Getting Things Fixed: Security Wins and Fails
Show original YouTube description
Show transcript [en]
Cool. Um, okay. So, this talk is about getting things fixed. Uh, so my expectation is that many of you work on security teams or will eventually work on security teams and you're going to be doing kind of two things. One of them is finding problems. You're going to do that through automated tools that you're going to have bug bounty hunters that are reporting things in pentesters. You know, you're manually looking things. And that all is super fun. And I'm going to talk about the not as fun side, which is getting people to actually fix those problems once you identify them in some way. Uh, and I'm going to be talking about it not only from the perspective
of getting other people in your company to fix things. So, other engineers, other teams at your company to fix things, but also other companies to fix things because sometimes the problems you're identifying or potential risks that you're encountering could be mitigated better by some other companies. Um my experience is with Amazon um and so getting AWS to fix things and this is sometimes like getting somebody to fix things on hard mode because um AWS or Amazon is you know a trillion dollar company um no matter how much somebody spends on AWS chances are you are only a fraction of a percent of their annual revenue. Um, so trying to basically talk to this large company and get them to move and do a
thing that you want, even though you may not be paying them all that much money, uh, can be kind of difficult. So, uh, first off, a little bit about myself. Um, that's what I look like without a beard. Uh, this is a new thing for me, but, um, the main takeaway from this slide is that I've worked a lot of different jobs. Probably too many jobs. Um, but the the takeaway from this should be that I have probably worked in a position that is similar to what you're doing or what you may be doing in the future for those of you who are students. Um, so I have worked for the federal government at the NSA. I've
worked um for San Francisco Bay Area tech companies both large and small, some startups that were, you know, as small as a dozen people. I've had my own company, worked for security vendors. I have worked uh in roles where I was writing code all day as a software developer. I have worked in roles where I was on a security team using tools other people had written and never writing a single line of code. Um so I have worked a lot of different roles that that you are likely to encounter in some way. Um so my first bit of guidance to people is to ensure your own house is in order. Um so a lot of discussions about
getting other people to fix things tends to be about kind of carrots and sticks. Um, and so by this I mean that, you know, people say, "Oh, when somebody fixes something, you should, you know, bake them cupcakes." Uh, which, you know, I'm not going to say you shouldn't do that. Um, but but I I think that there are some other things that you could do, you know, and for the the stick version of things is um, you know, a lot of people talk about like you should make leaderboards and collect metrics and you should, you know, whichever team is doing worst, you should humiliate them in front of your leadership or, you know, something along
those lines. Um, and and all of this kind of creates this antagonistic relationship. And yeah, I think that you end up in a situation a lot of times where it's kind of like the the cobbler's children that have no shoes where you have a security team telling other people that they should be fixing things when there are some improvements that they could be making to their own processes and tooling um that that would give them, I guess, a better chance, more likelihood of people actually fixing the things you're asking them to do. And so I'll give some examples of that. Uh but generally it's it's kind of this view of um not looking for your
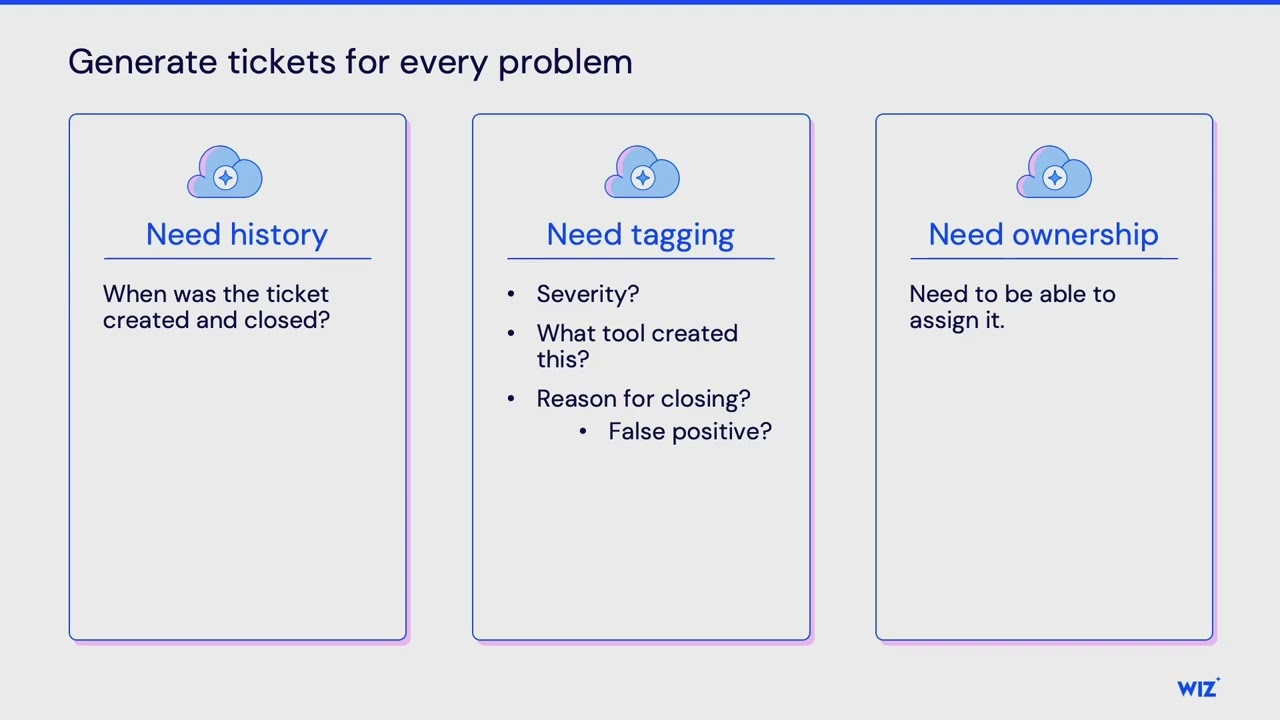
problems out the window but looking sometimes in the mirror for for those different um things that you can improve. So my first bit of guidance is generating tickets for every problem which sounds kind of simple in some ways but I have seen uh you know one company for example they had a security program that I respected in a lot of different ways but they would uh they had this tool this automated tool that would run and when I identified issues it would post those different problems into a Slack channel um and and that was all that it would do. So, it wouldn't create tickets or anything like that. And so, I think posting things to a Slack channel
is fine. It's great, but like back that up by also, you know, making sure you're creating some tickets for those things because what would happen is is because it's going to a Slack channel, their whole processes were based around Slack. And so, they would add emojis to um to the different like findings in order to identify whether or not like somebody was looking at them, whether or not they were complete, you know, different things like that. And as you can imagine, this, you know, eventually turns into a situation where different people have chosen their favorite emojis for different things. And so you're looking at, you know, this like critical alert trying to understand is party
parrot good or bad under this like circumstance. Um, and and so that that, you know, was problematic to me in some ways. And and the big thing is is the ticketing system creates additional values that that like you don't just want the ticketing system. You need all the processes around it. And so for example, what I think is incredibly important about that ticketing system is that you have an ability to know when something was, you know, first alerted on and then when somebody resolved that issue. And so you have that time difference there. And so you can then use that to identify for the different types of alerts or problems that are being found, how long is it taking
people to resolve the things? Because you're probably going to run into circumstances where you realize that some types of problems are faster or slower to resolve. And so you want to look into like why is that happening? Is it because people on the team need more training in that different area or is there some things that you could do to improve how people are responding those tickets? You know, a simple example of this would be if there's an alert and there's an IP address associated with that alert. Like often times people have to do, you know, some some lookups about that IP address like is this an IP address for our office? Is, you know, do
a Jew IP lookup to see like what country is this coming in from? Um, is this an IP address associated with tour or something like that? And so automating those processes like will speed that up. Um the other big thing is to tag things with like what tool was creating problems and what was the resolution for that like was it a false positive for example. Um and this is important because you're going to find that some of your tools you probably want to do more tuning on because those tools may be generating a lot of false positives. You're getting uh you know bad signal from them, a lot of noise from them. And so all these different things together
are are what's important about that ticketing system and then also that you're also identifying ownership. So let me talk a little bit about like the maturity or some of the options that I see and I think that this is kind of the maturity and so I have been focusing on AWS. So these last two options are very AWS focused here. Um but the first thing people do when they start trying to figure out how to identify ownership for a problem is you basically act as a relay. security team does where you're re reassigning this ticket to somebody closer. So you assign it to a business unit who assigns it to a product team who assigns it to an
engineer. The engineer reassigns it to a different engineer and that type of thing happens. And the more people that are involved in reassigning it, the more delays occur and the more problems ultimately result from that. you know, for example, you'll assign it to somebody and then you'll find out that that person's gone on vacation or they've, you know, left the company or, you know, something else has happened in which like your expected SLA of when that ticket was resolved is going to take longer. So, you're like, hey, maybe we should automate things or maybe we should try and bypass some of these people and we'll look at their logs in order to figure out, you know, how how
to do this. And so you basically try and figure out who touched one of these resources last. You know, so if it's a misconfigured resource in some way or um you know some type of vulnerability, you look at who touched that thing last. Let's try and assign it to them. And sometimes you try and automate this. Sometimes you do it manually. But you'll look in like cloud trail logs or get commits in order to do this. And and this also breaks down in different ways because your cloud trail logs like you you eventually try and look at those and you see that like the person that uh you know deployed this was uh GitHub or
Terraform or something like that like it's not an actual human being behind the scenes and so this breaks down in some ways. So then you decide well let's implement tagging on everything. let's try and tag every single resource and um this is like a big thing that's done in AWS and this breaks down in different ways too because uh ultimately like not every resource in AWS can be tagged and there's various other problems with this like sometimes people will tag a resource with their name somebody else will tag it with their email address somebody else will tag it with like a product team and so there ends up being these discrepancies there and so what I
view as kind of like the final thing to try and do is account vending. And so by this what I mean is you're making it easy for people to create new AWS accounts. Again, this is very AWS specific for this example here. Um, but what you're doing is you you not only like create these accounts with cloud trail enabled and some other security controls enabled there, but what you're also going to be doing is making it easy to create that account and have that account automatically integrated in with GitHub and have like a skeleton tele um Terraform template in there. Have a CI/CD system that automatically deploys when somebody merges code into that repo. Like all those things together
make it very easy for somebody to get up and running with a new AWS account. And so my personal view is that if a company has like a dozen AWS accounts like I feel there's room for improvement. If they have thousands of AWS accounts and my general opinion like things are better in that environment. There is more complexity. It is a little bit more chaotic. Um but but in general I think it's better to have more of those accounts. And one of the reasons for this being is that in AWS uh your strongest isolation barrier is having separate AWS accounts. Uh so my next big piece of advice is ensuring you're driving towards the best outcomes. Um and so by
this what I mean is oftent times security teams are doing constant firefighting. Um, and so they are tactically fixing issues when they should give some consideration to what they can do to strategically like mitigate those problems. So you can think of this if they were using that firefighting uh metaphor to like remove some of the flammable resources in an environment. Um, and so I'll give an example of this. If you have an AWS environment, you probably at some point has have received a bug bounty hunter report telling you you have an SSRF. um and they are able to identify credentials in your environment. Um so the screenshot on the right there is an example of what those credentials look
like when you're able to steal them. Um and this is due to somebody using something called IMDS v1. Um even if you know nothing about AWS security, you can probably guess that if there's a v1, there is probably a more recent version. This one's called v2. And you can probably guess that it is newer and more secure. And if you guessed that, you would be correct. Um, and so, uh, oftent times when people are faced with one of these bug bounty reports, the tactical solution is to fix the SSRF vulnerability. And you should do that, but you should also consider the strategic solution of upgrading from IMDSV1 to V2. And um, so there's a couple different ways that this can be
done in an AWS environment or just generally in cloud environments. You can implement different cloud um, implement different guard rails. So in AWS, those would be called service control policies or SCPs. Um there's also the concept of paved roads. And so what this means is you're making it easier for people to um deploy different solutions in your in your environment that are preconfigured with not only things that are doing security the right way, um but they're also going to be easier for people to use. So it's different libraries, different modules and your engineers ultimately want to use those modules because it is the easy solution is the paved road for them to use and this is
the solution that you have already identified various risks and mitigated those in. Um the other thing you can do is ensure that you have detections inside your CI/CD environment. Um and so what this basically means is when somebody commits code to a GitHub repo, it automatically is getting scanned for various types of problems, misconfigurations, things like that. And so it would automatically detect, hey, you're using IMDSV1. We're going to block that from being merged in until you upgrade it to IMDSV2. Uh, another example, and so I'll give kind of a war story for myself is um you're going to find at some points in time where you have a lot of problems that you have suddenly started looking
for. So um for myself, I was working at a company where we decided one day that we wanted to try and get rid of IM user access keys. Um and so in AWS, IM user access keys are these credentials that never expire. And so these oftent times have existed for like 10 years. They have been, you know, pasted into Slack channels. They are in backup files. They are in source code. They are in commit logs. They are all over the place. these secrets that um if an attacker finds these, they still work and they may be able to get like admin access to your production environment. Um and so we decided we need to get rid of these
things. We knew we had some. We didn't really know how many we had. We looked to see how many we had. We had over 10,000 of them. Um and that's a lot. So, just to give you like some simple math, if you make a like guess that this should only take 30 minutes, and that's probably a bad guess because people like have to context switch and they have to understand the problem and things like that. But if you make the assumption that it's going to take 30 minutes to fix each one of these things times 10,000 issues, that's 5,000 hours. And so, that's going to be 2 and 1/2 years of engineering time to fix this issue.
So, anything you can do to improve or reduce the amount of time to fix that many issues is going to pay off for you. And so my recommendation is that you get involved in a sample of those issues. Get involved like a hundred of them or at least a dozen of them um to see how are engineers like figuring out what are the alternative options that they could be using instead. So in the case of um IM user access keys, there's a couple different choices that you can make. So what are the different choices they made? um how did they come to that decision and try and document all these things and and when they go and
implement that decision they're probably hopefully going to try and test to make sure they didn't break anything and so again like how did they uh you know test that how are they debugging things when it goes wrong um try and document all that so you can speed this up for the next person my other guidance here is to see if you can bucket some of these issues into various groupings of problems and so for us we had some of these IM M users were als they also had passwords associated with them which means that humans were logging in with these which means they weren't using our SSO or identity provider um to log into their cloud environments and so for that
grouping of issues we were able to focus on that and this gave us the ability not only to um implement some specific guard rails to that problem uh but it also meant that we could eradicate that one type of problem and that helped us build momentum. Um the other thing is is by putting in some of those guard rails there for that type of problem, we could ensure that we stop the bleeding. So it wasn't a problem that was getting worse. Uh something that is very defeating is if you try and tackle one of these problems where you have 10,000 issues and you start working on it and you spend a few months and you resolve like
a hundred of those issues and then you go and check to see how many issues you have at this point in time and your expectation is you should have fewer but now you have like 20,000 issues because the problem just kept getting worse. Um so you want to try and implement those guard rails as early as you can. The other thing was also, you know, it helped us understand why this was happening. And so, um, you know, I talked to one of the engineers. I was like, why did you do this in the first place? You know, which, like I said in a nicer way, but, you know, was trying to understand like, you know, why why was
this happening? And, um, you know, they pointed out that we had some documentation at our company that was saying like this is the way to do things. And we're like, oh well, we should change that documentation because that is going to make this problem, you know, continue to happen and continue to get worse. So now I'll talk about fixing things externally. Um so again this is going to be primarily about my experiences with Amazon AWS. Uh but these I think are going to be some concepts that are going to apply to everybody. Um so the first one here is with manage policies. So, IM manage policies in AWS are these ways of granting privileges to different
principles in your environment. Um, and so these have some problems, but it's better to do this than to just grant admin access to, you know, all the different principles in your environment. Um, so you give them some defined roles that they have. And so, a friend of mine, uh, Brandon Sherman in 2019, he identified a security issue with one of these policies. Um, and so I figured like, you know what, I bet there are other problems with with all of these policies. And so at the time there were 500 of them. And I didn't really know what I was potentially going to look for. Um, I could have just looked for the problem that he identified to
see if that existed anywhere else. But I decided like let's just do an audit of all of these any types of problems that I could potentially find. Um, and so I went ahead and and just looked through all of those. And so I identified um a couple of different types of problems. We have on the left here. This is like a clear privilege escalation path. So this um ops works policy was like pretty fine grained in what people were supposed to be allowed to do except it had this one set of statement or this one statement in here with a set of privileges that was granting basically a whole bunch of AM uh privileges here. So in this case
you had the ability to create a user to give that user an admin policy and then create an access key for that user. Um and so with that it was like a very clear path to privilege escalation. Um so reported all these issues and and another set of the issues were just like privileges that didn't exist. They were invalid privileges and so in this case S3 list objects within lake formation like that doesn't exist. I also found spelling mistakes for privileges and just all sorts of other problems. And so I decided to create a tool in order to try and fix this. Um so I created this tool called Parliament. I was working with Duo Security at the time. Um so it
was released under their name. And this was a tool that would automatically identify those spelling mistakes, any other types of invalid privileges. Um and then also a lot of those privilege escalation issues as well. And so developed this tool to give AWS or anybody else the ability to find this problem. Eventually AWS then incorporated that same type of functionality into their own service. Um so and they they released a blog post and you know thankfully or you know um I appreciated that they reference Parliament the tool that I built with Duo Labs. Uh, and so they eventually incorporated this on their own. And so the key takeaway from that story is to build a tool. And it doesn't have to be
a tool in the sense of like it doesn't have to be a full application that you install and like you know has all of its own documentation and website and things like that. It can just be a Yara rule or a nuclei template or a SER grep rule or something else that allows somebody to automatically identify these types of problems so that they can then incorporate that automatic identification into their own CI/CD or into their own scanning in their environments. Um, and so especially for those cases where you're trying to get a company to stop doing a problem that you're identifying or or um trying to get other engineers in your company to stop doing a problem that you're
identifying and you don't have the ability to like directly fix or prevent that problem. Having somebody have a tool to identify it easily on their own is another solution and and helps them to fix this. And so you know luckily once AWS implemented this they stopped making those same types of problems that they had been making previously. The next one that I want to talk about is um this integration that could be done between GitHub actions and AWS. Um so the concept here is you have a GitHub repo and you want anytime somebody merges code into that repo that it automatically deploys to your application that's in AWS. And so you use GitHub actions to do that. use this
integration called OIDC and you have an IM role in AWS that is supposed to have a policy that looks like this. Um the only important line in this policy is that very last line of text which is specifying which GitHub organization and repo is allowed to assume into that role. If you don't have that line then any GitHub organization in any repo can assume into that role. And so there were a series of researchers that were scanning GitHub for this type of problem and identifying victim organizations. So basically like every month a new set of researchers was finding a new set of victim organizations which had had this problem um and allowed these researchers or anybody else that could create a
GitHub account to assume into this role inside the AWS environments of these victim organizations. Um, so I decided to get involved in this problem after seeing like four different sets of researchers because they were reaching out to the victims, but I wanted to reach out to AWS and to GitHub and to um some other places in order to try and get them to try and fix things. And I want to mention also is that when you are reaching out to external organizations and you are asking them to fix things, you often times don't know for sure if you asking them to do something was actually what got them to do something. So I don't know if like
AWS did things because I requested it. I just know I asked them and subsequently at some future point in time they did that thing, but it could have already been their plan. You know, it's like telling somebody like, "Hey, you should eat food tomorrow." Like, they're probably going to eat food tomorrow anyways. Like, I don't know. I don't know if like me telling them to do that actually had an impact on anything. Um, but this is just from my perspective. I know I asked certain people to do things and ultimately it happened. Um, and so some of the outcomes from my involvement, well, one of the things I did was I was like, why are people doing
this problem in the first place? And so I Google searched on how to create one of these integrations and like one of the very top links there was this blog post, a tutorial telling people how to do it. And um unfortunately it had this like issue in it. And so I reached out to the author of the blog post and I was like can you please like you know change your tutorial to tell people to do things the right way. Um and and luckily so so they did that. Um, and this was like a complicated problem in some ways because it wasn't it it wasn't like an AWS problem specifically. Uh, because AWS documented the right way to do
things. They had a secure way of doing things, but like I didn't really feel right about blaming the victims all the time because I knew that other people could fix things as well. And so it wasn't like an AWS problem specifically. It wasn't a GitHub problem specifically. Uh, Terraform or Hashior Corp was also involved in this issue. do in a certain way, but like again, it wasn't really their problem specifically. Like it was kind of the combination of all these things that were creating that problem. And so that's why no progress was being made on it was because nobody was really taking ownership of this problem in the first place. Um, so I I reached out to
AWS and I was like, hey, you guys know like you can just pretty easily scan for this problem in all of your environments and then reach out to all of your customers. Um and so they did do that which again I don't know if they did that because I asked them to but it is a thing that they did after I asked them to. Um I also reached out to Hashi Cororp uh because Terraform was somewhat involved in this issue. Um there was there's a um a kind of certain feature of Terraform. I would refer to it as a bug. They refer to it as a feature. But um there is a feature which they decide
to write a security bulletin about um in order to inform people that this feature may not work how some people expect. Another thing that was uh really important was I I asked AWS to improve their user interface. Um so the picture that's kind of a little bit covered there on the left there, that larger screenshot. Um this is how you nowadays create one of these integrations. And so, um, if you're clicking around in the web console, the way in which historically, um, you were supposed to set up one of these integrations and the way the tutorials and everything told you to do it was you basically say, I want to allow GitHub to assume into this
role and you're going to be creating a vulnerable role, but the expectation and the guidance is that now you are supposed to modify that vulnerable role by uh, handediting the JSON in order to add in the security functionality. And anytime like somebody has a nice little user interface wizard to click through and everything works and then your expectation is that they're going to go back and modify some JSON text file like they are never going to modify that JSON text file. Um and so I asked AWS I said hey anytime you see somebody creating one of these GitHub organizations ask them some additional questions which automatically add in that additional security check there. Um, so they did
that and then also uh using that IM linting that they integrated that was based off of the tool that I created, they also added some functionality that would automatically detect when this problem occurs. Um, so so basically when somebody was going and handediting that JSON, it made sure that they added in the correct thing and they didn't delete that thing from it. So that was amazing. They made those fixes. Um and then something which I didn't even ask them to do was they actually decided you know what like there is nobody in the world that is wants to have an IM role that is accessible by every single GitHub organization in the world. We should
just stop people from doing that at all. Um so they actually did that. They actually fixed that. So nobody is going to have this problem again in the future. Um, but that wasn't something I asked for and that was kind of like a lesson learned for myself is like I didn't expect them to do that because that was like basically a breaking change and AWS is very big on never breaking anything in people's environments whereas that was a breaking change and so I didn't expect them to do that but they did it and so that was like a lesson learned for myself was like don't be afraid to make those big asks. Don't be afraid to like ask
somebody to like do what you think is the right thing but yet you don't think they're actually going to be doing. Um so those problems got fixed with the GitHub organization with AWS but then people found other vendors also had similar types of issues. So um instead of GitHub having this integration issue, somebody identified that GitLab also could have this integration issue. Somebody else identified that Terraform cloud could have this integration issue. somebody else identified that Microsoft Defender for cloud could have this integration issue with AWS. So all these different people were seeing all these different vendors and again it was a situation where like every month somebody finds a new vendor that has a new possible issue
with this. Um and the in these cases they weren't I don't think people were actually searching for the victims but they just like pointed out like hey somebody could make this same type of problem. So in this case what I did was um so I work at a cloud security vendor. I have a lot of visibility into things. This is also like one of the things we try and do is try to identify what are all the misconfigurations for any types of vendors that somebody could make this misconfiguration with. So I wrote up a blog post, documented all that. Um AWS saw the blog post and then they released guidance to everybody to tell them
basically how to create a guard rail to prevent these problems for all the different vendors. Uh they have some other things in the works is my understanding. Um but that's not public yet. So we'll we'll see when that happens. But I think that this problem is going to uh get further mitigated in certain ways. Um and and I should point out from like that quick screenshot that I showed uh none of the vendors were doing things wrong. It's just every vendor had like slight different nuance in how they did this integration which was why people were potentially doing it wrong because every single vendor worked in a different way with the same integration. So even if you had set up
like a GitHub integration and you knew how to do it the right way, there was a potential that if you tried to set up a different vendor, you may do it incorrectly if you tried to use the same concepts as you had used from GitHub actions. Um so the takeaways from this is to find the root causes. Um so you know how I mentioned where I looked up like like how were why were people creating this problem in the first place? Oh, there's a tutorial on like one of the top Google search hits. Like finding those root causes, getting those things fixed. Also attacking it from multiple angles. So, reaching out to the different vendors. Um, identifying that
this problem could occur from somebody following that tutorial or from uh, you know, the user interface as well. Like attacking that from multiple different angles, trying to get it fixed in every different possible way. And then finally there, like don't be afraid to make those big asks as well. This next one I want to talk about is related to the Capital One breach in 2019. So, anybody that talks about cloud security is ultimately going to talk about this big breach that happened. So, this was in 2019. 100 million uh credit card applications um were exposed in this breach. So, I wasn't working at Capital 1. I didn't have anything really to do with with uh like the initial
aspects of that situation. I got involved kind of later. And so what happened was is um I guess to to kind of set the scene a little bit is as part of this breach it was known that the attacker had abused that IMDS v1 that I talked about earlier. Um at the time it was just called IMDS though because it was the only version. There was no V2. So it was just called IMDS at the time. And so um and this was something that was known to be problematic. there were, you know, some some researchers had presented there was a presentation um at Blackhat in 2014 about the problems of IMDS and kind of some of the security
deficiencies that it had. Um, and so this incident happened in 2019, so like five years after that original black hat presentation after people had been talking about it, like it was a well-known problem in the cloud security community that if you had an SSRF vulnerability that an attacker could steal these credentials in some way. Um, so this senator, Ron Widen, um, from Oregon, he reached out to Jeff Bezos, who was at the time CEO of of Amazon, and he basically said like, "Why aren't your servers more secure?" And he specifically called out this problem with IMDS. Obviously, like a senator doesn't know about IMDS. He um he had somebody this guy Christopher Seiggoian um who who's one of the people that
works there who probably like wrote the letter and everything, but he he ended up um like reaching out uh he reached out to Jeff Bezos asking him why didn't he secure things more. Um and and I should point out this whole story is basically going to be an anti anti-attern of like a thing you probably shouldn't do. Um and and I'll get to this here in a moment though. Uh but so he he reaches out to Jeff Bezos and then the CISO of AWS responds and said like we didn't know this was a problem and this like frustrated me because I was like this is a known problem and this is like a situation where like I'm I'm kind
of dumb and I was like somebody's wrong on the internet. I'm going to reach out to that person and explain why they're dumb. I didn't think to myself like this is a senator and this is like you know the CEO of a trillion dollar company. like I didn't think about the repercussions of my actions. Uh but I decided like I just need to set a right that is I need to set right a wrong in this world. And so I reached out to the sender and I was like hey let me give you some ex like evidence as to why um AWS did know about this problem. And at one point in my um you know like a year
earlier I had randomly one day had a little bit of extra free time and I decided you know what I'm going to report this issue directly to AWS's security team. I'm going to go through and do things like the proper way of reporting a security problem to a security team at a company and and make sure like in case the day ever comes that I have evidence of doing things the right way. Um, and so I didn't think anything of it and like 2 months later like I didn't hear anything back from him. Two months later again there's this like public letter and I guess because like it's senders involved like all these letters are public. Um, so he
writes this public letter to the FTC requesting that they open an investigation into Amazon's failure to secure the servers that are rented to Capital 1. That this may violate federal law. The reason why it may violate federal law is because they have an obligation to respond to third party reports of security vulnerabilities. Um, and that they have some evidence that uh their security team was contacted by email by a cyber security expert. And I was like, "Oh, wow. That's really interesting. I wonder like who contacted them cuz I'm like really dumb guy. Uh and so at the very end of the letter they provided a redacted screenshot of an email and that was the email that I
had sent AWS. Uh and so like they redacted it but included in there it says that you know this is um part like this problem was shown in flaws.cloud the security challenge and like if you go to flaws.cloud it says this was written by Scott Piper. So it was, you know, like very clear like who had done all this. So there was a period of time in which like I was scared of like every Amazon van that drove down my street as to whether or not like I was going to get kidnapped or what was going to be happening with that. Um so so again, this is kind of an anti-attern I guess um of what not to do. Luckily like
nothing happened to me legally. I never had to like go to DC and testify or anything like that. And I don't really know what happened with um you know the like that investigation um in general. I do know however that nowadays AWS is much more responsive to security researchers whenever they reach out to that email. They they guarantee a 24-hour response whereas previously they were sometimes you know just forgetting to respond in any way to to the emails from security researchers. So although there may be some and patterns associated with this the takeaways from this is to report security problems to security teams. So I think a lot of times if you are working with vendors
you may be like you know you'll have a zoom call with your sales rep and you'll you know explain some type of issue to them and the sales rep's like cool yeah sure I'll make sure people you know do something about it and the sales rep has no idea what you're talking about. Um and so report security problems to security teams because those are going to be the people that actually can understand the problem and actually resolve it in some way. Um also like if you are just telling your sales rep over a Zoom call that you want something fixed like you don't have any record of that. And so I think it's important also
like even if it's not a security issue um if you are interacting with vendors in some way and you make a request like to make sure you have some type of like text copy of that so you can refer later um you know to to them about that. So again with this IMDS v2 issue. So uh eventually I ended up working at a company and we decided we wanted to get rid of all the usage of IMDS v1 at our company. Um and so this was like in 2022. Um IMDS v2 had come out in 2019 just subsequently after the Capital One breach. And so we, you know, we would ask our vendors to try and like fix
this, try and give us a way to do this because what we found was in our environment for the things that we had control over for our own applications, for the things that our engineers, you know, were writing, we had the ability to get them to upgrade it. But we had a lot of vendor solutions running inside our AWS environment. And it was those vendor solutions that we couldn't upgrade to IMDSV2. And so I would ask our vendors like hey can you please like you know do the thing so that we can um upgrade this. And it's like a fairly simple thing. And you know it had been a couple years at this point but they
would say like okay sure maybe you know we'll think about it. Um you know and some of them were more honest and you know transparent with us and they're like you know um this is low priority. We're probably not going to do it for a couple years. So like never basically. Um and so this this frustrated us, this frustrated me. Um and so we decided like uh let's just put them on blast. Let's like go and make a public GitHub repo and let's just shame all of them. Um again, this is an anti-attern of something. But this is what I had uh ended up doing. Um it was also like the guidance of me from my boss at the time.
He's now retired, so I can probably, you know, like I guess say this, but like like I'm pretty sure I was just a scapegoat, you know, like he was just like, "Yeah, make a public repo where you're shaming them and like if our vendor gets angry, then I'll just get fired, you know, like he doesn't care." Uh, so I don't know if that was like if he had considered that as well, but, you know, looking back, I was like, "That that's probably not something I should have done." Um, and this was only in 2022, so you know, I can't really say I'm all that smarter nowadays. Um but but anyways, I I put together this list.
Um and and the vendors were once I got on that list, a lot of them were very responsive and getting things fixed once they were getting like publicly put on blast like that. Uh and so I don't recommend doing it that way. I would say if I was to do this over again, I would treat it like a vulnerability in the sense that I would give them a 90-day notice and tell them like, "Hey, please fix this. And if you don't, then I'm going to put you on blast." Um, you know, I didn't do that, unfortunately. Like my thinking, my head was like, you know, this got released back in 2019. It's been three years. Like, you had 3
years to fix it. Are you really going to fix it in the next 90 days? Maybe not. Um, that was my thinking. It was probably wrong. But I will say one thing that I did do right in this was in that wall of shame, it wasn't just a list of vendors that weren't supporting this. It also included guidance to AWS to make it easier for other people to do this. and guidance on like things that they should do. So, as an example, I said like, "Hey, you have a lot of partners, you know, that that you're supposed to have these like partnerships with. You should ensure that all of your partners are doing the right security thing." Because
they did have this like um this list of things that their partners are supposed to be doing correctly from a security perspective, but this was not on that list. And so, I said like, "Hey, you should make sure that's on your list. um you should make sure that in your user interface that it's much more easily identifiable when somebody doesn't have this um you know thing happening. You should make it easier for people to do it. Like I gave them a bunch of like stepbystep recommendations on things that they could do better and they did do many of those things. Um so the takeaways from this is to have clearly defined requirements for people. So that
IMDS v2 wall of shame, it did have those clearly defined requirements and it was like a public list that I could point everybody to like and and so I I knew a number of other people that were working at other cloud at other companies that had you know good cloud security teams that were also you know spending a lot of money on AWS. So even though each of us individually was probably like less than 1% of AWS's annual revenue combined, we were maybe like a larger voice and so that they could go ahead and they could point their account teams to say hey you should do these things from this list. This is going to improve
everybody's life. Um also to apply pressure where it's more productive. Um so again like I was reaching out to our account teams and um you know for the different vendors and talking to the sales rep where is again I should have been reaching out to the security teams and reaching out directly to them in some way um in order to get them to fix things. So with that my like general takeaways from this hopefully is that like you can have an impact on things. You can actually like get you know Amazon a trillion dollar company to actually like fix things. um you can get involved with like a federal investigation. Like don't do that one
actually don't. Um but but you uh but like you can have this like you know impact on the world. You can try and get people to change things. You know if you see something wrong like you can track down what the root cause is and get somebody to actually like fix the things that are on the root cause. Do things to mitigate this problem to make it easier for people to not have this problem in the future. And then ultimately like the world becomes more secure and a better place and everything is good. So with that thank
Related talks
 39:30
39:30 7:47:16
7:47:16 45:11
45:11 3:30:16
3:30:16 49:30
49:30 47:23
47:23