Security AI in the Real World: Lessons from Deploying ML at Scale
Show original YouTube description
Show transcript [en]
i am pleased to introduce josh sax from sofos who will be talking about security ai in the real world please welcome him
can you guys i'm not allowed not super loud can you guys hear me okay or yeah okay okay so hi i'm joshua sax i'm currently chief scientist at sofos and my talk today is entitled security ai in the real world um okay so um the reason i i submitted an abstract for this talk is is that i think that um right now ai insecurity is in this weird state where on the one hand um there's a lot of hype and confusion um and um you know almost any new security products it comes with some marketing around the way the fact that it uses ai and some ambiguous and hard to understand kind of way um but then at the same time
uh there really is something something there with respect to to ai and security um i mean we're seeing ai make real material impact in a whole range of fields right so probably many of us read about alpha folds which came out of a team at google that made an enormous step function and progress towards predicting the three-dimensional structure of proteins which is a significant advance in science many of us have probably also followed news about gpt-3 or played around with gpt3 those of us who have access to the open ai apis for that and that's like a real advance right we've made real progress at machine learning models modeling language in ways that are likely to be really helpful
and um some of you guys have probably played around with with dali uh this this this new model that can draw images based on um natural language prompts and again this is an example of a real technological advance so my goal in this talk is to to help separate the signal from the noise here right so if you walk around the trade floor at any security conference you're going to get a lot of of noise to be honest around the role of ai and security but there really is a signal there and so i hope that this talk can be a small contribution to helping the security community sort of get at that signal and get a grip on the ways in
which ai is important now to security and will be increasingly important i'll argue in the future okay so just so you know that a little bit about the human being here giving you this this talk my my current job is i'm chief scientist at sophos that's that's the role i've been in for the last five years or so uh really that means that i'm responsible for ai research development and operations at sofos a bunch of colleagues here today who are also giving talks about work that we've done here um and looking forward to you guys getting a sort of deeper dive from from their work as well um uh before that i spent a bunch of time
in in the government worlds most of that time i was living in dc uh working on mostly darpa funded r d projects around applying mathematical modeling stats and machine learning to cyber security problems um my real background is like in the 1990s like irc hacker scene that's where i learned probably half of what i know um and that's how i arrived you know in the tech industry um and i i studied something else in in school i did i did history for undergrad and and grad school and also studied studied music um uh if you're interested in some ideas that i'm talking about here please read hillary in my book uh it's still it came out a few years ago but still still
relevant called malware data science from the starch press and then a little bit of background about the sort of professional context that i'm coming from here so sophos is a fairly large cyber security company we defend about half a million organizations from cyber attacks uh that we cover about 100 million endpoints so the data science projects i'm going to be talking about today uh addressed that that scale and sofos have has security products that cover really every major category of security products from firewall to cloud security email security endpoints mobile security and we have machine learning operating in almost all of those products um actually i would say every every one of the products that isn't
really sort of a legacy product we have we have machine learning in um so that's just some context for uh the perspectives i'll be giving today all right so i want to i want to like state my my thesis up front here um so and the theses really revolve around where like the reality of where machine learning is in terms of what's what its strength and limitations are in the way we do cyber security today um and then where and what where i think it's going um these these are my opinions i wouldn't attribute them to anybody else but i think we have some level of consensus uh on my team at sofos and among sort of security data scientists
friends i have at other companies um so here are the theses so first um with with where machine learning is today in the security industry i'd say i'd say applying machine learning uh to a security problem is actually a last resort it's like the last thing you do after you do all the easier things but it's almost always necessary and i'll talk more about that in a little bit i'd also say that contrary to i think a lot of marketing and i think popular perspective in security ml the the actual math is the least important part typically it's all the other surrounding factors that really drive accuracy and efficacy when it comes to security machine learning uh
data engineering and you'll hear more about this from my colleagues and other talks that are going to happen in this room subsequent to this talk but you know getting getting the right data in the right place correctly labeled as good and bad and that kind of kind of thing that's super important um how you monitor machine learning models in the field is super important so there's all these surrounding factors that are actually more important than the math you need to get the math right but then it's these other factors that really drive accuracy um and then in the last part of the talk i'm going to talk fast so i don't run out of time and i can actually get there
um i'll i'll talk about where i think the the role may be in terms of these larger models that we're hearing about in the news and the tech press like gpt 3 and that kind of thing i think that those models are going to be really important and i think it's it's our job as as cyber security professionals and some of us as researchers to figure out exactly how i also think a tighter feedback loop between uh security analysts and machine learning models is gonna be a big part of the future of the way we use machine learning models i think we're gonna see something more like uh amazon recommend like the amazon recommendation engine uh or the google
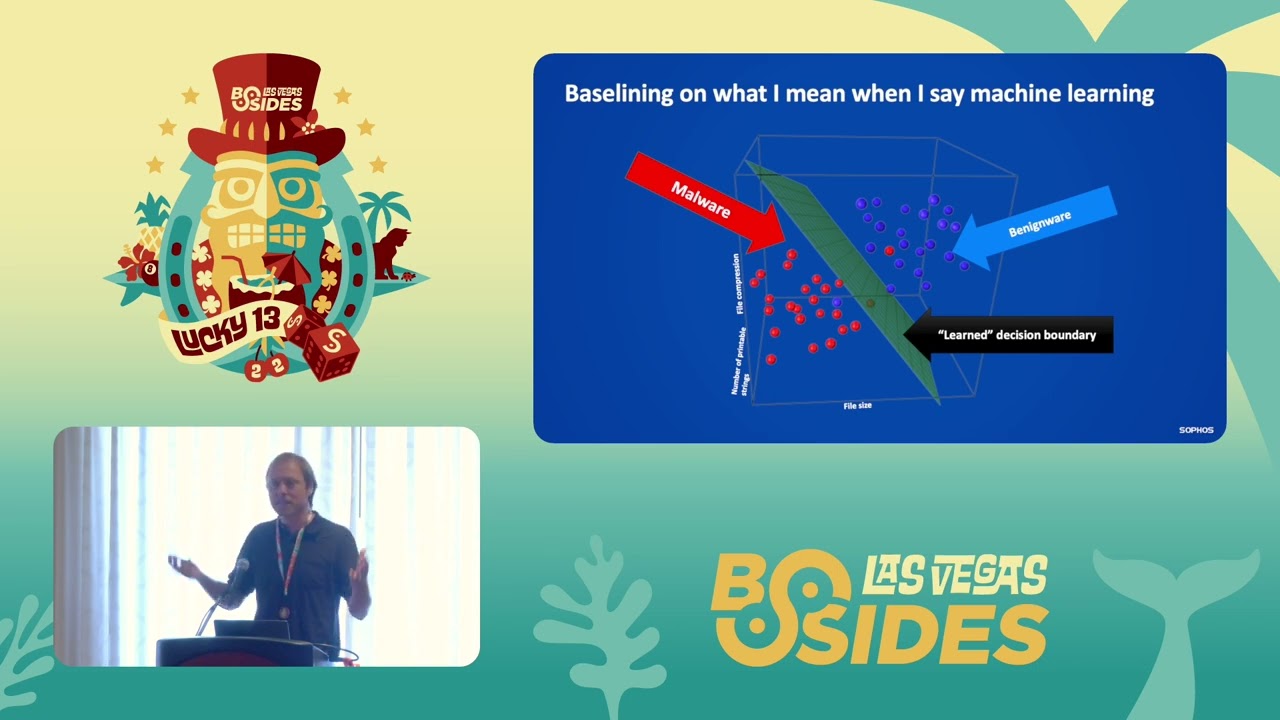
search system uh come to play in security where you have this tight feedback loop that operates uh at the scale of days uh between security operators making decisions and machine learning models making recommendations to them and prioritizing alerts and that kind of thing um so that's the argument i'm gonna be making or this the set of arguments we're making let's let's get into the actual material now okay so i think we come from diverse backgrounds here so i just want to baseline on what i mean when i say machine learning let me see if i can point to things yes i can okay on this slide so so here's like the basic metaphor for how machine
learning works in security and i'm going to be talking about sort of the slice of machine learning that supervised machine learning that matters most in security today basically so in this example we're building a malware detector um so if i want to build a machine learning malware detector i i get a bunch of examples of malicious software and benign software let's imagine we have exe files in this case uh i um and then i extract some numerical features from from each each one of those binaries and my goal here is to build a machine learning system that can detect previously unseen malware so in this example i've kept it really simple um i'm extracting on the vertical
axis the uh a feature i'm calling file compression it's just a measure of how compressed each file is might be a proxy for whether the file is packed uh on the depth axis i'm extracting the number of printable strings uh in in the file maybe maybe fewer means that um you know the file is less likely to be obfuscated might be benign and i'm extracting file size just as another feature just to be clear this is this is fake data you know unfortunately the malware detection problem isn't so simple right but um you know what you're seeing here is that the red dots which are the malware mostly fall in this region of what we call the feature space this
three-dimensional volume in which i'm plotting my data and uh the benign files mostly fall on this this in this region of the space now the machine learning problem here is is to identify a geometrical structure that that divides the malware from the benign wear so this is we call this a hyperplane in machine learning and the mathematical problem is to identify the um the position of the plane and its angle so that we're they're separating between these two classes and now the way we use the machine learning system is if we see a new previously unseen exe file we just we use some math to check which side of the of this decision boundary uh
which side of the hyper plane we're on and then if we're on the malware side uh you know we defined it as malware we're found we're on the benign side we did we defined it as benign where um so okay so if you so for those of you who are like new to machine learning if you understand this basic setup you're you're most of the way there to understanding what we do all day as security data scientists right we we build models that place security relevant observations be the urls or web pages or email attachments into a numerical kind of space um and then we identify these separating boundaries that sort of uh codify the pattern that defines what's
malware and what's benign now in the real world it's a lot more complicated than that kind of you know data science 101 example um we're actually combining lots of different technologies when we deploy a machine learning model so we're using signatures and allow lists to suppress false positives on the on the malware side and we're using signatures and block lists to suppress false negatives on the benign side and we actually have to use these supporting technologies to make a system um deployable in the real world um and and to get back to the point uh around how machine learning is really a last resort in in security really if you're designing a security system say
to detect um macro bearing email attachments uh really machine learning is the last thing that you that you do in defining such a system um so here's here's a notional but fairly accurate representation of the way that we would detect macro bearing malware um like let's say from the office suite uh at sofos so first we would just decide whether or not the observation so the observation being a document here isn't an allow is in an allow list like is this is this document in an email from a trusted sender and if so then we just allow the documents then we decide if it violates policy maybe it may be maybe the visual basic code inside the document does something
that's just policy violating that we don't allow it our company if so we just block it then we check if the sender is in a block list like a known malicious emailer if so we block it so we make all these sort of really obvious decisions first when we get to the end um that's when we apply on on the tiny trickle of documents that have made it through this gauntlet of filters um these are these are these are document files that are in the gray area where we really don't know if they're malicious or benign that's the point in which we def that we we apply a machine learning model and decide if it's good or bad um
this is typically so sometimes you'll hear from security companies that they're ai based or they they're ai you know that they're an ai first security company or something the reality is nobody deploys um or they if they do they shouldn't machine learning models uh without all of these guard rails and checks um that's really the place that machine learning lives in today's security pipelines um okay so why why aren't practitioners who do security data science uh just building machine learning models that detect malware versus benign where say or malicious documents versus benign documents or malicious behaviors versus benign behaviors um and just leaving it at that and why why are people using these guardrails and auxiliary
technologies and the reason that the reasons are at least you know these are some of the reasons uh um first of all machine learning is really hard to control so every time at sofos we train a new machine learning model um or actually every time we retrain a machine learning model that we have out in deployment on new data we really don't know uh what kind of animal we're going to get out of that training process maybe all of a sudden this new model will like in the malware case fp on system dll files uh that that the previous model hadn't been fping on um maybe it'll false negative on a lineage of malware that the previous version
detected um there's sort of a random black box nature to the way machine learning works in practice that means it's very hard to control um it's also very hard to understand machine learning models um and so and that's the point about them being opaque and basically possible to explain uh you know so if if our machine learning models are say fping on sports web pages in the case of machine learning models that look for malicious web pages um it's extremely hard for us to explain er not impossible to explain why that's happening um we can have some theories um but um modern machine learning models are usually black boxes that makes deployment really hard it
means that we have to do really really rigorous testing on our machine learning models before we send them out to our tens of millions of endpoints um and it's also just hard because of because of the reasons i just stated it's it's hard to redeploy machine learning models because every time we retrain them we're not quite sure what we want to get we have to go through a whole battery of tests before we we're actually comfortable sending them out into the wilds where they're blocking files from executing and doing potentially dangerous things in our customers computers so in contrast like older fashion methods like signatures and policies are really clean and easy to operate relative to machine
learning when i define a signature that detects a certain malware family i know exactly what i'm writing as opposed to opaque machine learning models the outcomes are well controlled the signatures that we write and the policies we write are explainable um and as a result signatures and policies are just these tactical swiss army knives uh like it like at sophos we redeploy we deploy new signatures on an almost daily basis to our customer base whereas machine learning models we deploy about once a quarter um so i'm sort of bashing machine learning here which is ironic i'm a security data scientist i want to talk about why we we almost always deploy machine learning models in
our systems even though they're so hard to deploy and really it comes down to efficacy so here's here's i think an example of what i'm talking about this is a timeline showing the accuracy of our windows malware detection system that we have on our in our endpoint product at sofos and what you're seeing here is that in this i guess six day period in in july um our our signatures caught to the best of our ability to estimate about 90 percent of malware we observed on our endpoints um there was a dip here on july 8th um our machine learning system uh detected about 95 of the malware sometimes a little bit better and when we combine
those systems together um we did the best you know of all three scenarios uh you know 96 to 98 detection um so the reason security companies are moving to using machine learning is that it's not that it's a silver bullet it's that this is to squeeze the the sort of last five to ten percent of accuracy um out of our detection pipelines you really need machine learning this is what i think all of our colleagues across many companies are finding so machine learning is very difficult to deploy there's lots of downsides to it um but it provides added value on top of all the technologies we had before we sort of took this machine learning turn
in in cyber security okay so that's that's my intro um now i wanted to go through our journey on our team uh around building a machine learning program uh over the last five years just as a kid not to not to promote ourselves but as a case study just as we have insider knowledge here that we want to share with the community um and happy to take questions when i get through this section uh around any details of sort of what we've done and lessons we've learned uh from this this process now five years ago in 2017 uh well the beginning of that year we had zero machine learning models in deployment uh at that sophos across our
100 million or so end points at that point in time um and then since then uh you know up through 2022 we've integrated machine learning all throughout our portfolio so at this point we've got more than 30 machine learning product interface integrations at sofos and that's and that's sort of swept across our whole portfolio um so this is just a chart showing sort of where uh where we've where we've deployed machine learning and how many integrations per product category we we have within our portfolio um so what exactly are we doing mitch at with machine learning uh at sofos and i just want to say um that i've got friends at other large security companies too and they're they're doing
similar things with machine learning so this is fairly representative of where machine learning is being used in the security industry in general so our first use case with machine learning was to detect windows malware that's like the the big heavy hitting case in which machine learning is getting used in lots of different places not just at sofos um then we moved on to to build models that detect malicious malicious email attachments like excel powerpoint and word documents uh we have machine learning that operates on on on android endpoint devices detecting malicious apps um a bunch of different detection models that detect um basically the the major having hitting um categories of threat vector types um we also use machine learning in the
context of web content filtering so we have a model that looks at urls for data scientists in the audience this is a character level convolutional neural network and then we have another model that's if people are interested in the paper reference happy to share but it's sort of convolution-like that operates on on html javascript and css then we have some models that we use to help explain detection results to users that that for example when we detect a file as malicious show the most similar files in our database that are also malicious versus the most similar files that are benign and let users sort of understand uh why we detected that file and models that we're working on
currently uh are more user-facing so you'll hear a bit more um at b-sides from our team about an alert prioritization model we also call this a case escalation prediction model that operates in a kind of feedback loop between analysts and the machine learning model and predicts which alerts stock analysts will decide are truly malicious and we're working on some natural language interface stuff also with machine learning so that's just sort of the sweep of places that we are applying machine learning at sofos so not all problems in security i'm really far from it our machine learning problems are appropriate to solve machine learning are appropriate to apply machine learning to so here are some criteria that we use to
define what constitutes a a good nail for the machine learning hammer so one the distribution has to be relatively stable so what do i mean by that so um so the distribution of like malicious pe files versus benign pe files for example even though that changes over time as attackers of all their behavior it's a fairly slow moving change that we see and what we've found in our research is that things change slowly enough in that world and we have enough data that we can model that problem and ship a successful machine learning model um an example of a of a distribution a distribution that doesn't fit these criteria are for example um insider threats where you're trying to
detect whether or not a user is stealing data from a company based on their user interaction behavior in our opinion humans are too unpredictable we don't have enough training examples and so less appropriate as a problem for machine learning we also need reasonable deployment and operational complexity so for example we've thought about shipping models that look at a whole bunch of different factors uh spread out over sort of different different layers of the compute stack all at once so for example you might want to look at a [Music] i don't know like a pe files behavior in conjunction with its static features in conjunction with like the url it was downloaded from um that sounds like a good idea to re to
have a machine learning model reason about all of those those observations all in one place and make it like an optimal decision the reality is it's incredibly hard to get all of the data feeds required it's integrated in one place in order to build such a model it would be very hard to actually do the engineering work to integrate a model across all across across all observation points that you'd need to deploy such a model um just too complex we found keeping things really simple and just looking at like a certain file type or like look at web pages um and train and training a model in isolation on those observables well it might not seem
conceptually as optimal um it turns out to be the right approach just because of the operational complexities um so there's just some examples of how we think about where it's appropriate to apply machine learning okay so here's here's our current organizational structure which i think is important to talk about um so we have a research department on our team so we've got about i think um 30-something people on our team right now uh we have a research department you're gonna be hearing from a bunch of these people at uh that's about a dozen people or so uh we have two programming so so i think when people think about machine learning and security they mostly think about
applied mathematicians and researchers um but i think that the the the one takeaway from this chart here is that actually the majority of our team are not applied mathematicians and researchers um we've got these other categories of um professionals on our team an important team here is program management so we have we have two program managers and an intern there right now that's extremely important in a company that's shipping security machine learning models because of where machine learning sits within a large engineering organization basically in order to do our jobs we need to pull down data from probably depending on how you count a dozen other engineering teams within our company use those understand those data
load them into the database that we use to train train and monitor all of our models and then once we trained our models then we shipped those out to like a dozen different teams so we are a central node in this in this sort of web of dependencies and it's because we need to get data from places then we just ship model to about models to a bunch of other places and so we need program managers to help tame the chaos of actually doing that in a reasonable way and then we have this large at least relative to our research and program management teams engineering organization that's responsible for uh integrating lots and lots of different
data feeds from lots of different places from our from our from feedback from our products uh third-party threat feeds that we subscribe to lots of different places loading that into a very large scale sort of petabyte scale database retraining models and there's that's really where most of the work of an operational security data science team happens which is why this is a fairly large organization and here's here's just a really high level diagram of our data architecture i think the one thing i want you guys to take away from this here is that it's most of the complexity of our team exists in this data architecture what you're seeing here is that we pull down lots of data feeds like i've been
saying it goes through a complex infrastructure ends up in snowflake and then there's a whole bunch of compute infrastructure that we're using to train and evaluate and package up and ship our models on on the right side we have a we have a dashboard that's constantly evolving but that we use to monitor model accuracy and our ops team is sort of looking at that and looking for dips in accuracy and when we have an issue right we spot it and we work on retraining or understanding what the issue is and getting a new model out there that works better a big part of our our team's uh sort of routine work is retraining all of those models that
we have out in deployment so we try to retrain them once a quarter after a quarter or so their accuracy really starts to degrade because they are modeling observations of benign and malicious observations in the past and obviously cyber security changes really rapidly this is where we monitor our retraining schedule and confluence within our team um and then finally for the for those of you curious about the actual math behind our machine learning models and i'm not going to spend too much time talking about that here are just some example architectures that we that we are currently shipping so to detect malicious urls we're using a convolutional neural network and basically the way this works
is we at a high level the neural network looks at the raw character string of a url and learns what patterns are important in terms of detecting malicious urls and makes a prediction as to whether or not the url is malicious or not at a lower level what we're doing is we are sliding these um these kind of windows over the character string and we have 1024 neurons that sort of slide over the character string looking for patterns you can think of them as kind of like elements of a regular expression and they activate when they find something of interest and then we have we then we have some feed forward layers that sort of you can think of them as
doing a kind of non-discrete if like if then else logic over the patterns that have been identified by the convolutional units and they decide whether or not the url is malicious or not so that's just one example architecture we've got papers about all of these models out there if you guys are interested in looking happy to share it's probably hard to write down these links from the slides but happy to share links for anybody who's interested enough after the presentation we've got another model which is a kind of original architecture we came up with that looks at web content that also uses that same kind of it's called a convolutional approach that looks for looks for patterns and then reasons
about the sort of confluence of all the patterns and deciding whether or not a web page is malicious and then we're using a a newer transformer model to detect malicious emails like phishing emails and that kind of thing so i'm not going to go into detail there but transformer models use a kind of a tension model in which the neural network is sort of deciding what's important uh in an email and sort of choosing to focus on the important bits and deciding whether or not an email is a phishing email so we use a lot of neural network models within our team we also use a lot of decision tree based models like based on
xg boost and random forest and that kind of thing um so so here's a i wanted to also give a kind of slice of life in terms of how we retrain and shift new models on our our our team um so here's how here's how we retrain and uh and ship our windows malware detector uh so first the engineering team uh within the organization i manage uh trains uh trains our windows malware detector on new data um but also including old data basically we look at like a recent window of about 100 million plus files that we've seen both malware and benignware so we train that model and then um the engineering team passes that model they
do their own internal tests on the model and they pass it off to the research team that that signs off on it depending on how the results look um then we send that model downstream and you'll notice we do a ton of testing on these these models uh so we then we send it downstream to another team that's external to our organization and an organization of like domain experts who do malware reversing and signature rating and that kind of thing and they also look at the results and they validate the results then we ship the model to some subset of our customer base but millions of endpoints i mean we sort of continuously roll it out until we hit all of our
endpoints and we use it to perform inference on new pe files but we don't actually block any pvp files yet we're just kind of auditioning the model and finally when an external validation team decides that the model is behaving in a reasonable way then we start rolling it out and turning it on and we we do that in chunks so we do like a fraction of our customer base then another fraction uh and finally the model is actually operational and blocking pe files from executing that things are malicious um but the point here is we do a ton of testing before we actually ship and deploy a new model and that's because of all the things i mentioned earlier the
fact that uh machine learning models are opaque hard to understand random unpredictable but they're also good and that's why we put all this work into them they also detect stuff that we would never have detected otherwise but we have to do a ton of testing before we actually turn them on otherwise you get into situations where you are disrupting customer businesses because you're false positively on files that you you know that they actually need to run their their organizations um okay so just sort of well let me let me stop here um i think this is a decent breaking point and just see if there's any questions if i can clarify anything any comments uh please go ahead
yeah yeah okay so so the question was so so the colleague here um deals with machine learning compliance and and that kind of thing and he's asking um if we do any introspection into the machine learning models uh there are some well-known techniques like chap and lime that you can use to help explain machine learning predictions um he's wondering if we if we use those techniques um i mean i feel like i should really defer to my team here but just for great for con convenience i'll just say just because i'm up here um basically um we trust this validation process much more than we would trust like a lime explanation as to what our model is
doing the issue with so with any of these explainability approaches i would say and this is this may be a controversial position i'm not sure but um is that they are models of an opaque model um and as such well they are interpretable models of non-interpretable models right um and so like when you so so let me explain like how lime works for example so lime um it fits it it fits a linear model to to the predictions of a non-linear model and linear models have this nice property that they're basically summations so like so if i was to fit a line model to our pe model basically what i would read out is that oh these three features
seem to be contributing to the pe model deciding this is malware or not now that might be really satisfying to see that the lime you know this this line model you know gives this interpretable explanation whether it's really true or not not sure it's a linear approximation of a nonlinear model right whether um that explanation generalizes to a new example that lives on some in some other part of the feature space who knows you know so we do use those techniques sometimes to make sense of what our models are doing but um with a lot of caution and um and with the sentiment that these are um shedding a little bit of light into the sort of fog of uncertainty that
we're living in but not you know not clearing the fog um and you know the the benefit of this process that i'm showing on the slide is that you know we're actually testing the models on um on the scale of millions of customers in silent mode and seeing how they would and actually seeing how they would behave were we to turn them on and just building confidence at scale rates so you know they're both important but yeah so i think that was a really good question thank you yeah question back there
so the question is do we implement our own models or are we using existing implementations um so we we use so um if the question is like are we uh computing gradients like from scratch like no right like we're using pie torch and that kind of thing um or like we use pie torch we use xgboost and we use sklearn those are like the main tools that we use in our team um you know on top of that we're building you know like in the previous slide i showed right these are there's lots of original ideas in here you know that we published as our own papers but yeah we're using the same toolkits that everybody else uses
for let's actually implement this stuff uh yeah please [Music]
yeah yeah that's a great question yeah so so the colleague here um asked the comment was given that we're using transformer models which focus at least the sort of stock form of a transformer model uh in the natural language domain just focuses on text a text document um are we also incorporating like email header features since those are obviously a helpful signal in the email domain um so yeah that was a really good question that was like that was like the question that we were pursuing when we um constructed this model uh there's i would say you can look at our paper on how we do that um but um basically this this very simple diagram shows that we
you know we are using a bunch of transformer blocks in our efficient detection model but then we also add in near the near the final layers of the model we add in a bunch of context features and we do we do find that that helps so we are using header features in conjunction with the text features thanks for the question and maybe one more question yeah please go ahead yeah yeah yeah yeah yeah so that so the so the question was about uh i was asking for more detail on our validation process um so like the basic we could spend a whole talk on on that that's a yeah that's a very good question i should also say i mean
i don't know probably two-thirds of our time on our team and the research team goes into setting up validation scrutinizing validations mistrusting our validations and questioning whether they're even accurate or not and you know this is that's that's a huge piece of all this um i mean one basic thing that we do constantly is time splitting so we we train it's you think this is a kind of historical simulation so we train a model up to some time t and then we pretend that we had it in deployment and we looked at we look at data that we observed afterwards and we see how it behaved over time and also um in a raw curve or a precision recall
plot to show you know how it would have behaved over some time window and um anyways that's that's how that's that's sort of a standard design pattern for how we design basically all of our validations another problem is the timeliness of the labels so the more time you wait the more accurate typically the more time you wait the more accurate your good bad labels become so sometimes we go back in time and look at you look you know a year back or something to see really how well do we think this model is doing based on um based on that sort of time you know that what you earn from putting that time delta in
but there's no perfect answer i mean there's a lot of intuition and domain expertise that goes into this too um because it's cyber security and you're never gonna have perfect labels um okay i'm gonna keep going and so we'll have more time for questions um later okay so i i want to drive my points home hopefully not to the point of annoyance here but um so i just want to talk about some myths and realities and security machine learning so one i just think people talk about the math as though it's it's the main driver and it's really not it's all these other operational questions that we're talking about and that that came up um
delightfully and the questions that people asked just now uh that really go into driving accuracy like you need to understand the math and you need to be able to pick pick a good modeling approach um but that's like the easy part like the hard part are all these operational details like what the colleague asked about validation whether it's asked about introspection and understanding what your models are doing in the fields those are those are the hard parts um um i would say i mean we come up with the original ideas that we're proud of um but those those squeeze like a few percent extra accuracy uh out of out of a problem um really if somebody's claiming uh if like
a security vendor is claiming they've got some like fancy new math or something like that's they i think they get negative points for that um you know usually it's like the it's like the basic ideas really that um like if somebody's going beyond what's available on wikipedia um then you really have to ask why and they need to really show their credibility um you can do pretty well with with with already existing knowledge and also doing a really good job with operational questions um and then the final thing is i mean for a while people in industry and i think even now still we're talking about machine learning somehow superseding signatures or obviating and sock analysts and domain experts uh
obviating pat you know obviating block lists and allow lists the reality is those technologies are pillars of the way we do security today and as a security data scientist i'll say we rely on those tools as part of a broader ecosystem in which we integrate our technology so i think i've gone over most of this i'll just say so like a big problem is correct data labels i mean so if you're not so it's garbage and garbage out when it comes to these models if you're not uh labeling malware and benign work correctly um you're gonna you're gonna be way off in terms of the model you actually deliver to protect people if you are training a model on data
that's not representative of the networks that you're actually trying to defend it's not going to work it's not going to generalize to those new networks very well you really need data that that reflects the context in which you're deploying your model both the attacks and also the benign observations um designing a good evaluation that that accurately predicts how well your model will do in deployment is absolutely critical to machine learning security r d your team doesn't have a compass to know where north is if they don't know how well the model will do when you deploy it um this is a huge problem with a lot of security data science research and again you need these other
tools like signatures and a lot of this and block list to deploy machine learning um i wanted to i wanted to say a brief note um about why people ask us a lot about if whether or not we're addressing the the literature and adversarial machine learning um so for those coming here outside of data science adversary so there's a literature on what's called adversarial examples in in machine learning today and the idea of an adversarial example is it's it's it's a human crafted input to a machine learning model that's deliberately designed to confuse the machine learning model and give an incorrect prediction um and there's lots of fancy way clever and fancy ways that you can you can come
up with these these examples maybe some of you have seen for example pictures of like a school bus that looked like a school bus to the human eye seemed to be completely untampered but that a computer vision model will like just undeniably assert is a flamingo uh that's an example that's like an example of an adversary example now there are people doing work on this and and the security domain showing that you can craft say exe files that bypass a machine learning detector we currently as a practically oriented security data science team whose mission is to defend real-world customers today are not focused on trying to to defeat these kinds of examples um and there's a couple reasons
why um the first one i would say is that our machine learning systems stay inside of a big complex decision pipeline that involves a lot of non-machine learning layers um i think that the threat model that a lot of the adversarial ml literature focuses on in the security space really is just focus on the on the machine learning model in isolation but we're focused on maximizing accuracy over this entire detection pipeline and it's just not clear to me that adversaries will have such an easy time getting past all the other layers if they are adding adversarial sort of sugar to their malicious pe examples the other the other at least that's half the reason that we don't
focus on adversarial ml right now in our research group i would say the other half is just practical like we have so many other leverage points we need to improve on um to improve our models like some of our models we ideally ship them every quarter but they slip a quarter uh some we have data feeds from you know critical like you know in many of our models we're integrating half a dozen data feeds uh all in one place and we have data feeds just going out and maybe we don't notice for a couple weeks you know i mean in the practical reality of our team um improving all of like sort of moving all those other other levers just
has to take priority over this research um but i thought i thought putting the slide in there might just be a good point for discussion here because i know a lot of people in our community are interested in these these examples we read those papers we're just not focused on you know it's just not our top priority right now in terms of coming up with ways of getting around adversarial machine learning yeah just one second sorry to interrupt yeah yeah did you guys have any questions from your audience oh thanks that's really helpful thanks a lot um so in in security data science the focus of the discussion is usually on feature selection and mathematical modeling um
the reality is the life of a real world security data science team encompasses all of these nodes in this kind of placemats map of security data science work that i've created here um you know to know whether you're doing a good job you need to know like you need to be able to have a good answer to the following questions where do you get your training data from and why do you think it's representative of the data you'll see on a real network how do you know what good and bad look like in your training data and your evaluation data these are all hard questions how do you fuse data from multiple sources to get the best
possible training and evaluation data um we need to know so for the algorithms you're using um i said the thing about wikipedia already but you know how did you design your evaluation how do you know that actually predicts accuracy on a real-world network um if somebody's presenting to you machine learning work they've done you want to see their evaluation if they if they're showing you accuracy numbers you want to know all of the nuts and bolts behind how they did that evaluation because evaluations are biased you also want to know um if somebody's proposing to you that they have a really good security machine learning system you want to know how it integrates with allow lists block lists
and signatures um there's all sorts of questions that you want to ask and then and then there's their operational picture so there's the question of how do you monitor accuracy and deployment um a lot of the efficacy of a system hinges on that uh how do you deal do you ever do procedures for dealing with accuracy crises with models that are out there in the field how often do you train and retrain your systems to make sure they're fresh reflecting the changing threat landscape these are these are all the questions that are sort of outside of the domain of like the math and the feature space that are really important to the actual efficacy of a
security data science program okay so last last section of the talk i want to talk a little bit about where and this is just my own opinion really like where security machine learning is going to go over the course of the next decade or so okay so i would say a key result in machine learning um thank you ten ten minutes okay gotcha a key result in machine learning over the last five years is this idea of neural scaling laws and so i want to i want to illustrate what that looks like and this is this is a source from a paper from google that came out i think a month ago so um basically the basic idea behind
neural scaling laws is that as we make neural networks bigger even if we don't have any more clever ideas even if we simply you know just scale up the width of the layers of our neural network um magic things happen uh so we do better on accuracy and even new capabilities emerge in those machine learning models so here's here's an example from a research team at google in which they trained a model to um it's funny as i said that my google assistant thing just came on now it's off um okay so um so this model was trained to take a sentence of natural language text so in this case a map of the united states
made out of sushi it is on a table next to a glass of red wine uh and translate that sentence into an image um and what what what they showed in this figure is that um they took the same model and uh and sized it as a 350 million parameter model so 350 million parameters basically means there are 350 million interconnections between like the neural units in this model and what came out at that scale was this sort of visual gesture at a map a weird kind of cubist red wine glass and like what looks like something vaguely sushi like over here so it didn't really work right um but then with with no new cleverness or no
new ideas but simply sort of adding adding scale to this model they scaled it up to 750 million parameters and then you really do see some sushi this looks sort of alaska like or i don't know my geography is not very good but you know it looks like some sort of map like and you guys have something closer to a glass of wine anyways point being by the time you get up to 20 billion parameters you really do have a map made out of sushi and you really do have a glass of red wine and you really do have a table um and so this is this is a really robust result that's come out of machine
learning research in the last five years or so that in a whole bunch of different domains as we scale neural networks up they acquire new capabilities um so here's another for data scientist audience you've probably seen this but another really powerful example so here another team at google's scaled a language model up to a ridiculous degree i think this is maybe somebody remembers better than me i think 300 billion parameters or something like that so absolutely massive you need like a room scale supercomputer to run this model but they asked it to do a whole bunch of parlor tricks which were really impressive one of which was to explain this joke um so the joke was
did you see that google just hired an eloquent whale for their tpu team so tpus are special machine learning processors that google's developed for the tpu team it it showed them how to communicate between two different pods and so then the model responds tpus are a type of computer chip that google uses for deep learning but pod is a group of tpus a pod is also a group of whales the joke is that the whale is able to communicate between two groups of whales but the speaker is pretending that the whale is able to communicate between two groups of tpus so it's really impressive right that the machine learning model was able to to give this description and this
same model has a whole bunch of other capabilities that are equally impressive and again what's happening here is google is using a model much like the phishing detection model that we're using um on my team at sofos but it's just at a scale that's truly massive and capabilities emerge when you when you scale models up to that degree um and so you can see i mean if you get into this deep this large model stuff you can find really wild results like here are a bunch of images generated by that google model i showed earlier when it's scaled up to 20 billion parameters and it just has an enormous visual vocabulary and it's able to see the
relationship between the vision domain and the text domain so these are all images that it generated based on textual prompts here's an example of a model uh writing codes based on the prompts many of us are probably familiar with like the the auto the copilot model from open ai that you can now use to do this um now how is this relevant i know i have a few more minutes so i'm gonna go really fast how's this relevant to cyber security um so here's an example that a colleague and i i came up with showing how you can use the gpt three large language model to categorize domains um so i gave it a prompt so i said list of websites and
their content categories and i gave it some examples like berkeley.edu it's an education domain amazon is shopping i give it five examples and then i give it a new example that was syntactically quite different from the previous examples and i just asked it to auto-complete my example and it auto-completed it as weapons so i got it right and so actually in our web detection technology right now we use tens of millions of examples and what's noteworthy here is we used we used five examples uh and showed them to gpt three um which has like 200 billion parameters and it just got the answer right right um so um that's impressive and it's relevant to cyber security here's it here's an
example from malicious domain detection so i give it four examples and i asked it to categorize a syntactically totally new domain i mean i just made this up it doesn't actually exist in the real world and it gets it right that it's batch right so i think i think these large models have something to offer us in terms of a kind of tactical maneuverability around our models i mean it took me five minutes or probably a minute to create this model and now it's detecting malicious domains um and that's you know right now there's all sorts of practical challenges actually using this technology in the field it's costly to do inference on gbt3 and all that
we couldn't deploy this at scale in our customer base but i do think this is a sign of what's coming in terms of the applicability of those large models um just because i only have a few more minutes i'm going to skip through some slides here um the other place and um i think i'm do i have time for questions after my time's up or i do okay that's that's great to hear so i'll go a little slower um the other place that i think security machine learning is going and needs to go is around a much tighter feedback loop between users and machine learning models um so the the the modality that we've seen around the deployment of
machine learning in in general in the tech industry um has been that users fulfill their intentions with products let's let's say google search is the product we'll use an example here um machine learning models in turn learn to anticipate and fulfill user intent so when you start typing into google um uh i don't know um restaurants in vegas like within the first three characters right it's predicting your query and oftentimes you know you don't have to type the focus i mean i almost never type the full query right you just you just click on the on the recommendation um and users have come to expect this kind of um collaborative relationship collaborative real-time relationship with machine learning and their
engagement with products and as a result of companies successfully implementing that more users use the product there's a sort of virtuous cycle between users using products products deriving trading data from that and products ultimately improve as a result of this cycle so we see that you know in recommendation engines we see that in information retrieval what we're working on in our team with the more forward-looking thing that we're working on is creating that kind of feedback loop in the security context um and so you guys will hear a presentation about that today um uh after my talk but um you know basically we we've got a team of about 100 stock analysts at our company that
actually protect our customers networks as part of a subscription service and we're sort of setting up that feedback loop between stock analysts and the alerts they look at and recommending alerts that we think they're going to find to be true positives um i'm not going to go too much into the results here um since i have two more minutes and you're going to hear about those later but we're finding that it's really efficacious and surprisingly um there are very few examples of companies deploying these kinds of systems yet in security and i think that security over the next decade is going to catch up to the amazons and googles of the world and creating those kinds of user ml feedback
loops but within security products and services um so just to reiterate some takeaways so with current ml security ml is both the last resorts because it's so hard to deal with for all the challenges that i because of all the reasons that i described but almost always necessary the math is usually the least important part it's all these contextual problems i think there's a real future for large models i think it's the role of security ml researchers to figure out exactly what that's that future is but i think i think those are going to play a part in security going forward i think feedback loops between users and machine learning are going to play a part um i think
adversary lml is an important area to look at going forward but today and in the short term isn't a priority it's all those other questions that i brought up um so thanks a lot and looking forward to feedback
so it sounds like we have time for questions so please go ahead
yeah yeah yeah so cleverhans.io is a good place to go to learn more about adversarial ml yeah thank you other other questions yes
so what was the what was the last part of your question did oh ci cds
yeah yeah so the question was if we have if we're using anything like a configuration management system with respect to our data engineering operation um i'm gonna look to folks my colleagues here from sofos and are you i don't think so right no no we're not at that level we're not that sophisticated yet
yeah yeah thus far i know but yeah let's talk afterwards and yeah yeah yes go ahead
yeah so the question is are we using stock analysis data labelers um so yeah so the folks sitting next to you actually are going to be talking to uh ben and darshan you're talking about that so yeah i mean like the answer is it's it's like yeah but it's like super complicated and and you can't just you know yeah it's complicated how you do that so yeah it's stick around in this room if you want to hear more about how we're doing that yeah okay well um you please one more question and then yeah go ahead
yeah so we have a paper out about so the question was about how we do detection on html and javascript i mean the short answer is we're doing it in a in like a traditional end-to-end deep learning way so we're not it's format agnostic the way we do it um and the representation is learned you know by a a stochastic gradient descents you know style optimization um but the the longer answer is uh i should share a link to our paper because we have a paper that describes the the method by which we do that that's it thanks so yeah i think let's uh disperse anybody who has any more questions come you can come talk to me or maybe my team
would be happy to answer some questions too because there's some folks from sophos ai here too so thanks everybody for coming much appreciated you
Related talks
 36:55
36:55 29:50
29:50 36:27
36:27 1:26:30
1:26:30 52:44
52:44 50:16
50:16