GT - Stop and Step Away from the Data: Rapid Anomaly Detection via Ransom Note File Classification
Show transcript [en]
so let us kick things off first and foremost I am NOT a data scientist so please take everything I say with a grain of salt and feel free to you know put me down afterwards hopefully not during my talk and tell me how wrong everything was that I talked about but you know hopefully it's not that bad but so yeah I'm mark Creager I do Mallory search at endgame you know reverse engineering software dev a bit and I've primarily been working on ransomware protection research for the past couple of years so this kind of dovetails into the research that I did for this project so just to go over the agenda for today I'm going to give a
very brief overview of ransomware current rates more detection methodologies what ransom notes look like typically then I'll delve into talking about exploratory research than some results that I got from that initial research that I did and then the development of a panic proof of concept framework along with the results from that and wrap things up with the conclusion and hopefully I have time for questions at the end all right so a very brief overview of ransomware if you're not familiar with it it's simply just malicious software that's going to encrypt files on your hard drive to deny you users access to them I just going to tap typically target common file extensions so PDFs text files Docs Excel
spreadsheets things of that nature basically they want to get the most bang for their buck without file without encrypting every single file on your hard drive and making this system completely useless there's gonna be two types of output that are produced from ransomware you know the most obvious is going to be encrypted files and then typically it's also going to produce ransom notes on disk and we'll get into the purpose of ransom notes in a bit so the current say the art for detection methodologies can break down free neatly into two categories you have static detection which they're gonna take place without any sort of execution of code of the ransomware so they're gonna be either
more baby kind of typically oriented or it's going to be based off of here is six or signatures or something that's a little more next-gen that's gonna be based off of something some sort of machine learning model the benefit to those obviously is that all data is going to be preserved and that no code will be executed but the drawback to that is that if you do miss that detection then essentially your entire host is open to compromise and all that data is going to be lost in that process for dynamic detections there's there's a few things that can take place one approach is to plant canary files onto a system and basically the purpose of
these is they're going to be monitored and if they're modified in any sort of way that a user want it then that's going to be essentially their their triple er to say hey there's you know anomalous behavior taking place on this on this host so that's one approach you know along along that same line is you know just having something run aah and run in the background and monitoring processes searching out anomalous behavior so the benefit to a dynamic approach is that you essentially have you know while the processes are ongoing you have a chance to detect them the ring somewhere the drawback to that though is that in that process you might be sacrificing essentially a large
amount of the files in hopes of the eventual detection so how can we improve these you know two categories of detections well the easiest way to do that is to combine them so a static and dynamic approach a layered security approach that leverages the the advantages of both is is the most Neilsen area that you want you obviously want to be able to detect something before any sort of sort of code exists that's that's the most ideal scenario but if that doesn't work out you still want a fallback you know that you can rely on that that may eventually detect the Ransom are executing you can tailor your machine learning model to specifically classify ransomware instead
of just generic malware there's a definitely you know a lot of research that can take place in that and then you know trying to improve the dynamic detection methods to pick up on an almost behavior a little more quickly and that's that's the goal of the research site that I sought out with this project so going back to ransom owes as I discussed earlier so the basic idea with a ransom note is that it's something that is dropped disk in order to solicit a rat's payment from the victim of the ransomware so phrases such as your files have been encrypted base and will decrypt your files things like that that's what you're gonna see in a
ransom note there's multiple file types that ransom notes can take on the most typical that you'll see is dot txt or just plain text file there's also formatted or rich text format such as HTML and RTF and then you know there's also images jpg PNG s things along those lines ransom notes are typically going to be one of the first files ever been to disk that's not always the case but it's typically what we see and in certain ransomware families ransom notes are going to be written to every single directory on the host and sometimes if not every single directory it's just every directory that is going to that sees a file that's encrypted within it will have a ransom
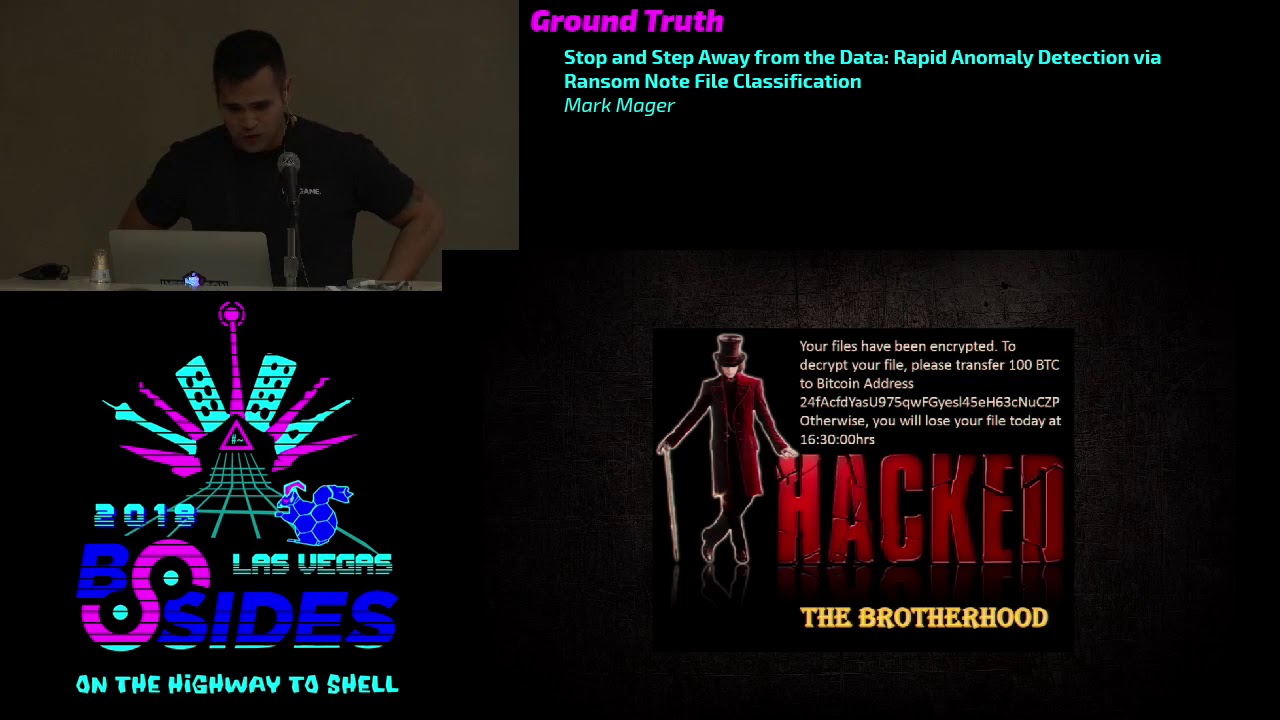
note as well so essentially you're trying to be this annoying as possible just try to get their point across they really want their money so here's a example of a ransom note this one's from cryptolocker this kind of goes over some of the phrasing that I'd previously discussed you know that the first thing you lead off with is saying your files have been encrypted in the cryptolocker they tried to just bribe essentially what encryption is you know they want you to contact them they're giving you a certain expiration date for how long the files are gonna last they're saying antivirus is not going to help you at this point and then they even get into explaining the OAS
for ya here's another example you know now that you saw the first one from cryptolocker now you see this it basically says the same thing all your files have been cryptid they talk about specific document types they talk about decrypting they want you to send Bitcoin to their address you know and they even say thank you at the end which is very nice and there's this one which is actually a image in this case their ransom payment is 100 Bitcoin which currently translates to about $750,000 so not sure exactly who they're targeting with the specific ransomware but you know and they're also you know giving a very specific expiration date so different approach with that one so
as we've seen you know just from looking at three ransom notes right in a row how you can start to come up with a template for how Ram two notes look your files have been encrypted by insert ransomware name sometimes they're going to explain intricate details in the encryption you know just to scare you a little bit say hey is 56 are say to 2048 whatever they're gonna explain that your files can't be decrypted on their own they want you to send a ransom payment to whatever their wallet ID is you can optionally email them as well and they're gonna give you an expiration date so knowing all this my basic idea kind of mix around this in my head for a
little bit as you know definitely very much a data science novice so I wanted to figure out a way hey can I apply a data science to essentially detect ransom notes as they're being written to disk and can we differentiate them consistently from normal text files so with that mind you know first goal was to develop familiarity with the data science concepts and tools that I'd be using and I'd go out and collect build up a good collection of ransom notes and then on the flip side I'd also need to put together a base benign data set that I can prepare the ransom notes to and then determine how suitable rancid notes are to classification and you know how
solvable this problem really is so a quick overview of tools I'd be using anaconda Python 3 do my most minor work in Jupiter notebook psych it and Spacey okay so for data sets benign data the easiest thing I found to use was just the 20 newsgroups data set and that's around 11,000 samples that spans 20 news groups that were I believe that data was collected you know like in the 90s or somewhere so so it goes away back there's the the categories all kind of listed out there and then the ransom notes so the way I collected those was from actually manually detonating ransomware samples in virtual virtual environment and collecting artifacts so that made up a certain portion of the of
the corpus and ransom notes the rest came from just coming through security research blog post Twitter downloading actual text notes when they're made available by pastebin or whatever or actually downloading screenshots of the ransom notes and then using OCR to extract the text so to get into the approach that I'm taking for the exploratory research what we're working with at the moment or for this problem is it'll be unlabeled data we'll take the ransom notes and we'll take the 20 years group's data and we're going to throw them into one unlabeled data set and we're gonna leverage k-means clustering and set it to sort the data into 21 clusters and they met reasoning behind that is we have 20s newsgroups
and we have one set of ransom notes so ideally what we'll see is the ransom notes all clustered into one one tiny cluster and then the 20 newsgroups all sort out into their own individual clusters in order to get a better idea of the data we're working with we'll also use a bag of words approach with account vectorizer and then also use tf-idf to also look at the features so first things first we need to do a little bit of data preparation so all we're gonna do here is strip out any sort of newline characters are going to convert all strings to lowercase then we're gonna actually do the tokenization and so we're splitting a you know a
large string into just the individual words and we're going to strip out any sort of stock words like the a and and anything that's gonna be within the Spacey's default soft words list then we're gonna go from there to only taking two count alphanumeric alphanumeric strings and then we're gonna go ahead and lemma ties the strings and basically convert them to you know a more generic form of the specific word so with this you know very simple sample here what we're going with is we have essentially a string that we you know kind of constructed that was describes a very basic ransom note and then we run it through our cleaning routine in order to
clean everything out and what we end up with is a pretty simple string in the end file and Crips and Bitcoin ransom payment and you can see how that definitely ties you know very closely with what you would think a ransom note is going to portray and when we're taking into account the count vectorizer and tf-idf vectorizer i we want to get an idea of what the what the top words are going to be what what sort of phrases are we gonna tip ik Lisi and it kind of hits along the same sort of notes that we've been that we've been seeing so far so we're talking about files Bitcoin encryption decryption sending payments emails computers things
along those lines and then when you break it out to buy grams it makes a little more sense in terms of phrasing files are being encrypted files are being decrypted you know they want you to send in money for a private key Bitcoin address things along those lines so it it gives you an idea that you know there this language is very kind of tightly coupled together now well actually yeah that before that was I was just looking at the buy grams with the count vectorizer as well now this is the tf-idf versus the account vectorizer and so with this we're still kind of seeing the same sort of words that are popping up they're moved up a little moved up
and down in terms of relevance a little bit but generally it's the same data and so now going back to the clustering the way things kind of sorted out is here's you know very you know high overview of the top I believe 10 terms the top 10 features for each cluster and so our ransom notes all ended up very nicely put together in cluster 3 as you can kind of see they hit the same list of features that we'd previously seen with the top words and you know just for reference the news group 20 categories or listed over there's the right and you can kind of you know group together if you start looking at some of the other
clusters you know which specific news group they might come from and so delving into the numbers a little bit you know we can see that if we actually the distance from the centroid for each of the clusters for the particular phrase that we're going to feed in to interpret our vectorizer here so we were actually through a legitimate ransom note that we ripped from one of our samples and provided it to the vectorizer and you know we wanted to get a idea of which cluster that's going to essentially attend towards and lo and behold that was cluster 3 which is the cluster that has our ransom notes in it and so if we come up with a phrase
that's similar to a ransom note but actually is in portraying the exact purpose of a ransom note we'll see it actually doesn't you know sorted into cluster 3 while it uses some of the same language it's not using in the same manner so it actually ends up in cluster number 4 which is actually a newsgroup for computer graphics so the results out of the exploratory research well despite a very small set of data and you know to go back we only had 173 ransom notes the ramps notes clustered together very well so they used a lot of the same language um and with the second sample that example that I showed there with the with the subtle different
phrasing there is some nuance in how the data is clustered it's not just going to throw anything together that has that says file and encrypt you know it's there's definitely more to it than that so seeing how the clustering worked out we're gonna say that the data set seems appropriate for classification you know and didn't have time for it but ATS any visualization would have been very nice for this project but gain ground get a lot - okay so building a proof of concept framework so what do we really need well we need a way to obtain file change events in your real time and we need a way to pass those file pass into
a something that's going to read in the file contents and essentially determine if the text comprises a rings our note and then if we've determined if it's a ransom note we need to go ahead and suspend that process and alert the user so since this is a pretty big problem to kind of take on you know I want to put put out some restrictions on you know how this is going to play out we're only going to work with English notes we're gonna restrict things strictly to text files the reasoning behind this is any sort of formatted text is gonna require additional parsing and I believe that was kind of outside the scope of the
problem that we're working with here any certain images we're gonna have to use OCR for that again that's kind of outside the scope of the goal for the project here and we're also going to restrict files to file sizes that are smaller than 20 kilobytes reasoning behind that is once you start looking at enough ransom notes you'll notice that a vast majority of them are smaller than two kilobytes and so if you provide a little bit of you know space there for some of the larger notes that actually provide like a you know the whole modus operandi behind there you know ransomware campaign and that sort of thing you know then you have like some of them bump up a little bit
but but generally they're going to be very small notes they're just trying to get their point across that your files are hosed and you know you need to send them money so the way we're gonna break things out is into you know three distinct components but they're gonna run within two processes so we'll have a file change event listener and the goal of that is it's going to take new file offence and place it into queue for the second process process B there's going to be a component that will handle the text extraction and also the machine learning classifier that will retrieve the events from the queue that process a is depositing into and the process
mitigation handler will also be in process B and that's only invoked if the classifier finds a minutes ago so here's kind of a you know good overview of how a detection scenario would play the ransomware is going to execute and drop a ransom note in the root of the C Drive the event listener is going to you know be pulling for new file change events and it gets the file path for ransom note text into the root of the C it passes that file path to the text extractor and classifier the text extractor will read in the contents of the ransom note and pass it to the model and then the classifier returns yes back
to the event listener and then the ransom or bill will be suspended so for the framework what we wanted to do is come up with the data set it was going to be a little more reflective what we might typically find on a Windows host and so we took a subset of the twenty newsgroups data set we're gonna stick with around 8,000 messages this time and then also we pulled in you know a little over 3,000 text files from Windows host and these mostly come comprises of log files read Me's and Sawyer files thinks that nature that you might typically find on it with us host so we ended up with around 11,000 files or so and and
yep that's that's kind of what we build off of with the ransom notes we essentially doubled the size of our sample set I was able to find a few more resources for pulling down ransom notes so that helped build that up a little bit and you know despite doubling the size of the set of ransom notes that so leaves us you know very you know outnumbered quite a bit above that by the benign data and so for for the POC framework what we wanted to do was try to address the data set imbalance and so we're gonna use smoke to generate our own synthetic data to try to make up for that so the approach for the classifier
we're going to use tf-idf for our feature selection use the tf-idf vectorizer and what we're doing is we're breaking this down to a supervised learning problem we're using label data here we're distinctly labeling them into notes this time and then we're distinctly labeling the benign data the assignments and you know we have a binary classification problem if we're provided a you know a block of text is this going to be a ransom note or is it benign data that's all we're trying to answer and the approach we decide to use naive Bayes and you know more specifically be multinomial envy so here's what our data processing pipeline essentially looks like we start with our label data set comprised of ransom notes
in benign text in our pre tokenization step we're gonna strip out characters convert all the characters to lowercase we're gonna do the tokenization done with Spacey and then post tokenization we're going to only keep the alphanumeric strings as before strip out stop words carry out limit sensation then we'll convert that set of data then to vector using a tf-idf vectorizer and then we'll address the data set and balance as I previously mentioned using spoke and then the training will take place with the naive Bayes classifier so for testing we're going to split into a 8020 subsets using trained tests split and you know just to you know is probably you know might be known by most
see you guys but you know just going over some terminology here you know for accuracy score that's referring to the accuracy of the actual classification F and the score is a weighted average of the precision and recall confusion matrix just provides a overview of false negatives false positive true positives and true negatives and in terms of cross-validation what we're going to do is it's it's it represents testing the models ability to predict new data that's not being seen previously so the goal of that is that you want to run multiple runs with different training and tested test datasets you know essentially to test model as in as many ways as you can and for our
purposes we're just going to use Monte Carlo using a shuffle split so with one single test we actually ended up with pretty good results 99.5% accuracy 90 1.86 f1 score if we scale up the valley value to 100 and with our confusion matrix results look pretty well pretty good as well we have only we have zero false negatives only 14 false positives and you know everything else seems to sort itself out well but a single test doesn't really show you enough about the model you might just have happen to come upon they you know an outlier and since we're doing the 80/20 split with randomized data sets maybe we just happen upon a very lucky
set that's gonna make our numbers well so with the cross-validation we're gonna run it ten times with randomized sets and so the cross-validation as you can see see Balmer and Bill Gates are still clapping and dancing up there for the windows 95 launch release so things are still going well average accuracy is about what we saw in our one run f1 score about the same and the confucian matrix looks about the same as well so I think what that it our specific case that confirms that the the data does classify extremely well here's a graphical representation of the scores that just kind of showed the you know some fluctuation in the f1 score but they generally at least stay above 85 or
so accuracy it stays extremely high above like ninety nine point three percent on average you know as again that said I'm not need a scientist but if we believe these are good results okay so now going back to our event listener so essentially what we need is something that's going to monitor file change events for us we need to monitor all processes on the host and what we need is a mapping of each specific event to a specific source process and in particular for our case we want to monitor file creation events and so there's a few ways that we could go about this but some of them aren't going to hit every single of those three
objectives or they're gonna hit them and but it's going to be a little more difficult right so since we're code base that we're typically using is is Python you know first the other thing comes - you might want to use Python watcher the problem with that is it relies on the redirect changes API which I believe only only operates on a specific directory is a little noisy actually is a pretty big drag on performance and to top it all off does not provide a mapping of a specific change event to a specific source process and the reason why that isn't suitable for us is that we would have no idea what process that specific event comes from and we don't
know what process to suspend or terminate in that instance so essentially if we're using this as a detection framework the output of thats gonna be pointless for us we would just know that there's a ransom note on the disk we have no idea what stop so what are we gonna do event logs that'd be one way of of obtaining events for our purposes or you can also write up a file min mini filter driver file a mini filter driver in the long run is definitely the best approach to take but it's also the most time consuming and you know if you're writing code for the kernel you're definitely prone to make mistakes and crashing box so what do we
do in this case well luckily for us there's syslog and within the last year or so sis Mon they opened up their framework for exposing file creation events that they're gonna write to their own event log and so with event eleven all we need to do essentially is query the event log for file creation events and we're going to get all the data that we need so in order to reduce the noise that Sivan creates because if you ever installed system on and query the logs occasionally with just default settings there's gonna be a lot of noise in there so essentially that I just created a very simple stripped-down config file to just eliminate any sort
of process creation and termination events and limit it only the file creation events only to dot exe files and that's right there the simple command that you need to run in order to get system on configured to work with this framework and then also to query the logs VW of via WMI you need to specifically add a event key or register key to allow event log query so as I mentioned before what we're trying to do is pull the event log for new file paths and we're going to be using the WMI query language we need to limit the size of results set in order to reduce overhead because the event logs can build up over time and we need to parse
that data from the results and then pass that to our classifier work queue so in terms of the process mitigation all we need to do is like at this point we know that there is a ransom note on disk we know the source process and we also know the source process name so now we need to determine if that information is still accurate if there process still exists so we're gonna grab you know early active process is to try to determine if that process still exists if it is if it does and it's selective we're gonna suspend it we're gonna provide a pop-up to the user to tell them that a ranter no is detected allow
them to terminate or resume the process and also if they do resume the process we need to maintain a whitelist of process IDs and process names so we don't just keep alerting over and over on the same process and so at this point I'm gonna do a live demo let's see how this works a lot of confidence behind this okay so what we're working with here is a sample of the volcano ransomware and so right here I have process monitor running in the background I already have a filter specifically for right file operations that are gonna be written out by the volcano dot exe process and so I execute this and that was pretty quick wasn't so
what we have here is it lists out the the file path of the ransom note it tells us the specific process the the source process path along with the specific bed and then it's giving us an option click ok to determinate or okay or cancel to resume and whitelist the process for further confirmation that this worked 24 - 9 - volcano dot exe process explorer is telling us that suspended and if we go to the process monitor output we can see how fast that actually took place if the first file right was at you know 536 55 here we're gonna scroll down here I can get this 536 56 so essentially one second after the file writes begin is when our
detection you know kicks off and misses spent the process we can even drill down even further into this to see you know just how long you know it took for us to detect as soon as we saw a a text file
so as we can see the first ransom note was written out to the install forge a user actually just the install forge a directory or actually that's the one who that we detected on but they all the file rights took place within milliseconds of each other so depending on how they're they're pulled from the log you know one might be seen before the other but but essentially as soon as they the rain-snow first hits a disk we're gonna obtain the file pass by querying out of that log and we can see things and so if we go ahead and click OK terminate the process why volcana dot exe is no more and I'll attempt the demo
gods one more time here and actually do one more demo here for you I'm going to run a sample of BTC where I believe I have the filters all set up oh actually I didn't that wouldn't
[Music]
so yeah just gonna set up my proc monologue here just to give us some more of the output okay so if we want BTC where and we caught that one as well so you can see that in this case there were a few more follow events that took place before we actually came up with our detection I mean it's it's definitely gonna vary from case to case depending on how performant the querying of this of the event log is going to take place you know as I kind of alluded to before all of our codes running in Python we're not running our own mini filter driver we're simply just querying an event log repeatedly every 10
milliseconds so it's gonna be dragged on resources and you know you've been doing some like sort of timing analysis I I noticed a lot of different you know results in terms of how long the queries were taking place so not ideal for some sort of production ready environment like please don't deploy this to your 10,000 endpoint network I take absolutely no responsibility for what happens but you know for a limited proof-of-concept this definitely gets the point across you can see that process is also got
okay so getting into a few more results ahead time to test this out on a few other newer samples so so out nine samples two of which that I showed you test for PTC we're in volcano were able to test and detect those variants of water samples so for those specific samples what makes those a little more unique is that those ransom notes weren't previously seen they weren't included in our training set at all you know that's essentially new data that that comprises a little bit of a holdout set now for us in this case there's also three samples I specifically tested that have ransom notes that are in our training set that we were able to you know test and eject
as well so in order to get a better idea of what this really you know kind of brings to the table I wanted to produce some comparative results I wanted to compare what the capabilities this framework are versus you know what else is out there in terms of free ransom order detection capabilities so we're gonna to be doing - very well unscientific tests here test one does the product detect the sample to me that's extremely straightforward so nothing no I'm not pulling a bunch of ser tests - we're trying to detect which is faster the classifier framework or rival product A or B or C the the reason with this you know that that it's you
know maybe not the best way to measure is that there's definitely potentially a lot of different complicating factors one of which could be driver altitude and assuming that most of these products are going to be based off of foul mini filter drivers the altitude in which the drivers installed could determine you know which driver gets to see the particular file path first and do its analysis before it releases its access the file path you know for the next driver on the stack you know don't exactly know how that factors into things and you know wasn't perfectly interested and in reverse engineering all these products yeah but you know definitely take these results with a grain of salt
um so without naming names I was told you avoid that I don't want to cause anybody any problems here but product B in our case perform the best and and also was typically faster than our framework there was only one instance I believe where our framework detected something before it but most of the other results were either ties or the ordered product B was was faster in its detection by second or two but as for product a and C products C in particular you know that pretty spotty coverage in terms of detecting ransomware and even yeah well when it did it at least outperformed the framework but product a in particular yes it literally seemed to
cover all the cases or you know eleven out of twelve samples but in every instance about one you know our humble little Python based framework that's querying event logs every ten milliseconds was able to outperform it so with that being said to bring us back down to earth you know there are definitely several limitations involved here you know despite be you know very promising results that I just showed you you know it's definitely a little bit of a loaded sort of test there it's it's a lone scenario because we're already working with samples that we specifically know drop text file ransom notes and so at the moment that's all that we're it's tuned to use is or
detectives text ransom notes so you know that's one huge limitation but that's one that we knew at least going in the there are some samples I don't know any specific families at the moment because I've tested so many samples it'll pass years all the family names run together but there's some samples that don't drop in ransom notes until nearly the end so when they've you know especially you know encrypted everything on the file system then they go back and write out the ransom note so it's kind of you know would defeat the purpose of her framework and in that instance there are some samples that are actually extremely annoying and will solve some sort of
persistence ahead of time and actually keep respawning the same process over and over attempting to encrypt more and more files so in that case yeah we might catch the grantor process over and over but you're still going to be infected and you know there's definitely a lot more work that needs to be done in that case and then to get into a more wider problem there's definitely samples that take a different approach to ransomware there were two ones that attack the system in different ways and besides encrypting individual files some will corrupt the NPR overwrite the bootloader they'll do a more full disk encryption Rob disk based approach or some some are just simply very annoying screen lockers
which will make it impossible to just log into Windows on its own without actually corrupting the files in any way and then last but not least we're only working with in English right now there's definitely ransomware that targets spanish-speaking countries Russian countries there's you know russian-speaking countries there's a lot of you know other sort of variants out there but you know outside the scope of this talk in this feature for this presentation so future work the the first thing that comes to mind is we could definitely improve the datasets we could introduce much more ransom notes which would mean that we would rely less on our synthetic data so we need to keep pulling in ransom notes as new variants
are discovered and we'd also we could also do a much better job of bringing a representative benign text data set from different installers readme files things like that so you could use nine night chocolaty some sort of other mass installer to build up a large corpus of text files that are gonna be written to disk and kind of pull from there we do this a few times but definitely porting to a much lower level languages C C++ something like that that would yield significant performance improvements I mean and if we also tie into working with the file mini filter driver then you'd have you know incredible performance and we could easily at least for those cases that I
was mentioning you know outperform you know products from you know very large companies and parsers for other file types I alluded to before that the image based ransom notes ransom notes that use formatted text it'd be great to support those putting the work in to do those probably shouldn't be too much work expanding language support that'd be great and actually you know finally to go back to data science experimenting with different classification approaches would be great naivebayes just just will worked for this particular problem you know is this kind of well low-hanging fruit because you know I kind of pulled a couple of data scientists I work with and you know they've told me to go in the direction
of using naive Bayes and that's the way I went Frost the results were good enough so that's why I stuck with and so as of now the source code for all this is available on the endgame github it is a GPL v3 and it would live this morning so to wrap things up oh sorry yep I think I got it into but all right everybody good okay so wrap things up with our exploratory research we use clustering to prove that the data book was suitable for classification we were able to determine the ransom notes do share enough features across the board that would make this a viable solution product you know for this particular problem and you
know we very much realize this isn't going to catch all the waiting somewhere but going back to talking about our layered security approach this can be an integral piece of layered detection and improve the time to detect for a dynamic dynamic detent detection when we do happen to miss something statically as we see the PLC does work but there are many improvements to be made and if I can do this I'm sure you guys can do much better because yeah this actually no data science it I don't quick what little plug here for something from endgame mani right here will stamp your passports if you guys picked up the passport cards from the end game booth
earlier if not you can talk to us and we'll point you in the right direction so yeah thanks for coming I guess [Applause] yeah you don't have questions find me later yes in doing this I realize you're using high-level in-store low-level language did you do any performance tests to see like how this would work on a file server so that you can see the difference between that huh using Python or even assembly and doing these kind of cuts that's really what this comes down to is you're looking for specific keywords mm-hmm file servers are what you're gonna be worst hit by by ransomware so oh yeah um yeah I hadn't got around to like kind of
you know doing any testing with any sort of lower level languages I think you know at least for carrying out the POC oh is this easiest to use you know Python and all the performance yeah I mean like you definitely yeah I can easily see how that would be extremely you know performant for carrying things out in that way but but yeah yeah I think that would be you know kind of next step is to to go down that path and you know you know write our own driver you know and do all the other data science of you know at a much lower level language in Python 3 do you know of any the nerves are working on
solutions for masses like NetApp and integrating directly into their functionality hmm uh not not that I've heard of most of the the applications that that you know that I was kind of able to discover just once by you know some some more the main vendors and they just you know we're kind of tailor tailoring them just to you know kind of give people a rough sense of how their detection works and I don't know if that's necessarily their full enterprise support you know what they would roll out if you you know got big contract for ten thousand endpoints or something like that Cisco all right all right down with Cisco melis yeah yeah yeah yeah yeah yeah that that's the
first I've heard of it though but but yeah I I think is you know as ransomware you know continues to you know pick up in prominence I think that right you'll see more you know specific tailored solution for those solutions for different products have you seen any other os's besides Windows that get targeted for ransomware yeah um so that there's definitely a few different like Mac OS ransomware families but as we've been tracking them they haven't really evolved significantly within the past like couple years or so I I don't know if any that are you know particularly successful compared to like the actors behind Sam Sam or some of the other more prominent ransomware families
that you hear about but yeah so you know there are some some Mac OS ransomware there there's some Linux ransomware but I feel like you know that's if you are between and actually the most besides Windows I've heard about is where the attack targets of Android systems and yeah I'm not sure exactly what sort of detection capable is there are four for Android right now yep oh it's just in game ich with no dot now okay I blame the proofreaders for that kitchenette all right thanks [Applause]
Related talks
 51:51
51:51 32:48
32:48 33:48
33:48 54:33
54:33 31:06
31:06 20:51
20:51