your regular expression scanning is just going to find I'll look at all these SQL statements uh you know you find 150 in a web application and 149 of them are actually protected um but who wants to sit down and read through 149 false positives right
so they have some downsides as I said before higher upfront cost to develop they are significantly more computationally intensive and the research that uh led to me doing this presentation came from a client project that we did where we moved from from some fairly simple grep bash scripts over to a static analyzer uh and it went from about a 30C run time on this code base up to about 20 minutes um mainly because I wrote it in Python obviously not the most efficient languages but um it gives you an idea of the kind of computational overhead that these bring to the table so the thing to note though is despite these being awesome you can do some
amazing things with them they do all still fit into the bigger picture you can't just run static analys tools and expect them to solve all of your problems either as a developer or as a a security consultant um you know they need to fit in with the traditional manual code review fuzzing functional testing and all the other kinds of assessment techniques that are already used it's just another tool in Your Arsenal but having said that how how are these tools most beneficial to you depending on your on your use case so let's start with bug Hunters I'm going to Define bug Hunters here as Security Consultants people doing bug bounties with got access to the source
code people looking for zero do to sell to the Chinese uh whatever it is that they uh they want to be doing but not people working on building the software in the first place um and then developers being people who build software who care about their security so as a Bug Hunter why do you care there's a few quite useful use cases for uh for these tools um the three I'm going to highlight here are Target identification finding your projects go after in the first place finding a few low hanging fruit once you get there but also let's say there aren't any low hanging fruit it's probably going to give you an idea of where the ropey parts within a codebase
are so to start with we're going to download source for a bunch of projects that have got uh got bounties out um and we're going to pick an analyzer and run the analyzer across all of them so in this case I picked floorfinder which is a paa that does some basically really dumb Rex style scanning um essentially only uses the PA in order to make sure that it's not reading comments uh or the junk it's purely reading the actual source code um and I ran this across four different SSL libraries embed TLS is uh polar ssl's new name in case anyone wasn't aware of that but you can see from that quite quickly that open
SSL would make by far the most sense to go after given that it's got half as many alerts again as any of the other libraries um there's a reason that people are finding heart bleed and things in it and it's been spun off as Libra SSL so the kind of stuff that floorfinder gives you back uh is a report that looks like this so we found uh PKS pkcs1 11. C uh online 871 is using string copy um and that and of itself uh you know maybe that's not that important because they've already checked sizes of what they're string copying but generally speaking uh not good you should probably be using one of the safer functions um so you'll find if
you run floorfinder across one of these uh a big long list of all of these kinds of things um and so that gives you an idea of where you might want to start looking um it's also really good for picking up a lot of the the lower hanging fruits and actually some slightly more complex bugs too um we talked already about using Tain analysis essentially to look for your data syns and then tracing back up your control flow graph in order to understand where that data has come from um that's quite powerful for spotting a lot of the classic uh user input type uh attack vectors um but moving on from that actually you've also got use after free
detection to some degree uh as a result of having this control flow graph um you can track pointer allocation and deallocation as you go through the application you can look at all the different execution paths because you know that because you built your control flow graph um and you can use that by keeping track in order to detect whether someone is referencing a pointer after it's already been deallocated uh likewise you can use that to check for things like um double freeing of memory so on and so forth and because you have that context and you have this understanding of how the data has flowed through the application so to give you some examples of some tools that you might find useful
for doing some of this stuff flawfinder as I Illustrated previously good for cc++ grit stands for great rough audit um and has a bunch of signatures for a few different programming languages um that tends to generate a lot of noise and a lot of false positives but if you're looking for Target identific ification or trying to work out which areas of the code base are particularly ropey that's quite a nice place to start um if you're using Java you might have come across fine bugs previously fine security bugs does I think it's 80 different classes of bugs uh for Java web applications mainly um and that will catch a lot of the low hanging fruit or minor issues like um
incorrect cookie flags being set you're not setting hsts headers uh that kind of thing along with uh the sort of the SQL injection and other user input related bugs that I mentioned previously um Ratz is quite hard to find a copy of these days it turns out but uh most of that's now been built into a commercial tool called fortify uh but that covers a number of different bug classes for a few different languages um rips works really quite nicely on PHP uh there's two versions of it now it used to be open source is now an open source in the commercial the commercial does a lot more of the uh the in-depth control photograph analysis and so on than the
than the open source one but the Open Source One will still catch quite a lot um and if you're using uh rubian rails then Brak man's also quite nice if you're going to do what I did he says with his clicker not working uh and build your own then there's a few options for that as well um so the analyzer built into clang is really quite powerful as is and will do a lot of um cc++ static analysis for you simply when you build the uh build your source code with it but also because of the way cling works and the way it's been nicely separ separated out into different chunks of libraries you can actually use clangs front end uh
syntax paa and so on to build an analyzer off the back of the abstract syntax trade builds um there's quite a lot of uh quite steep learning curve there um but clang is really really powerful so if you're looking at anything clang supports and you want it to build your own that' be one of the places I'd recommend starting if you want something quick and dirty uh and you're familiar with python um then there's a library called ply uh and a variety of different libraries that build on top of that ply J for Java for example which was what I ended up using um which will allow you to create abstract syntax trees out of inputed
source code um it's pretty slow like I say Python's not the fastest of languages in any case uh and ply has not been terribly well optimized um but there's a quick and dirty starting point while you're trying to get your head around how a lot of this stuff works that's not a bad place to go um ping likewise operates in a similar fashion to apply um then you get on to some of the more uh academically inclined or um grammar Focus tools such as antler and Coco um so they require you to define a grammar for your language um helpfully for a lot of the major languages people have already defined grammars and posted on the internet but you can then use
that to generate uh code for Java or python or C uh I think there's a couple of others they support uh which allow you to autogenerate most of the craft for paing your language and you can then add in your own functions for okay I've come across a variable what do I do with it I've come across an if statement what do I do with with that um which you can then build on in order to build your own your own analyzer so now if I'm a software developer what might I be interested in here um the big one really is how early on you can catch bugs with static analysis versus waiting for the
traditional pen testing cycle to come around towards the end of the application's release um the earlier on you catch a buggin the development life cycle the cheaper it tends to get um and you can build these tools in as part of your existing tool chain or uh other tool sets you're using uh in order to make it as easy as possible for your developer to use it um and if you've got a large development team you can have one or two experienced developers or people who understand the security implications of some of these bugs build your tooling for it uh and then hand it off to everyone so that you've got the same level of static analysis uh
checking being done both by your 20-year veterans and the interns you've hired in for the summer um so one of the places this is really powerful is in the context of continuous integration um so some of you will no doubt I've seen the the buzzword being thrown around essentially the idea is every time someone checks code into the central repository you compile it or interpret it run the tests across test Suite across it um and then there's a report as to whether your build failed or succeeded and then whether the test weite did likewise um which means that every time someone pushes new code to the repository uh it gets checked for bugs in a fashion that everyone can keep
track of and so you've probably seen some of the tooling that's been used for this kicking about um Jenkins and Hudson are two of the major ones you've got some commercial offerings from Microsoft and uh alassian uh and Travis is also fairly big um incidentally if you're ever on a network pentest and you find one of these running uh they're usually a gold mine for remote command and code execution um Jenkins for instance by default has no default credentials and you can upload your own build scripts and just hand it A bash script for it to go run on the server uh so that's quite good fun but broadly speaking the the workflow that most CIS follow is
developer checks in code to the central repository uh server compiles interpret Etc test sues are automatically run as part of that and so we bolt our static analyzer in there um and so most of the tooling this is Jenkins but most of them will provide you a nice little graph that shows whether you're passing or failing and how how much you're passing and failing and so on um but catching introduces issues as their introduced to the code base uh is so so much better than catching them right at the end you it costs you so much less you have the developer who developed it there and then he sees it as his mind is in the in the set of that
code he understands it instead of having to come back six months later and go what was this Pearl I wrote I can't read it um and catching regressions in code before they hit production as people introduce bug fixes is really quite powerful too they got a case study we'll talk about that in a second um but also the fact that it runs automatically with no developer input required beyond their usual checking coding means that that people can't escape the tests there's no oh I forgot to run the static analyzer that time around and oh look these bugs slip through the net um it all happens automatically and so as an example of where it would have been really useful
for someone Marks and Spencers had a fairly major data breach back in October 2015 uh where as part of a bug fix or feature enhancement or whatever uh a developer managed to make it so that when you logged into M&S you were presented with someone else's user details including partial credit card numbers um so it took him about 2 or 3 hours to find and fix that meanwhile it was up on the live site um whereas if you'd had a decent set of test Suites as part of your continuous integration uh you know you could have caught that by using appropriate test data um static analysis wouldn't have been particularly useful in that that particular bug
example but it shows where that kind of automated testing uh from a security perspective makes an awful lot of sense um if you're a developer and you're short on time like a lot of developers are um you might be better off buying in a commercial static analysis tool um so there's a few examples up here I've pulled up um veric code coity fortifi check marks Clockwork you've probably seen a few of these names kicking about at security conferences and things especially if any of you were unfortunate enough to take a trip to infosec um these tend to be very powerful once they're built right they require an awful lot of tuning of the rule sets
writing your own custom rules and so on and so forth in order to tune down the amount of false positives they generate um it's well worth taking the time to do that if you've got a large code based on a large number of developers but that plus the the initial licensing cost uh can make for quite a steep budget um here I've just pulled a screenshot of City off the off the internet to give you an idea of uh roughly roughly how they look and how they work so this has been run across a large code base you can see there's a big long list of issues up the top and while I'm sure you
can't read that it says that it's found a buffer overflow um because someone's not been checking sizes of data being passed in correctly um so a few places where us as Security Consultants I'm sure I'm not the only security consultant in this audience might be able to help uh some of their clients um in several ways but the the obvious four that came to mind while I was writing this um identifying where the security risks are likely to lie in any given code base um whatever your application uh you've got situations where the code is likely to be more security critical than others let's say you're writing an Android app the masses of UI GFF that Android requires you to
generate is probably not going to cause much of a security risk whereas your uh root detection say if you've got a fancy app going on uh might be a little more uh a little more important um so understanding where the key points of your code are helps you to tune the rule set to focus down on the really important parts um some Security consultancies will offer services for writing custom rules for existing static analysis engines and what I talked about previously with commercial tooling requiring a lot of uh tuning and additional rule writing in order to get the most out of it um you know hiring someone else in to do that for you might
make sense um in the extreme cases where you've got particularly unusual uh either environments and libraries or programming languages being used it might make sense to be developing bespoke tools as we did um but that's a pretty expensive oper uh option for for most use cases um and finally advising on how you can integrate all of this tooling best into a development life cycle depending on the client's own um environment and need needs uh is also a place I think security consultancies can add a lot of value um so conclusions what have we covered um so static analysis overall can provide a lot of lowcost security checking for comparatively little effort for developers um and as a security
consultant will allow you to find some classes of bugs quite quickly uh as soon as you sit down at your uh at your engagement um or if you're bounty hunting might help you both work out what targets go after and also um where to look once you get there um if you are going to go down the static analysis route especially if you're looking at building your own tooling um while regular Expressions uh and a few quick bash grips running GP over things will catch some stuff really um being able to build abstract syntax trees and then control flow graphs off that gives you so much power to do all kinds of analysis of the application um that it
really is worth looking into doing that if you can um and at the end of the day all of these automated analysis techniques do complement traditional manual assessments you're not going to be replacing pent testers with this anytime soon unfortunately so thank you for listening um if anyone's got any questions there is a man at the back with a mic so if you could stick your hands up he'll come around to you with a microphone and we can get started
Related talks
 28:37
28:37 47:15
47:15 33:48
33:48 49:41
49:41 10:48
10:48 50:57
50:57