Screaming About Detection Coverage in ALLCAPS
Show original YouTube description
Show transcript [en]
Hey, thanks everyone for joining. Hope you're enjoying the conference so far. Uh, I'm going to be presenting my talk here, screaming about detection coverage in all caps. I know we're running a little bit late, so I'll try to go through it a bit quicker. I'm Evan. I work here in Philly at a company called Security Risk Advisors, where I focus on uh, Purple Team Projects as well as green field research initiatives. Today we're going to be talking about detection coverage and and security tool coverage for our attack techniques and whether or not our tools are functioning as expected for these attack techniques and and how we can go about evaluating the efficacy of these tools.
I just want to state upfront uh this is presented from a purple team's approach to testing uh where essentially we're doing a very collaborative approach to our testing. Our attackers are working with our blue teamers in a sideby-side way. They're explaining the attacks they're doing, what systems they're impacting, uh any relevant details to the attack, and then they're working with the blue team to look through the security tools to see what the impact that attack had, if it was blocked or detected, if it was logged, uh and capture as much detail as possible that that we can use it later to prioritize remediation efforts as well as uh track this over time. As you can imagine, with this type of
approach, the question you're often going to be asking yourself is whether or not our tool blocked or detected that attack technique. Um, but more specifically, we want to understand, did it actually block the attack technique itself or something related to the attack technique, maybe some source of conflation. Um, so we do a lot of these purple team projects for our clients and as you can imagine, we've seen all manner of blocking and detection criteria and implementations and some of them aren't that great. Uh, they use very uh naive approaches to how they develop the kind of things they're going to trigger off of. Some examples of this would be if you have like a block and detect looking
for exact command line strings or specific arguments uh that are present in it or very highly specific implementation uh details of an particular attack tool. And so we'll have conversations with folks where we say basically that their detection doesn't count because it's not robust enough to uh survive any type of modification to the way you conduct the attack. So, we created this tool called All Caps, uh, which is what I'm going to be talking about here today to help us have these conversations and show kind of the the issues that arise from these bad detection criteria and help us focus more on the attack behaviors with these attack techniques. As we do our testing, the way we
approach our testing is an atomic method where we're looking to test one individual attack technique in isolation. And the reason we do this is because we want to isolate that particular attack for when we're evaluating our security tools to see did they detect that thing rather than something related to it. See we want to minimize the amount that any other related behavior have on determining the outcome so that we can get a true picture of what our security tools do for these attack behaviors. Uh, another nice benefit of atomic testing is that because they're very isolated, they're very quick, they have minimal dependencies, we can get a very uh, wide breath of techniques in a given testing
window, as well as a lot of variations for any particular attack technique. Some approaches to atomic testing that you might see uh, are things like atomic red team, which is a library of atomic tests you can run for a wide variety of attack techniques. You might see commercial baz uh, platforms. This is breach and attack simulation. Essentially an automated attack for platform for you. Uh our approach is somewhere in the middle of like custom tooling and a fully manual approach. We feel doing it manually uh is the gives us the highest quality results in evaluating the security tools. Uh but regardless of the approach that you're looking at, one common thread among them is the reliance on native system
utilities. If you're in the Windows world, these would be things like lens. These are uh binaries or utilities built into the operating system that allow you to achieve an attack technique without much uh effort. Um so they implement a lot of the functionality for you. It's just a matter of providing the right arguments. But we wanted to move away from that. So we developed all caps um to focus on the idea of a capability. And so a capability is the minimal code required to achieve some attack technique. And we package it up with some metadata. And then we use this all caps tool to generate payloads using those capabilities. And the payloads can be in
any format of our choice, an executable, a DLL, or an object file if we're using a command control uh framework, but they help us isolate these attack behaviors as individual payloads. We get the most minimal amount of execution required to achieve our attacks. Um, and so they help with this atomic test and they help minimize the impact that other uh related behaviors can have on determining outcomes. So I'm going to go through an example to show off the the functionality before I get into some of the more detailed pieces. Uh I'm going to walk through registry credential dumping and I'm going to use this as a common theme throughout this talk. Um so essentially if we want to dump credentials from the
registry, if we want to implement functionality similar to if we were to have run uh reg save and target one of the registry hives. The way we do this was all caps. First we'd have our code that implements the dumping functionality. This is basically all that's required. It's a few lines. They all call the Windows APIs for interacting with the registry. You open the registry, you save it, and then you close it. And that's it. The next piece, I know this is a bit small, hard to see, so I'll just explain it. This is the configuration that's required to define our payload. And it's essentially just a list of all the capabilities we want to run. If we're
interacting with the registry, we need to enable backup privilege on our token so that we can actually dump it. And then the next two are just dumping the registry. That piece I just showed you, uh, we do it twice. One for the system, one for the SAM because we need that to decode the SAM offline. Um, but what's nice about this approach where we're taking a capability based approach to building our payloads is that it's highly composable. We can reuse these and mix and match them for any other future payloads we might need. So, for example, if we're implementing an Elsass dumper, we'd need to enable debug privileges on our token. So, we can just
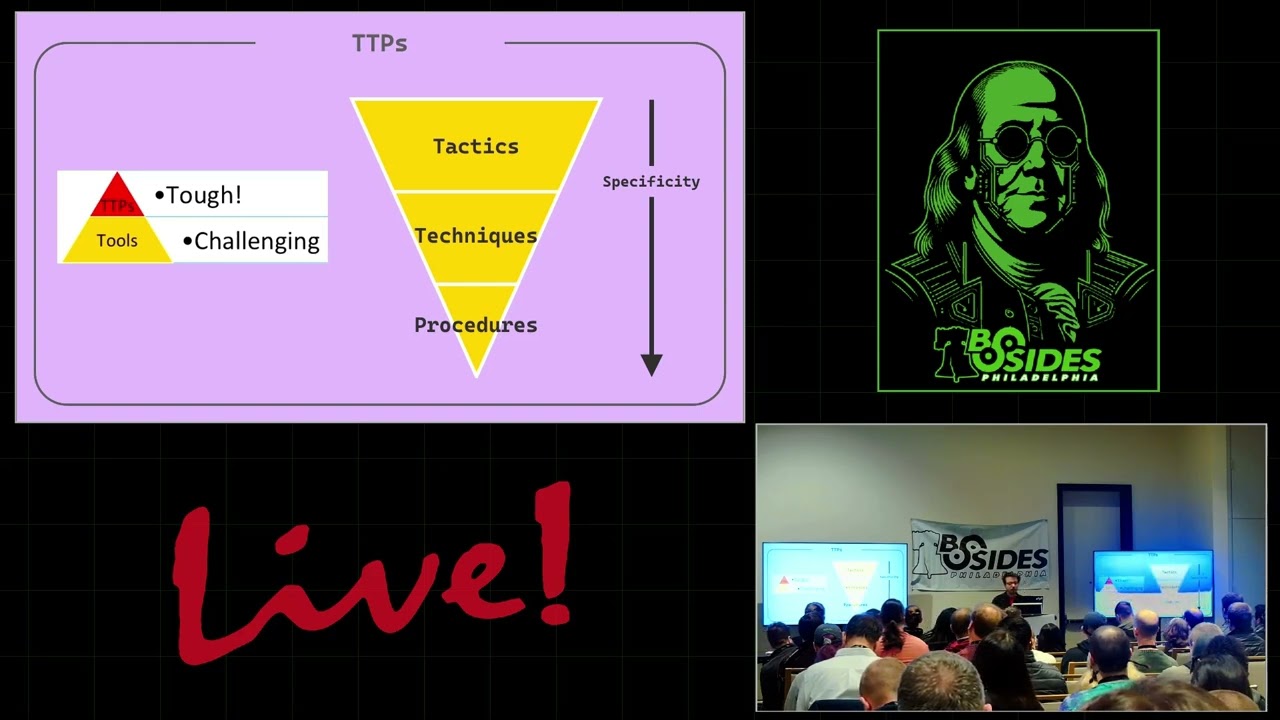
reuse this enable privilege capability and then add the additional pieces. We don't have to redevelop it every time. The other nice thing is obviously if you want to implement any type of evasion, you can add this in as well as a capability and then reuse it across all of your different uh needs. So lastly, you run your payload and you get output like this where we have our dumped registry on disk. And so we've approximately achieved what reggg save does. I've mentioned attack behaviors a few times. I want to dig into that. I'm sure a lot of you have seen this. This is the pyramid of pain. It helps you visualize the difficulty in detecting different
pieces of an attack. Starting with the basic stuff at the bottom like hashes and then moving all the way up to the top where we have TTPs. Uh but realistically the these bottom pieces don't matter that much. They're the less interesting things. We leave this to our thread intelligence tools. We leave this to our security tools because they're the low hanging fruit static indicators. We really care about the TTPs and the tools primarily. TTPs here being tactics, techniques, and procedures where we get more specific as we go down each rung. MITER defines tactics as kind of the broad why of what an attack is trying to do. Things like accessing credentials or evading security controls. Then we get a little bit more
specific into our attack techniques which are the way we achieve these goals. So if we're dumping uh credentials, the way we might do it would be say dumping from the registry, dumping from LSAs and then we get into the highly specific piece the procedures which are the concrete ways that we achieve these attack techniques. So if we're dumping from the registry or from LSAs we our procedure would be to use a tool to do so something like mimikats the procedure is doing that tool with the appropriate command attack behaviors exists somewhere in the middle between uh these techniques and procedures. So looking at our registry credial dumping example our tactic is we're trying to access credentials the
way we do so is by dumping from the registry and our procedure is using regave to do so. Um our attack behavior in this case would be something like opening the registry and then dumping the keys. These aren't really formally defined in any way like you would have say for miter attack. Um so this is just an example but essentially the behavior piece is kind of the abstract way we achieve an attack technique. This is important because ideally when we're building our blocks and the texts, what we want to do is focus on this behavior piece as closely as possible rather than implementation specific details because this helps us achieve economies of scale when we're building
our our block in the text. If we can focus things at the behavior level instead of implementation specific pieces, then we get wide coverage uh for any new implementation as well as all the other existing implementations. And so all caps helps us focus on these by focusing on the behavior piece. Uh as a side note, if you're interested in this type of uh methodology for like assessing detections, uh breaking down TTPs, I'd recommend taking a look at this summiting the pyramid project by MITER's Center for Threat Informed Defense. Uh it defines a lot of this and has a lot of good research involved with it. The other thing I'm going to talk about here are the implementations, the tools
we use to achieve these attack techniques. Again, going with our registry credential dumping example, the tools you might use to dump the registry would be something like reggg.exe we which we've talked about. Uh Miniats has an Elsas dump module. Uh there's things like secrets dump which exists in impact which you can run both locally and remotely. And then any other custom tools and there's probably a billion other commodity tools that all dump from the registry. Uh and because of how prolific these attack tools are for achieving these attack techniques, you get detections like this. I know it's a bit hard to see, but basically they focus on the very highly specific implementation details. They focus on
specific command line strings associated with running a command. They focus on say the registry path in the command line. They focus on specific mimikat strings in the command line or like output file conventions like you're using hive in the extension, right? These aren't great. Uh and the reason they aren't great is because bad detections like these are not free. They come at a cost. Uh the cost being that we need to dedicate engineering resource to implement them. we need to uh consume processing power when we're running these on our search heads. Uh if we have a really inefficient query running, it's going to prevent us from running other queries uh that are more efficient uh
more robust. But more importantly, it creates a false sense of security. If we think that we have coverage for an attack technique because we're using a bad detection, we're less likely to uh devote more engineering resources to improving our detection coverage, our blocking coverage for those attack techniques. And this is especially important if you're not doing any type of formalized testing of your security controls because you're not necessarily going to know that.
So we're going to take a look at this robustness piece uh through the lens of processbased detections. So essentially if you have some type of you know process create telemetry some common failure modes you might run into are things like the order of the arguments. A lot of commands don't really care how you supply arguments to them. You can give it in any arbitrary order. Uh some do, some don't, but it's tool dependent, but for the most part, they don't. So providing one argument first versus another first doesn't really matter to the command. They're functionally equivalent. However, when we're building our detections based on these process events, if we use something like the bottom where we're
using a wild card between arguments, we're uh forcing a strict order of the arguments. So our one detection isn't going to necessarily coverage all the variations of how these arguments are specified. So we need to break it up. Another failure mode would be when you're using uh process events is how you get the process name from the event because it can show up multiple different ways in a single piece of telemetry for a process. For example, you'd have something like the image name which is typically pulled from the internal metadata of a process where you have versus something like the file name which is how it appears on disk versus the command line which is the full
command line string. You can obviously pull the command out of the command line string, but this runs into issues with things like if you were to rename your your process from say net.exe to something else, then it's no longer going to match on a file name base match in your process detection. Another thing is if you have equivalent commands like net versus net one, uh you need to have coverage across all the different variations you might expect. It's also not necessarily reliable either because an attacker has influence over some of these fields within a process event. Uh the image field is uh tamperable by the attacker because they control the PB of the process and things
like the command line are spoofable. An attacker can control the command line arguments to make them appear as something else. This is even built into many commercial command and control platforms. So there's not really a barrier to even achieving that. Uh the last failure mode is how you supply these arguments. Uh some of these native binaries provide you alternative ways to specify arguments. uh you're typically prefixing them with a forward slash, but it that may not be the case. You can accept things like a for attack instead of the forward slash. So when you're building your process based detections, you need to be mindful of how uh you can supply the arguments. Additionally, some arguments might be
provided as short versus long form. So you'd have to account for both variations of that. And also they may be optional. It's common to see, you know, uh repeated attack or command line arguments for attacks if you're looking through threat intelligence. But because they're in that command doesn't necessarily mean they're required. So you need to be mindful of optional arguments that are maybe implicitly uh defined and accepted by the argument but maybe explicitly provided by an attacker. If you're interested in digging deeper into this robustness piece, I recommend this conference talk by Daniel Bohan and Matt Dunmoody. Uh it's called Signatures Are Dead. It digs into a lot of the opuscation piece. Daniel Bhanan is the
the person that developed invoke obfuscation if you're not aware. Um but more importantly, uh wherever possible, we want to address our detections at a lower level. Um essentially it is especially important if we're dealing with any type of system event. Uh we want to use the telemetry from that system something like the registry the file system schedule test what have you wherever possible rather than the process events because again they're not robust. So if we're doing registry credential dumping we have a lot of ways to avail oursel of registry telemetry. Uh one being if you're using something like sysmon it has a dedicated registry event for registry auditing. If you're using the Windows native advanced audit, you
can use things like the um registry auditing which configures a sackle on the registry and then you'd get object access events for the registry. Uh and then if you're using a commercial endpoint security tool, something like DF or CrowdStrike, they likely have their own form of registry auditing it as well. This bottom example is for defender for endpoint. Uh so going back to our example tools, we have things like reg.exe, XA, Mimikats, Impact, they all allow us to dump the registry. Uh, and if we're implementing our detections or blocking at our tool specific layers, we might have outcomes that look like this where we have our AV or EDR blocking mimikats. Uh, maybe we have process based
detections in our SIM for reg.exe dumping the registry. Uh, but if we were to use registry telemetry, we get coverage across all of these tools and many others because they're all interacting with the registry in some way. And so it allows us to get wider coverage by focusing on the more important telemetry sources. Going back to our funnel from before for registry dumping, our process-based events gives us coverage for our implementation specific procedures like reg.exe. Whereas our registry telemetry gives us something closer to our behavior. Like I said, the behaviors exist somewhere between the techniques and the procedures. And that's the telemetry source we're primarily interested in or should be interested in. But uh one common issue you might run
into especially with endpoint security tools which kind of operate as a blackbox is that we can't necessarily control them. If they care about these specific globins then they're likely going to treat them with prejudice and we won't get the telemetry that we otherwise rely on for more robust detections. Um so we have to kind of account for this and that's where all caps can help here. For one it avoids a lot of the reputational issues with these low bins. A lot of these low bins are abused very commonly. You look at any thread intelligence report, there's going to be at least one or two of them being featured as an attacker uses it to achieve some some end goal. Um, and we
can sidestep this by reimplementing the functionality uh in our capabilities. The other issues it helps sidestep are that we no longer need to rely on our process detections. We can reimplement the same behavior uh and we no longer have the process things to to fall back on for building our detections. Another side note, if you're interested in this kind of breakdown of attack techniques, I recommend looking at the capability extraction series by Spectre Ops. Uh this is the first post in the series, but they have many others. Uh basically, it's focused on breaking down attacks at the API level to find the lowest common denominator, and then you can use that to inform your detection
coverage and uh development.
Another thing I want to touch on here is evaluating the outcomes of our security tools. Uh if we're looking at our registry credential dumping example, uh we need to be able to answer the question, did our security tool block or detect registry credential dumping specifically. And so there's many stages within the attack life cycle that are important for this attack, but we want to focus on the most important pieces. Uh so for example, we could pull down our credential dumping tool uh maybe from a hosting server uh to the system. If we say have a network security tool block the download, did we block registry credential dumping? And the answer is no because we haven't even
attempted it yet. The same is true once we write our dumping tool to disk. If it blocks it maybe based on some, you know, AV heristic, we didn't get to the point where we've attempted to dump the registry. So, our detection doesn't really count here either. Uh, if we then go to start our process prior to it it uh getting to the piece where it does the attack and it's blocked there. I'll I'll make a note here that this is kind of a bit more of a soft no because it depends on how your security tools work. It's hard to tell, but basically a common thread you'll see with endpoint security tools is that at the start of a
process execution, they'll do some basic heristic checks, maybe like a memory scan or they'll look for any type of indicator checks or they might run it in a quick sandbox. If it blocks it at that point prior to the piece where you've executed, again, we haven't really blocked the registry piece. We've blocked this arbitrary payload. So really it's only when our attack attempts to access and dump the registry and it's blocked or detected there is when we really care about the outcome. And so related to this, we also have to worry about our relevant detection layers. Uh so when we're looking at a given attack, we want to focus our detection and blocking efforts on the
security layers that matter. If we're doing something on the registry, this is endpoint bound. we really only care about our endpoint security tool and possibly using the telemetry they generate within the SIM. If we're doing something like Kerber hosting, which is network- based and interacts with Active Directory, we really only care about our network security tools and our identity tools, and we would probably ignore things from the endpoint layer because they aren't relevant to the attack behavior. Really, ultimately, we want to align the layers we're looking at with the attack technique we're focused on. So like I mentioned we do a lot of these purple team projects throughout the year. In 2025 by the end of the year
we'll have done around 200 projects across different clients. Uh we test these clients uh a lot of them on some periodic basic maybe once a year once per quarter uh bianually and so forth. Uh and so as part of our 2025 efforts for these projects we've switched our standard operating procedure to be using this all caps based approach to testing rather than you know previously using things like system binaries to do so. uh and we've seen a lot of common failings across these client environments. Uh when I say failing, it would mean something where they previously had a block or detect for an attack technique and then once we switched to the all caps based approach,
our capability based approach where we're focusing more on behaviors, they've uh had a failure in the outcome where it's either now logged or or not logged at all. uh and some of these failing some of notable examples I want to call out here would be things like the registry credential dumping which I've called out uh several times throughout this presentation is a common one to see uh without being able to rely on things like the registry hives in the process command lines you no longer have the detections for that same with things like persistence mechanisms where they're relying on the use of native binaries like chitchatas for scheduled tasks uh and another important one would
be things like volume shadow copy deletion if you look at any ransomware report. This is basically going to be a a mainstay in any of them. Prior to ransomware executing, it's common to see shadow copies being deleted commonly with VSSS admin uh to prevent recovery after the fact. Uh and so if you see something like VSSS admin deleting all shadows, it's going to be treated with extreme prejudice by endpoint security tools. It'll be blocked outright. However, once you switch to the capability based approach where you're interacting with the volume shadow service over com using the all caps based approach, uh it's no longer blocked. you can successfully delete your shadows. So, what I want to leave you with coming
out of this is basically that many tools, many detections, security tools are are blocks, they're relying on unreliable data or they're using very implementation or otherwise bad criteria for building these controls. Uh and so when you switch to an atomic testing based approach where you're focusing very strictly, very stringently on the behaviors, it can help you identify these common issues. But really it's going to be on you to push yourself, push your security or push your vendors to improve, right? The old adage that cheaters never prosper uh holds true here. If you're cheating when you're determining your outcomes, you're only going to hurt yourself. So the slides for this talk are here at this first link. That's what this QR
code is for. The second link is to the all caps project on GitHub and my contact information is here below. Uh we have some time for questions I think if anyone has any quick ones.
If not, thanks for attending.
Related talks
 13:24
13:24 38:25
38:25 33:30
33:30 48:34
48:34 41:49
41:49 45:48
45:48