Back to Basics: Using Descriptive Statistics to Study the Shape of the Internet
Show original YouTube description
Show transcript [en]
we are ready for our next talk it is back to basics using descriptive statistics to study the shape of the internet please welcome emily austin from census
all right hey everyone um thank you all so much for uh coming here uh to check out my talk this afternoon i really appreciate it i know you had lots of options for things to do um but you chose to be here and i appreciate that um also shout out to the it and like coordination folks for getting me hooked up with a with a plug-in like in record speed that was like the fastest it assistance i think i've ever had so thank you very much but um with that said i'm gonna go ahead and get started a lot to cover hopefully we'll get through it all in time for the the meetup uh so yeah we're gonna be talking about
using descriptive statistics to study the shape of the internet today so i'm emily i am currently a research scientist at census and i study all kinds of things on the internet i'm particularly interested in um things that have to do with security or security adjacent but the internet at large is kind of within within the scope of things that we look at prior to coming to census i was a security engineer and a researcher for about six years and was really focused on kind of the blue team side of things so detection response lots of incident response um really focused on those types of things and then i got my start in tech actually as an analyst on a data science team
where i worked really closely with folks in marketing and product and ux to better understand how folks were using our product at my company and this also included people who were doing unusual things with our product which is really anomaly detection when you get right down to it so it was doing it even then and didn't realize it here's a little bit of an outline of what we'll be talking about today um so i'm going to start by talking a little bit about census data no good analysis can can begin without understanding your data and so we'll talk a little bit about that and then we'll talk a little bit about some descriptive statistical methods that
will that will be useful in your exploratory data analysis adventures then we'll move into talking about the internet as a whole so this talk is actually secretly really the story of my getting acquainted with census data when i first joined census as a scientist and so i started really broadly looking at the internet as a whole and then we'll get into looking at census visible risks and vulnerabilities on the internet like you can't come to b-sides and not talk about some really cool risks and vulnerabilities so we'll be doing that and then what is probably my favorite section is looking at the internet's response to major vulnerabilities so we'll look at three high-profile vulnerabilities that
came out over the last year and a half and we'll look at how the internet responded to each of them and they're actually quite different and i think it's very interesting and raising some interesting questions about how we as a security community can get better about patching and upgrading and fixing these things when they happen and then we'll get into what i'm going to call the long tail so the long tail of any distribution often has very interesting things in it um you can find anomalous things weird interesting things so we'll talk about a few things there so let's start as i said by by talking about our data so census for those of you who aren't
familiar we actually have two products um one is our data product which i'll be talking about primarily today but we also have an attack surface management platform so this platform if you give us a range of ip addresses or a domain we can take that and use our attribution algorithm and look at all of this internet wide scan data that we have and identify things that we think you own on the internet and what we'll do with that in addition to reporting that to you will also identify any risks that we're able to see on those assets that we think you own and that'll come into play a little bit later but for now let's just focus on the scan
data itself so census scans the entire ipv4 space and you can see kind of the breakdown of how we do that and how we prioritize different ports here and this data is available at search.census.io if you go there in your browser and this is also in a data set so that's primarily what i'll be talking about what i'll be using today for analysis purposes so this is this is a very truncated example of the the bigquery schema for our internet-wide data set um so you can see uh host identifier and services there are two of the top level fields in our data here we have 11 of those and those actually expand into over 1100 fields in our data
so as you can imagine lots and lots of um interesting things to look at lots of sparsity in there as well because we collect different metadata about different services so poses some interesting questions when trying to efficiently query that data this is just a sample of what that data looks like um so this this sample actually isn't particularly interesting in and of itself but you can see we can you can query the data and get these types of things back so we talked a little bit about the data let's talk about methods for a moment so i am i am going to stand on a soapbox for a moment if you'll allow me um so over the last few years
there's been a huge embrace in the security community of data science and machine learning and ai and it's amazing quite frankly it's actually one of the things that got me into security the fact that these types of methods lend themselves really well to security types of problems so malware classification um bot detection these problems are all like there's so many interesting ways to apply uh data science machine learning to security problems but a fundamental building block that i don't think we talk about enough quite frankly um is the underlying exploratory data analysis and kind of all of the work that prep that has to go into building some of these amazing models and getting them deployed and not to
take away from any of that all of that is really really incredible but much in the same way that we think about you know you've probably heard people say well social media is like seeing everyone else's highlight real but you have your highlights and your behind the scenes i feel like we need to talk more about the the behind the scenes of machine learning and ai a little bit and so that's what i'll be talking about today i'm going to get off my soapbox uh but i think it's equally important and quite frankly i think it's cool as well so we'll start here um very simply um for those of you familiar with python pandas you will recognize this but
in this case df is my data frame or data set and these are some operators that i can call on my data frame to get sets of descriptive statistics about my data describe will give me things like min max standard deviation mean and then mode and median as well so pretty simple these types of things these values allow us to understand the shape of our data much in the way that you you can see here um so we can understand if our data is skewed a bit if if we have right or left etc um so if we know these things if we have these measures of central tendency we should be good right like we've described our data set and
we're good to go on right so let's do a little thought experiment so imagine i give you four data sets um and they all have the same summary statistics each of the data sets has an x and a y column and there are 11 observations or rows in each of these data sets and column x of each of these have the same mean column y also have the same mean and if you were to fit a linear regression to these they would also have the same regression line so they're functionally the same right like i could probably treat these data sets as equivalent where are the data sets and so i don't know if you're like me
this is a little bit hard to to chew through um the one thing that i guess stands out to me about this is the uh column x in the data set four i mean it's it's all eights primarily but otherwise it's really hard to tease apart what's going on in each of these data sets or at least it is for me if it's not for you i salute you and i would love to know your tricks and secrets um but for me it's a little bit hard to parse this so what we should do is why don't we plot them and see what happens so this is what happens um you can see in the left two charts
these both seem to be linear models um the one on the bottom left probably could be fit a little bit better but then the two charts on the right are arguably not linear at all and probably are they're very very different from one another and from the other two and so this is a famous data set known as anscombe's quartet um it was created in the 70s by a statistician who wanted to really emphasize the importance of not only describing your data through summary statistics but also um through visualizing it as well and so i mentioned this because most of what i'll show you in this presentation will be things like bar graphs area charts
there'll be some packed bubble plots as well and these are all things that have helped me understand this data a little bit better and so i share this with you to say that it's really important to visualize your data it doesn't have to be beautiful it doesn't have to be fancy but it can be very functional and also very helpful so before we move on to actually talking about the data i want to leave you with this this quote from john tukey he's a famous statistician from the early part of the 20th century and he says exploratory data analysis is an attitude it's a state of flexibility and i love this quote because it just
kind of screams like just go with the flow like follow the rabbit holes look at the interesting threads in data and just follow them and i think it's no coincidence that many of the best analysts and researchers i've known are actually quite creative and so i would say keep this in mind exploratory data analysis can can often be very creative and very fun if you're willing to kind of dig a little bit and follow those threads so now let's talk about the internet as a whole hop in your time machine for a moment and come back with me to 1969 when the precursor to our modern internet was the new hot thing the arpanet with its four nodes
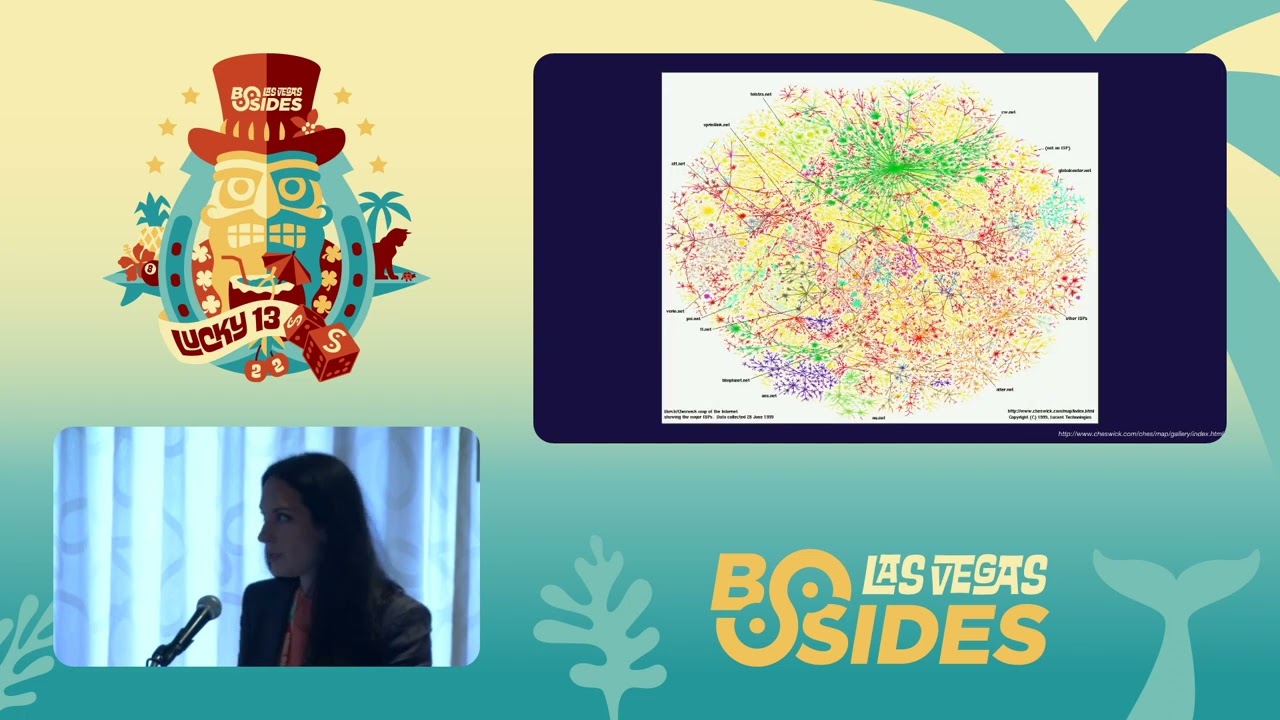
connecting several research institutions um so it's kind of nice to remember these sort of humble beginnings i think and then fast forward 30 years to 1999 and this is from uh the internet mapping project and it's showing um relationships between some of the major isps and you can see that even within 30 years there's been like from 1969 to 99 there's a tremendous amount of growth and change on the internet there's actually um a paper i found from the late 2000s that suggests that um the internet the internet's growth actually follows moore's law and will double in size every approximately like five years or so and this is in relation to like autonomous system connections so kind of
mind-boggling if you think about that um so we can look at the internet now um this is a look at different hosts or essentially ip addresses by city in the u.s um and these the the hotter regions here represent like hundreds of ip addresses um so we've come a long way from those four nodes on the west coast where i guess we're technically in the west right now but we've come a long way from those four nodes and uh i think that's pretty cool like that's really interesting and so now i think it makes a lot of sense to to look at well what's on the internet right so i won't show code for every one of
these examples but i do want to orient you just a bit to what i what i'm looking at and what i started by what i started looking at um again this is python pandas in a jupiter notebook um just reading in a csv and you can see here on the bottom like the different uh fields that i'm looking at so this is a data set of um service name port and service count over a series of dates from june of 2021 through may of 2022 with uh several different snapshot dates in there so if we look at the number of services that we actually have in this data it's quite a lot i mean well a lot is
relative i suppose when you're talking about the internet this is really not a lot in terms of the internet but 106 is a lot to start with so i wanted to just kind of look at maybe the top 20 and start there because again i'm new to internet measurement research uh as of this year and so i really had no idea what to expect so i was like i'm gonna buy it off just a little bit of this and get started so here we can put this data into a cross tab and essentially compute percentages for each of these dates that are columns we can compute what percentage each service represents for each of these dates
and then we can plot it because quite frankly this is a little hard to to make sense of so here's what we get um and i'd like to direct your attention to the fact that this is not actually a bar chart this is a time series heat map so as you can see http is really really dominant um in fact it's 81 of the services that we see on the internet or did during this time period so it's a lot um but the thing with this so this is like a whole this http is a whole order of magnitude larger than anything else that we're seeing so i want to kind of dig a little bit
deeper because i can kind of make out some different uh different variations of color here but it's really hard to pick apart um so if i take out http here's what i get so now we're kind of dealing with things that are a little bit more on the same order of magnitude and this is from snapshots uh of about 220 million services for our 220 million hosts excuse me for each of these dates um so you can start to see ssh smtp ftp these are these are pretty popular services that we see a lot of on the internet um but just for relative comparison's sake uh http i mentioned is about 81 of the services on the internet
ssh is three percent uh at least in this data that we saw so to give you an idea of kind of uh scale and proportion but let's go back to http for just a moment um because any time you're dealing with a data set that is so like has such a tremendous like chunk of things that are all one flavor it's probably a good idea to parse them apart into uh finer details right and so this is just a dashboard that i put together when i was exploring this data to better understand http kind of on the internet um so this this map here in the top left represents where http services run just by counts um you can see that the us
obviously have a ton china and germany actually it's a little hard to make out with the magnitude of the us but also quite quite popular there uh in the top right is just distribution of ports where we see http run and then on this bottom row in the far left corner we actually joined up our internet wide scan data with a data set called asdb it's a project out of stanford university and it categorizes autonomous systems into different industry buckets um which makes it a little easier to kind of compare things over time and also to each other and then in the the middle and bottom right of these corners are well of this row
you can see some of the different vendors and products that we see so yes um http is web servers websites um but there's also things like proxies and caches um load balancers apis so http lots and lots of different things run on http i hesitated with whether to share this set of graphs but because it doesn't actually show anything quantitatively it doesn't tell you anything quantitatively about these different services but so just to orient you here so for each of these um for instance we'll look at ssh this large bubble represents the proportion of ssh services that we see on port 22. you can see 22.22 much smaller but still larger in size than a lot of these others
so it's it's the proportion of services running on a given port and i say i hesitated to show this but i realized when i was going through and kind of doing this first pass analysis this visual actually really helped me initially to understand kind of the way some of these top services are distributed on the internet so http kind of runs everywhere in fact of the 65 535 ports we see in in this particular snapshot of data from march 15 we saw it on uh 65 532 i think so it's quite literally everywhere and i'm sure had i picked a different day those other two ports would have also been represented but you contrast that with ssh and ftp
and you can see that they are much more commonly run on their iana assigned or signed port and then smtp smtp is kind of a whole other thing too because of like secure smtp deprecation reports and that kind of thing but either way i think again this kind of speaks to the power of visuals i think so 27 million ssh instances 75 of them run on their assigned port um and this is just from one snapshot date by the way so this is one date that we see this many ssh services so kind of digging into this i was like well maybe it makes sense to look at ssh versions because that's that seems like
an interesting thing to look at and you can see open ssh obviously really popular but if you'll notice down here so this this data is at the open or at the software level so each row represents a different software version uh with the total number of observations of it that we see in the right column and if you see the bottom of the slide we apparently see 179 000 different flavors of ssh which again i'm not an internet measurement expert and certainly was not at the time but that seems a little weird to me um so remember that we'll look at that a little later for now we'll look at the most common ssh versions again trusty bar plot like
who doesn't love them um so i'll point out that this graph is also log scaled um but you can see like open ssh is really popular this is probably not surprising to most folks in the room um and i think kind of uh the good news is like these are these are mostly newer versions right um it does it's not until you get to like down here where you see open ssh like six something i think those were released in 2014 which may be a little older um but you know not too bad overall so let's look at ssh ciphers next um and this to orient this is actually out of percentage of total instances so
most of these um 75 of these actually are either an aes algorithm or a poly1305 however um as of march 15th when this this particular data was was collected we see a whole lot of triple des still out there um which is a little bit interesting because that was deprecated i think or suggested to be deprecated in 2017 i think um and that's like 10 million services that are still running that and you can also see some blowfish over here which again has been deprecated in favor of two fish i think um so overall like 75 of these are pretty good but like we could be we could be doing better with these these millions of
services [Music] so let's shift a bit to looking at ftp talked about ssh we kind of you know grazed the surface but that's okay this is exploration um 91 of ftp that we see is on port 21. however when i was looking at this for the first time i realized that about three percent so the next most common port that we see ftp running on uh is 4029 and i thought well you know being again new to internet measurement maybe this is just some obscure service that i don't i don't know about like this is probably just a thing right so i went to census search and i do this a lot where like i'll be querying data
in a sql database and then i'll kind of pop over here to just sort of dig and poke at things via a ui and i looked for ftp services running on port 4029 the thing that immediately stood out to me is that almost all of these are on an alibaba cloud autonomous system um which i don't really i'm not really entirely sure what's going on there in fact if anyone here knows or has some theory on what that might be i would love to talk to you afterwards because this has puzzled me for a while um and i even i looked i i kept digging and so like port rangers used my microsoft i did notice that
anecdotally a number of those ftp services did seem to be i think a microsoft flavor of ftp if i remember correctly but still really odd and i'm just really curious if anyone has any thoughts about that i would love to talk to you afterwards because that's kind of strange okay so we've talked about um services on the internet let's talk a little bit about where they run this tweet lives rent-free in my head i think about it a lot and i find it really funny because there's a lot of truth to it but also there's a lot of nuance that makes it not so true so let's look at that so this is a graph of hosts and services
by autonomous system this is top 20 or 25 and uh it's sorted by hosts and you can see you know amazon is at the top and i'll point out this is just one of amazon's autonomous systems there's another one somewhere down here um and there are others as well these are these are not all of amazon's autonomous systems there's lots of them um but then we can also look at this sorted by services so instead of just looking at in this case host being like an ip address we can look at services so services would be like ssh ftp etc amazon is still at the top this particular as but you do see a little bit of shuffling right so like
ovh and you see some other cloud providers like i think digitalocean appears down here you can kind of start to see that and how some of these cloud providers do tend to run lots of services on the internet um but one thing i'll point out is in looking at um amazon google microsoft cloud and i think i believe oracle as well um only about nine percent of things on the internet nine not ninety nine run in one of those clouds and so there's this idea you know going back to the whole thought of like the internet is decent the web's decentralized and then usc one goes down and everyone's losing their minds and it's trending on
twitter and oh my god the world is ending but i think it has a lot to do with the fact that it's popular things things that are integral to our everyday lives that are actually in these clouds and increasingly so that makes it feel so impactful when some of these go down so i would argue that the internet itself is not quite as centralized as some people are kind of maybe making it out to be um but rather that it's it's it's about the content of what we have in those clouds rather than uh the spread of actual services so now let's talk a little bit about risks and vulnerabilities on the internet
so we chose a couple of dates about six months apart and sampled two million hosts from each of these dates from our universal internet data set so it's total of about four million hosts and then we ran each of these hosts through this risks engine that powers our attack surface management platform so remember i mentioned earlier how we'll we'll find your assets but we'll also find risks on your assets so this is this is that same technology but we just used it for a slightly different purpose um before moving on i do want to throw out two caveats about the data i'm about to show you so i very carefully uh said well not on
the slide but it very carefully said at the beginning that this would be census visible risks and vulnerabilities and i want to put that caveat on here because for us to see a risk or a vulnerability in the way that i'm about to show you there are two things that have to be true the first of which is that there must be some public internet facing uh artifact that we're able to see from passively scanning the internet to be able to detect something so for instance maybe it's a banner that says hacked or maybe it's a software version we're able to discern from passive scanning uh that will show us you know that we know is a
vulnerable software version so it has to be something it's public internet facing and then the second thing that has to be true is much in the same way that an ids or an ips can't fire without signatures we have to have a fingerprint written for a particular risk or vulnerability to to have it included in this data i'm about to show you and so as of as of now i think we're around 250 or 300 different risk fingerprints i think it's closer to 300 but i would keep that in mind and i will say so there is definitely some bias to this data which i think is really important to acknowledge um that this is
in no way everything on the internet it's what we're able to see and what we're able to capture so we group our risks and vulnerabilities into kind of three categories you can see them here i won't i won't read these definitions to you but i'm curious by show of hands um how many people think misconfiguration is the top risk on the internet i'm gonna ask about all of them so okay how many of you think that exposures are the most like the top thing we see on the internet okay how about vulnerabilities how many of you think vulnerabilities are the things we see most of okay all right i'm gonna i'm gonna give you a
cliffhanger here for a moment and just talk about the risks themselves so you'll notice yes there are lots of exposures here um there are lots of eol or end-of-life software on this list again this is a function largely of what our data is good at seeing because we're not a vulnerability scanner we don't attempt any kind of uh intrusion or like we don't attempt to access anything this is all passively scanning what's out on the internet and so i want to talk through like these top three because i think they're kind of kind of interesting so the first two actually um the first two being missing common security headers uh so missing like content security policy and then
self-signed certificates uh just self-explanatory um i don't think they're hugely concerning in and of themselves right like we actually assign them a risk uh severity of low i believe and it's not that they're not problematic it's just that on their own they are probably not going to be the thing on their own like not chained with anything else they're going to get your crown jewels taken from you right they'll probably be chained with several other things to make that happen i will say that if i were like an early security hire at an organization and i saw lots of like flags for this kind of thing like no no security headers lots of self-signed certificates that would be a sign to me
that perhaps other security concerns might be sort of flying under the radar and so while i wouldn't necessarily think that those were the alarms they would be little little small red flags maybe pink flags if you will um that would make me think maybe i should go talk to the dev teams and kind of see what's going on however uh unencrypted weak authentication page is a risk i want to talk about so this specifically refers to authentication or login pages that do not use tls so everything is transmitted over http and they use either basic or digest auth so they're sending credentials over the wire either plain text or md5 hashed which is no one should use that for security
purposes ever it's like base 64 encoding um so really insecure ways to transmit credentials this is actually a really huge problem in my opinion so credential theft is is not going away it's very old tactic but it's not going away you all of the data breaches all the things for sale on the dark web or on these forums like it their credentials their stolen credentials um in fact the 2022 verizon data breach investigations report actually names i believe it's stolen credentials as one of the top threat actions or action varieties rather that they see in breaches and incidents and so i want to point out like this is still a really common problem and it is
not it has not gone away um and so this this is something i would want to fix like that's something that i would be digging into very quickly okay so here are the numbers i i gave a little suspense there hopefully um here are the numbers for the different categories of risk that we see and the relative percentages they make um so for those of you who said misconfigurations were the top thing on the internet congratulations you are correct they represent about 60 percent not about they represent 60 of the risks that we see on the internet um exposures are 28 and vulnerabilities are 12 again i will say there is certainly some inherent bias in this data because of
what we're good at seeing and detecting but i also think that this is a really interesting perspective because we make a lot of there's a lot around there's a lot of noise there's a lot of words are hard there's a lot of noise around um about like zero days really hot vulnerabilities really cool technical exploits and i mean they are cool i mean i love reading about them too but the reality of what is actually going to get a company breached uh is probably very different particularly like if you look at this data as as evidence of of where the problems are right so while the vulnerabilities are really exciting to talk about i think it's probably more likely that
security hygiene is the thing that's worth investing in uh long term overall so now let's talk about the internet's response to some major vulnerabilities so this is an area chart that shows the internet's response to the log 4j vulnerability this line represents when uh the disclosure happened and you can see almost immediately so these snapshots are there access shows bi-monthly but they are monthly and you can see almost an immediate like sharp trend upward in terms of not vulnerable versions as dark or purple and you can also see a sharp decline in vulnerable versions so people really jumped on this i mean it was everywhere it was a terrible time to be in security operations or in security or in it or
quite frankly if you're in software engineering in a small company it was just a really bad really stressful time um right around the holidays and so people responded to this really quickly and again it was very severe so it made sense that people would would take it very seriously and it was also everywhere god i think we're still finding places where it exists so let's contrast that with um the internet's response to this gitlab vulnerability it was a remote code execution vulnerability and the actual disclosure happened a month before the data on this chart begins but what i'll say is you can start to see like um this dark purple that's not vulnerable you can see there's like a
steady trend upward we're good we're good we're good we're patching things are happening and then we get here this is november 3rd when there's a tweet that goes out um a tweet that goes out that's that's saying that hey this gitlab vulnerability is being exploited and used in a botnet that's ddosing people and then people started paying attention people were like oh we got to fix this and so you start to see this curve trend a little bit more sharply upward because people are like oh this seems like a big deal it caught on it got popular um which is which is something we'll talk about in a moment and then finally for this section um i
want to talk about the confluence vulnerability um so this was um an ognl injection vulnerability um and it was disclosed here i believe this was in may i'm totally misremembering uh in august i'm sorry this is in august and so again you see very quickly um things start getting getting patched but what's really interesting to me about looking at this data for confluence which might not have been as immediately obvious if i had not like graphed this is there's a whole lot of empty space up here because people took confluence servers offline as a response to this disclosure which makes me wonder who is out there running confluence just like as a hobby like or i mean are are
they do they just like have them floating out there and they're like oh well now it's vulnerable i guess i'll turn it off like i don't really need it anyway like what's going on there i think this is a really interesting phenomenon i'm still not quite sure that i've wrapped my head around the reasoning why but there are a lot of differences in the way these responses happened right like we looked at the curves we kind of talked about time to like patch after the disclosure um you know log4j was immediate uh git lab took a botnet to get really really popular and uh confluence just sort of people started taking things offline things just went away because no one wanted
their confluence servers anymore i guess so for whatever reason when i think about these things i always think about like untangling like lots of tiny necklaces that are tangled together because i think there are a lot of elements to pull apart with what's going on here and what caused these responses to be so different so this is a screenshot from google trends for log 4j and you can see that it hits its peak right there um around this is in december well in december it got really popular it hit peak popularity per google trends which i'm not saying this is like a super scientific way to look at things but i do think for kind of measuring general
like societal awareness or curiosity about things it can be useful and then compare that with uh kind of a similar thing for the git lab vulnerability and you you do see a little bit of a jump here when when it was released in may but it doesn't actually start to get traction it doesn't hit peak until much later that year this is actually in december which is like a month after that tweet went out talking about hey this is being used in a botnet um so i think there are a lot of different elements that go into this um i'm particularly interested in looking further into like things on twitter as far as how those relate to um
to how popular vulnerability gets to how much awareness gets uh brought to it because i think there's there's something we can do better as a security community there i don't know exactly what it is but the variety of responses in all of these they were all pretty severe um log4js arguably probably the worst um but it's interesting to see how people respond to these things differently in aggregate so now i'll get to the long tail i had to cut this to just one example because i wanted to make sure there was a little time afterwards um but i mentioned you know before i think i talked about um 179 000 versions of ssh software seems real weird to me
um so i started looking at the tail and you can see like none of the these are these are not real this is not real um this is i actually don't know entirely what this is this could be a script gone awry this could be something broken these could be hacked instances of things like possibilities abound but there are several thousand of them in this data set so there's that um and i was like okay well let's look maybe at just open ssh versions of which there are also a lot in this data set but you can see that there's also some weirdness here open ssh hidden open ssh mock um welcome lots of really unusual like some too
many spaces like just lots of weird things going on here and so i was looking at this i was actually just looking at this manually um kind of scrolling through and seeing what what was what was out there and i found this so i found this in march of this year the current version of open ssh in march of this year i believe was 8.9 uh open ssh 9 got released in april so this this is like this doesn't exist so what is this um so a colleague and i started kind of googling around and trying to figure out like did we travel to the future what is going on here so we found this
um from like five years ago so this has been going on for for a while um or someone reports finding something very similar like they've done an nmap scan and they're finding like open ssh 12 and they're like wtf that's weird and one of the top or the top answer rather is that this is deliberate this is a thing that someone's actually broadcasting for some reason i'm not going to speculate as to why um it seems to be associated with a particular firewall vendor who may or may not be interested in not broadcasting their ssh version to the internet to pen testers to whoever um i won't i won't i won't go into that but
there are theories on why this might be the case um but i'll point out that like things like this are they abound on the internet the internet is a huge huge place and this is just one tiny example of something that we were able to find just from kind of digging in and looking at kind of getting away from the bulk of services and the bulk of things and looking at things kind of the the end of the tale of the distribution um okay so why does any of this matter who cares this is what does it mean so i think there's two main things that i hope you'll walk away with from this and the first is that
really good exploratory data analysis or descriptive statistical analysis is critical for asking better questions doing better analysis building better models um it's really important like you can't you shouldn't build models on top of data that you don't understand you absolutely can but this is one of those we were so consumed with whether we could we didn't stop to think whether we should you shouldn't um because that exploratory data analysis gives you a sense of you know what to do like you're going to run into missing data you're going to run into issues with it and so what are you going to do in having the context around the data set itself and kind of understanding how common these things
are within your data set are really important and then secondly from a security practitioner perspective one of the things that like putting putting my security engineer hat back on for a moment um using data analysis like you don't have to be a data scientist or an analyst to make use of things like this and certainly i hope folks who are not in these roles are also doing this kind of stuff if you're a security engineer if you are a security operations center analyst or researcher um being able to look at data like this and figure out the important pieces of it and pull out things that are really relevant to you or to your organization
are really important because we know that now more than ever there's there's alert fatigue alert fatigue at this point is almost kind of a joke because it's just it is it exists and i don't know that there's any solution to it that's viable at this point and so being able to comb through data and figure out okay you know what i see that we have 20 vulnerabilities that are that are in with 200 vulnerabilities our pen test found 200 vulnerabilities um i am one security engineer in a mid-sized organization what do i do where do i focus well maybe i can look at what's being exploited in the wild maybe i can look at the most common
risks and vulnerabilities that exist on the internet and get a better sense of how to structure my approach and where i'm going to have the most impact early on um so i think i think it's it's a double-edged sword well maybe that's a terrible analogy it's not a double shot it's two swords it's like it's two swords two samurai swords because you get to know your data better it helps you prioritize things it's very helpful all around so thank you all so much for taking the time to come to this session i really really appreciate it um again you have lots of options for things for other talks you could go to so thank you for coming to this one
and i would also really like to thank the census research team uh so mark and himacha and mark and zakir i really appreciate all of you like research is a team sport none of this happens solo none of this happens in a vacuum and uh you know it really helps to have an amazing group of folks to like kick around ideas with and explore things together so with that i will leave you uh with these two qr codes which are certainly not sketchy at all um one of which is actually this i'm not going to spoil a surprise you can you can check it out but the one on the right if this data was interesting to you
looking at the internet as a whole looking at vulnerabilities on the internet if this is interesting to you keep an eye out for our 2022 state of the internet report so that's going to be coming out the first week of september and it's going to have all of this types this kind of data in it there will be some more stuff that i didn't even touch in today's presentation um but if you sign up now like you can sign up to get on the list to be notified when it uh when it gets released and if you do you'll be i think you'll be entered uh into a chance to win six months of our pro data which is essentially the
data that i've used to do all this analysis so that's i think that's a cool perk uh that would i would be super excited to have six months of that for free um and yeah i i i really appreciate you all coming out thank you so much and i won't hold you from uh the security data science meetup i know people are probably eager to get to that but i'll take i think i have a few minutes for a couple questions and then we'll let people let people head to that
hello it's not on is it on i think it's on i can uh so i was just i was just uh looking at the index index of the screenshots that you shared for the open ssh data and i i saw that basically for the open ssh your index was in the 600s and their count was already won so that made me wonder if actually that means that out of the 17 000 ssh services that you observed um like almost all of them have a count of one and you only have a couple of hundred with a count larger than one is that correct yeah yeah so so the question was pertaining to like how many of those ssh uh at the
end when i showed some of the tail of the ssh version distributions um so many of them were one like even into the hundreds they were just one of them and so the question is is it possible that some of like there's probably just maybe a few hundred real versions um i think that's probably the case i think that's i i would say all with almost certainty that that is probably true because i do not think maybe maybe i'm wrong i don't think there are that many versions of ssh software in existence um so i think i think you're probably right it's very much concentrated within like maybe a few hundred if that
hey good talk uh so on one of your slides you had a dashboard that you were using for some analysis i was just wondering what tool that was made with and what was the like data on the back end sure sure so the question about um the dashboard so that was google data studio um connects right into bigquery makes it kind of easy well easy again is kind of relative but it makes it simple to connect data into to make those interactive dashboards and then the data on the back end was a subset of our internet wide scan data that i had filtered down to just http services with some of those attributes on it and in fact i can see
if i can go back to where that was and look at that oh nope let's see wow
okay wow sorry that took a long time felt like a very long time um so yeah so on the back end it was it was literally just a paired down version of um that that internet-wide scan data but joined up with this industry data from asdb and then vendor product port and geolocation or like country level data those are all just things native to our data so i pulled those out into a separate table so i wouldn't have to query the whole thing all the time because that gets a little bit prohibitively expensive um so yeah just just an http table on the back end absolutely any other questions does anybody know what is up with the 40
029 ftp anybody anybody have theories please this is kind of like i just need to go sign up for an account and stand up some instances on alibaba cloud and see what happens i think [Laughter] awesome all right well thank you all so so much um and if you did not get to the qr code on the left that's actually just some some sample searches for census search and some resources for threat hunting with census it's really not malware so i'll leave that up but thank you all very much this is great [Applause]
Related talks
 22:29
22:29 24:01
24:01 40:29
40:29 25:51
25:51 23:26
23:26 49:17
49:17