BSidesSF 2020 - Mistakes Made Integrating Security Scanning into CI/CD (Atul G • Moses S)

Show transcript [en]
we're about to start and Atul and Moses will talk about mistakes we made integrating security scanning into CI CD hello everyone how are you all doing [Music] thanks for attending talk and thanks for organizers for having us here my name is a tooth I work as a senior product security engineer at box and this is my first time at besides and I have Moses with me I'm a staff security engineer on the security automation team also a box not my first time at besides but I'm still excited to be here all right so today we are going to talk about the mistakes that we made while integrating some of the scanners in CI city pipeline
so as someone said that you don't live long enough to make all the mistakes by yourselves so you have to learn from someone else mistake right so so you want to learn about the mistake that we made let's do it all right story time so on one fine Monday morning our product security slack channel started showing up 100 plus different slack messages from various developers and they were complaining about their bill pipeline being getting failed and the reason behind this was because one of our security scanner it failed as the SSL certificate for that scanner got expired now idly our configuration management tool should have renew this SSL certificate but for some reason it did
not work and we also did not realize about the SSL expiry now even then we should have avoided these incidents if we had design a system that rules of the scanners in a fail open mode but unfortunately we did not have that design in place at that time also we could have narrowed down the overall incidence time window if we had put some good documentation on how to renew the certificate manually in the event of failure but we had a blind faith in our configuration management tool and we expected it to work all the time so when the event have occurred we had to talk to our internal security team and get a new SSL
ticket also reached out to vendor on to see how exactly we can roll out this certificate on the scanner so overall between like seven to eight hours our developers could not push any code whatsoever to the production so this so any incidence is basically chain of events and even cannot occur has or has a capability to cause any incidents by itself so all the in see all the events would work together to make an incidence now so before we go and show you the difference between our old model strategy of rolling out scanners to our new model and compare them both just to set a stage for everyone let's quickly walk through the DevOps methodology so
DevOps is not a tool DevOps is basically a software development methodology which is adopted by by development and operations team so in any organization you basically have this two teams one is development team and the other one is the operations team development team would write a code and give it to the operations operations would then test the code build the code and deploy it now in ideal world there shouldn't be any confusion any issues but these two teams always have a conflict of interest so the tool that or the code that works on development teams machine may not always work on the operations team machines also the goals for these two teams are totally different developers
was to release the code ASAP so agility is their goal whereas the operations teams they want the stability they don't want to break the system and to in order to establish a good collaboration between these two teams that led to a creation of a methodology called EPS DevOps so one thing is missing in this whole DevOps cycle anyone knows what it is any guess obviously this is a security conference that's why we are here right so security can be added at multiple different layers in this day up cycle so we could train the developers on how to securely write a code we could have a pre-commit hook to detect the code vulnerabilities right when the
developer is writing a code we couldn't even have a - scanner or ass a scanner detecting vulnerabilities in runtime so in this topic or in for this discussion we're gonna restrict our discussion to the CI security alright let's quickly go through how exactly this overall day of cycle works so a developer would commit a code to a version control system and this version control system could be a github bitbucket or any other software if there is any change detected in virgin control system it would be picked up by CI and city software's and then they will deploy this code to a testing environment or the test server on the test server you will have a bunch of
different software's like selenium which would have different test cases that would run against a particular code let's say for some reason a one particular test case failed it would error back to the developer and then developer has to fix that code and make the changes and the whole cycle will repeat now let's say if you're lucky there are no test cases that fail everything passed then you would push that code to the production so that's the basic understanding of a very high-level overview of how DevOps with device works and when security becomes an integral part of the DevOps it's called signal ops or dev succumbs so let's take a look at how exactly we added security in CI tool so we are
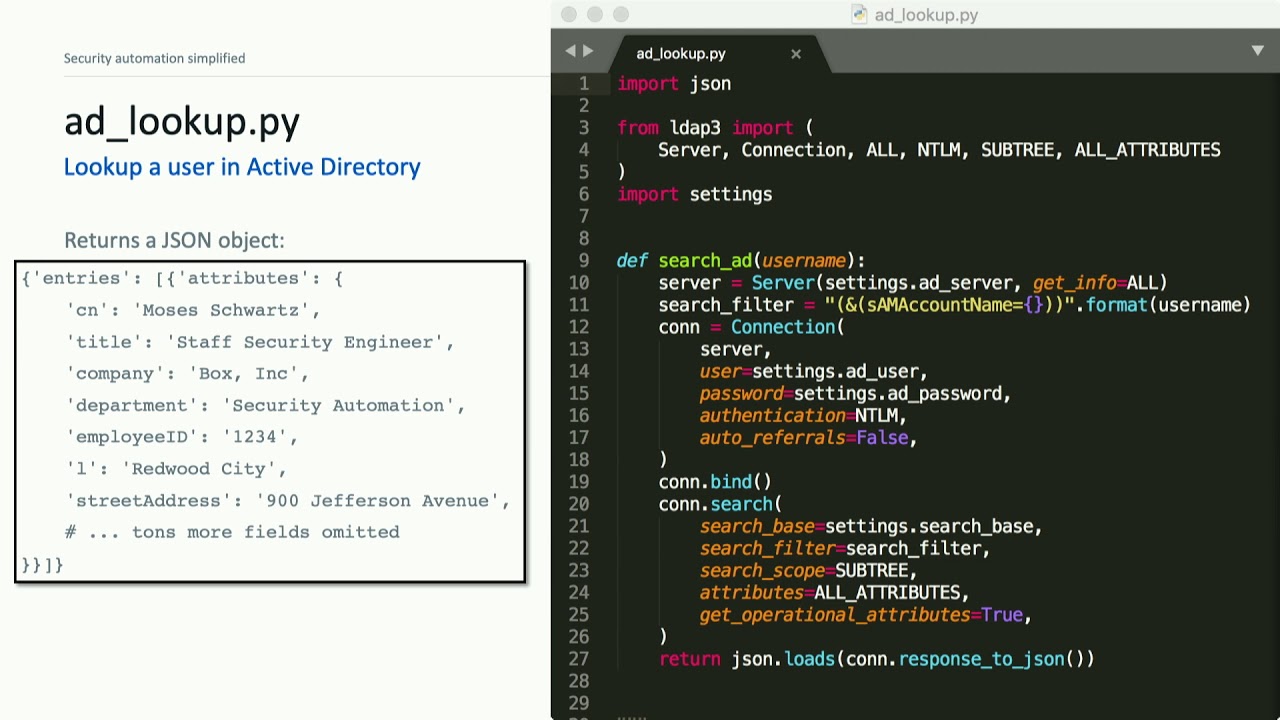
using Jenkins as our CI tool and as you see on the screen we have a jenkins file which is basically a text file that defines different stages that goes or runs as a part of the Jenkins pipeline so this stages could be prepare or build test deploy and in this case we have added a stage called security as a part of this stage we would invoke multiple different scanners as you can see on the screen we are invoking tool 1 then tool 2 and then 2 3 if we expand the definition of let's say tool 1 in this case you would see over ab c-- penney's check scanner being invoked which is again an open source third-party library
and that would find the issues related to a third-party library and you if you if you just take a look at the parameter that we pass through this ODC or a web subpoenas check scanner one of the parent parameter to notice or is critical is the pale on CBS s so fail on CBS s basically breaks the build if there is any one nobody with a CBC score higher than the predefined level identified will come to this particular parameter in a moment alright so in idle one everything should work without any failure if issues like SSS certificate happens then this system won't work other than that we have also also observed couple of challenges with this model the very
first challenge is having no standard way of indicating the stools if you're a if you're a Java or a Scala developer you would always look for a Gradle plugin for the tools also you can container eyes the scanner so you can have a shell script like we saw in the earlier image earlier slide that you can invoke a shell script and that would invent early invoker scanner so initially when we were rolling out this model we were pretty flexible with developer choice because we wanted to keep them happy but eventually that increases the workload for us because now we have to maintain different ways of indicating scanners also this model did not have a global switch so for
example if to any tool would stop working stop working for any reason then we don't have a way to disable that tool it also means that if let's say this tool is deployed to hundreds of pipelines then we have to make developer create hundreds of pull requests not ideal case then we don't have a central management the previous parameter that we talked about was a fail oh fail on CVS's which is a very critical and we want product security team to have a control of that parameter we don't want developer to have the control of that parameter because they might just tweak the parameter they might update it or they might set it to a value that won't
fail the build then the full challenge was having no metadata whatsoever so we don't know which particular pipeline invoke what - how much time our tool take and what's the performance then the fifth challenge was having no error log we don't want to hear about the complaints from the developers if there is any error we want to be notified ASAP and then act on it well last but not the least and very important is having no sleep product security team had to be on toes and with fingers crossed all the time and hope that all these tools will work but unfortunately that's not the truth so I'll hand it over to bosses now and he will walk us through how exactly
we solve all these problems with a new model thank you so but that's pretty much it for mistakes next we want to talk about how we solved these problems so I'm not aware of any product we could have bought that would have just solved this so we went right away to building something that was going to work for us address all of those issues that Atul just raised and above all ensure that we never break the build on accident again now oh by the way we we don't have the slides uploaded yet but we'll get them up right after this talk for everyone taking pictures so the things that we're kind of at the top of our
mind to the principles that we needed to address and build in from the start well we're yeah up on the screen we'll start with fail open so after we accidentally broke a bunch of builds that had to be top priority we can never break things on accident again we should handle errors we should let builds proceed if one of our scanners throws an error we need it to be usable whatever we build it's got to be easy for our team to maintain and it's also got to be easy for developers to put into their pipeline code or that their build pipelines it's also got to be scalable which doesn't mean that we need to be
able to scale to exabyte scale or anything we we're not really dealing with data processing here rather we need it to be scalable organizationally we need this to be something that can be rolled out across the organization we want this to be in every single build pipeline ideally with that kind of scale we need it to be efficient and again I I'm not talking about being algorithmically optic optimal just that it can't really slow down the build relative to total build times our security checks should be quick and not add a lot of overhead we want everything to be observable like a tool was saying we need error logging we need error alerting because we don't want our users
to have to report that something broke to us we want to get the error be notified right away that something happened and we want to manage everything centrally so if we want to switch to a new scanner or update something in a scanner we want to do it in one place and have that reflected across every pipeline that's gonna run these scans so there is a famous quote he attributed to David wheeler sometimes called the fundamental theorem of software engineering that any problem can be solved by adding another level of indirection so that's what we did we decided what we need to do is build a library that just abstracts all of that code to run individual scanners
into our own library and then push this out so that to to integrate this into someone else's pipeline all they have to do is import our library and run this run security checks function somewhere in there and that'll just be our entry point to kick off whatever code we want to add now we did this it in Jenkins as a Jenkins shared library that's what we use so it's kind of how we had to do this which has some interesting side effects we've had to write it in a language called groovy I'll get into that later but at a top level this is what it looks like all we have to do to get this imported into a pipeline is
import it with that library syntax and then at a stage to the pipeline that just runs that one function we did add another nod to fail open and to making sure everyone's confident we'll never break anything by also adding an option to override the checks without disabling it so it's not commenting it out but if you pass that emergency override equals true option the whole thing does logs that it happened and we let the build proceed so at the implementation level what how this works in Jenkins is that you set up your shared library through the configuration by telling Jenkins hey here's a github repo I want to call this security checks library and that then
makes it available for importing in any pipeline running on Jenkins then we have that run security checks call which is just going to call one of the functions that's inside that our repo so that repo has a couple big components and I'll go through each of these in more detail but basically we've got a file we called the config dot JSON that says what scanners we want to run for each repo and we've got a bunch of scripts to run each of those scanners similar to the one that we saw before for the dependency check so once our code is called what we do is we just parse that config file and then for each scanner
that our that we get out of it we write that scanner script to the directory we execute it we do whatever we need to with the scan results and then we delete the script and leave the build environment like we found it here's that config that JSON file we knew we needed something that was gonna be flexible and could be changed per repo or even per team or github organization so we set it up with this hierarchy where we define scanners for the baseline these get applied everywhere and then we can layer on top of that rules for an organization so first the Security org here we also enable other scanner and then we can go
down to the individual repo level and here we're actually disabling some scanner so this in this example we're only going to run other scanner on security slap some repo and yet another nod to we will never break a build on accident and this can be disabled if needed we have this disabled checks flag that will turn everything off if ever needed in our actual run security checks code and this is in groovy but we can follow the logic pretty easily without worrying about language details you can see we implement this call function that's gonna get invoked we print a couple things that'll show up in the build pipeline log let everyone know where to go if there's problems and then
we wrap everything in a try-catch block this ensures that if there's any error anywhere in our code we'll catch that error we will write it to a log and then we will just silently fail and let the build continue assuming we don't run into errors we just go and parse that config that JSON file get the list of scanners this is gonna be just a list of strings the names of the scanners then for each one of those scanners we're going to go execute the groovy function that implements that scanner get into that in a second but then we grab the result we log that and we're pretty much done at that point now I mentioned
a couple times I don't actually know groovy and I wrote this thing does anyone here know groovy yeah so we couldn't have this be a groovy heavy project or no one in our security team would be able to update this tool or fix things we would have a really hard time integrating new scanners because who wants to learn another new JVM based language it's actually got some cool language features but I won't even go there we didn't want to learn it so we adopted a model of using groovy to kind of glue together the pieces of our code and this is what we had to do to get it implemented as a Jenkins shared library
but all of our logic is implemented in Python scripts and bash scripts we had just have groovy run them with something like this run shell dot groovy function grab the result and return it back one of the nice things about this is that it means we could rewrite this library to run in some other build system pretty easily we just have to replace that glue code but all of our logic can be the same we can still use the same config that JSON file so to add a scanner in this in this example we have to have one groovy file that we add to the repo that's going to be named here example scan groovy but all that's gonna
do is call that run shell function that we just saw on the last slide that'll grab the script out of our resources directory write it into the environment execute it return the value and delete that file now you can put a little bit more stuff in there it's a really convenient place to grab secrets out of the Jenkins secret store if that's helpful but you don't need it like that's the only groovy you actually have to write to add new things to the scanner then we've got a shell script that we actually execute the scanner with one of the really common patterns is to just have that shell script pull in a docker image and run that in the build pipeline
that'll helps a lot with reproducibility because Jenkins does not make for very reproducible builds as it happens but it's yet another layer of abstraction that we kind of bolt on and then to enable this scanner to have it actually run on a repo we just add the name of that scanner the the name of that dog Ruby file somewhere in config that JSON so for development we would add this to some test repo and then we'd go push a build see how it runs then we could move it into the baseline and apply it everywhere in our config file so all that is pretty lightweight and not a lot of tooling around it but one of the
things that we talked about that we really needed is logging and alerting and metrics now if we were building this as like a product that we were going to try to sell to other companies we would have had to go for some kind of a really heavy weight solution where we have a way to aggregate logs ourselves fortunately we're not building a product we're not selling this we're building a solution for our specific environment which is a much more tractable problem and we took advantage of the fact that we've already got Splunk running on every system picking up logs forwarding them to a central location from which we can build dashboards and alerting so that that's what we do every where we
write logs we're actually just writing to something like var log security checks dot log and then that that's it for the library side then we went to Splunk and we build up dashboards we build up alerts that will create tickets or slack us when there are errors and we've got all these nice metrics we've got graphs makes management very happy it also has a really nice story about adoption of this library we can show you know how many repos have adopted it how many skins have been run it really makes for a pretty compelling story showing how our scanners are hopefully adding security to the organization so right now that's pretty much what we're running we never break a build ever
even if there are vulnerabilities at the moment but we do want to be able to break builds based on critical vulnerabilities so we are working right now on adding that functionality part of the the requirements before you build something like that is that you have to be able to manage false positives whitelisting things like that so for that component we're actually building out a workflow where we create a ticket in our ticketing system for each vulnerability and then in order to whitelist it we have a workflow built on the ticketing system side where you can set it to be a false positive that gets reviewed and approved wants to take it moves to that state we automatically call our scanner
API and whitelist that vulnerability and then closely-related with that we're gonna pull all of those tickets all of those vulnerability scan results into a panel inside the Jenkins build so that when you actually run security checks library in your build it can show you every Skinner that ran what the results were and if we broke the build it'll tell you why right there where you actually need the information this will simplify things a lot and it's a lot better than the situation where you have to train your developers that they have to go find a particular file that we wrote out somewhere with scan results or worse to have them go log into a scanner
server somewhere to get the results for this scan so there are a couple of takeaways that I hope people leave with I feel like almost nothing I've talked about here is very hard to implement programmatically it's I think it's really more of a pattern something that's pretty straightforward to do to add a layer of abstraction to run security checks in a standardized way inside build pipelines now centralizing how you run security scans is very important because you will run into a lot of cases like we did where something changes something breaks and it breaks every pipeline another example that we might have run into recently was that we needed to update a database and pushing
out that change to every single build pipeline that uses that scanner would have been a really big problem so we're actually migrating all of our to use security checks library it just it's really important to have everything centralized and to reiterate this isn't tied to Jenkins it's not tied to any of these languages you could implement this at a really simple level just by having your code in a git repo and containing some shell scripts and have your instructions for integrating into build pipelines to be cloned the repo and run a single shell script that gives you that entry point to you know run arbitrary code inside a build pipeline and from there you can do anything you
want we can use this object or we could even kick off some other tool that we use for scanning for depending what scanners to run so that is our talk I want to quickly thank Dinesh whose name is on the talk but couldn't be up here due to a change in employment situation thank you everyone for your attention I think we've got a couple minutes left one minute left so I'll be happy to take any questions we can fit in there first of all thank you for the great presentation I have been dealing with this problem for a number of years working with developers who want to integrate CIC security tools into their CI CD so this is definitely
something that a lot of people encounter and that's quite useful I'm have you guys heard of Salus it's an open source framework yes we have heard of it and we didn't opt to use it but basically I think it could have been integrated into our system in place of the code where we actually go and run the scripts like we could keep everything the same our logging the way we get it into libraries and we could just invoke Salus to do this the script running right yeah that's what I was wondering because I'm using something very similar we're using Seles I wondered why you guys went in this direction rather than using that we weren't familiar ourselves when we
started building it what once we were familiar with it I kind of said I'd rather write it as a Python about it great work thank you we also have a slider question if we could answer that or let me just read it out you have baseline policies and policies that are or grupos specific how have you organized app code in this repose what's an example of an additional policy yeah so right now we don't have a baseline policy but there is a scope for adding that as enough parameter as a part of the config JSON so this work is still in progress so we would have much more development in future including the policies all right thank you one more
question okay last question then we'll be out in the hall for a while as long as anyone wants to talk after this I was just wondering if you had shared a this code on github in your github or any of its been kind of so more concrete examples we haven't actually shared the code yet we do want to release it open source but haven't managed to push it all the way out yet they're kind of trying to I think it's a pattern and hopefully just talking about that is helpful but we don't want to get our code out there see if anyone else can use it so that's on the roadmap I'm sorry it's not done yet
all right thank you thank you [Applause]
Related talks
 23:04
23:04 20:40
20:40 46:38
46:38 47:24
47:24 30:48
30:48 27:37
27:37