GT - Security data science -- Getting the Fundamentals Right - Richard Harang
Show transcript [en]
so thanks everyone as he said I'm rich rang I am a director in sophist data science group and yet today I'm basically going to present you with a long list of lessons learned from the school of hard knocks so my background in addition to my academic background I've been at the intersection of machine learning Network and endpoint security for about eight years now at the moment I'm leading most of the new research within the sophist data science team these are projects that run on multiple scales from you know just one person all the way up to four or five people on a single project most importantly for the purposes of this talk I think I've stepped on just
about every rake there is in terms of running a project and so now I'm gonna tell you about them so you don't have to do the same so this is the Sophos data science team that's me in the top row if any of the stuff that we're talking about here sounds like it's up your alley come talk to me I am wearing a blue I'm hiring wristband we can stick you down in the lower right hand corner exact position to be decided over beers so this talk is going to be about sort of the process around doing a security data science process project so what why and how what I am NOT going to talk
about is a specific data security data science project that we attacked or a specific model framework or what the best you know ml framework is and why it's pi torch so I gather I'm supposed to give you sort of a key takeaway that I want you to remember and that has to be in the first three minutes so here it is what most people sort of think of as their as their job as a data scientist is spending a whole lot of time doing fun programming and fitting models and tinkering with stuff and yeah maybe there's a little bit of you know talking to the consumers of the model or doing a little bit of data wrangling or writing
stuff up for publication and stuff like that in reality this is what you should be doing most of your time should be talking to people talking to external customers talking to people within your group talking to other people working in the same field unfortunately most of the rest of your time is going to be sent wrangling data and cleaning it and then you do actually get to do a little bit of the fun stuff fitting models programming them using the latest greatest academic research over my eight years in this industry these you know this is the single best predictor of success for security data science project that I found know who's going to use that talk to those people have a
continuous sort of cycle of collaboration feedback and updating going on within your team and to the end users of your project so let's sort of start off with the why of all of this so we've got sort of you see different versions of this and this sort of this is a little ml centric but it applies to sort of more general data science analysis projects as well we have this notion that you know we have some data we train a model we do an analysis we make a decision we do some sort of validation on that check it against reality we deploy it and deliver it we handoff the report somewhat implements the decision and we go around and we
collect more data and you know and on and on and on and so this is all you need to know right start with the very first question what are we actually trying to accomplish here right so how is this model going to be used what kind of decision is this analysis going to drive can we just answer one question and then stop right is this a problem that I could solve with the Reg X right you know I know it is our god-given right just data scientists turn up $50,000 in cloud costs to figure that out but you know let's let's see if we can simplify the process so know what good enough is and then really be able to say in
concrete terms right what are we trying to do with this project so with that in mind we sort of go back to the cycle and now we've got some questions that we want to be thinking about as we move through these steps right what features what level of accuracy do we want to train it to what metrics do we want to use what ones have we agreed on with maybe our customers or internally where are we going to deploy it to who's going to receive this report how do we have to like phrase this analysis in a way that they can understand it and implement it and where are we going to get the table
from the data from how are we going to label it how going to curate it and make sure it reflects what we need so if you're coming to this from the data science point of view very often when you're talking to external customers they they don't necessarily know what they want or they may just want some of that hot new ML pixie dust that they can sprinkle on all of their efforts so in some cases you kind of have to be an educator right what are the trade offs you can offer what's realistic right so yes they want something that can detect you know zero-day exploits in encrypted network traffic maybe sort of bring them back a
little bit and tell them what you might actually be able to deliver probably the most important thing is get something concrete out of them right I need in order for this model or this project to be cost effective I need to be able to get you know this detection rate with this false positive rate or I need to be able to realize this much revenue from these customers or or whatever it is but map it to something concrete and measurable and negotiate that upfront so before we get into the how part of this presentation which is going to be the bulk of it you really should have sort of three questions nailed down so you
need to have talked with your external partners enough to know how your project is going to fit into the business somehow right a project that nobody needs and nobody can implement isn't something that's adding value for your organization the person who's receiving it should have a good idea of what exactly it is you're giving them and how to interpret or use it right what are the inputs that are going into it what are the inputs that went into it what's going to come out of this model or what's the decision that you're recommending and the support in the report and how should they interpret it or use it and then everyone needs to be on the same page as far as how do we
know when we're done what does this mean to be successful and how exactly are we going to measure it okay so the how part of this so these are kind of like six key things that I came up with as I was trying to to frame up the this process they're kind of chronologically ordered I know there's a lot of overlap between them you can probably debate like which you know maybe good feature should go under beasts under be scientific or something but just at a high level these are kind of a this is kind of how I thought it sort of split out so um data let's talk about data right this is data science after all so I have exactly
three quotes in the slide deck I have front-loaded all of them so you don't have to sit through them basically John Tukey said that just because you've got data and you've got a question doesn't mean that you get an answer Ronald Coase is the source of the follow-up to that that if you torture the data long enough you will indeed get an answer and then finally norbert Winer had comment that the best model of a cat is the cat right so if you are dealing with some sort of real-world data which presumably you want to ingest at some point the data you use in your project be it your analysis or training your model or you
know writing up your report needs to be as close as possible to the real-world data that you're actually using you need to get your hands on that upfront as soon as you can so things to consider in this especially if you're doing an m/l project are things like label distribution label bias data collection bias if you're collecting you know if you're doing a malware detection project and you're collecting malware from the internet that may not look like malware that's going to arrive on your customers endpoints so you need to think about how you're going to sort of align those two data sets in a way that you're going to get a model that answers the questions
that you actually want to ask so this is something I'm going to keep coming back to in these slides the security difference so how we what extra things you have to think about when you're doing a security data science project versus sort of a plain old data science project and in security right the bad guy gets a vote so they're trying to obscure labels they are adapting constantly right there's a cat-and-mouse game going on all the time and in a lot of cases it might not even be worth using data right I have a very lovely carefully curated collection of dos viruses right I'm not sure I want to train my malware model on those anymore
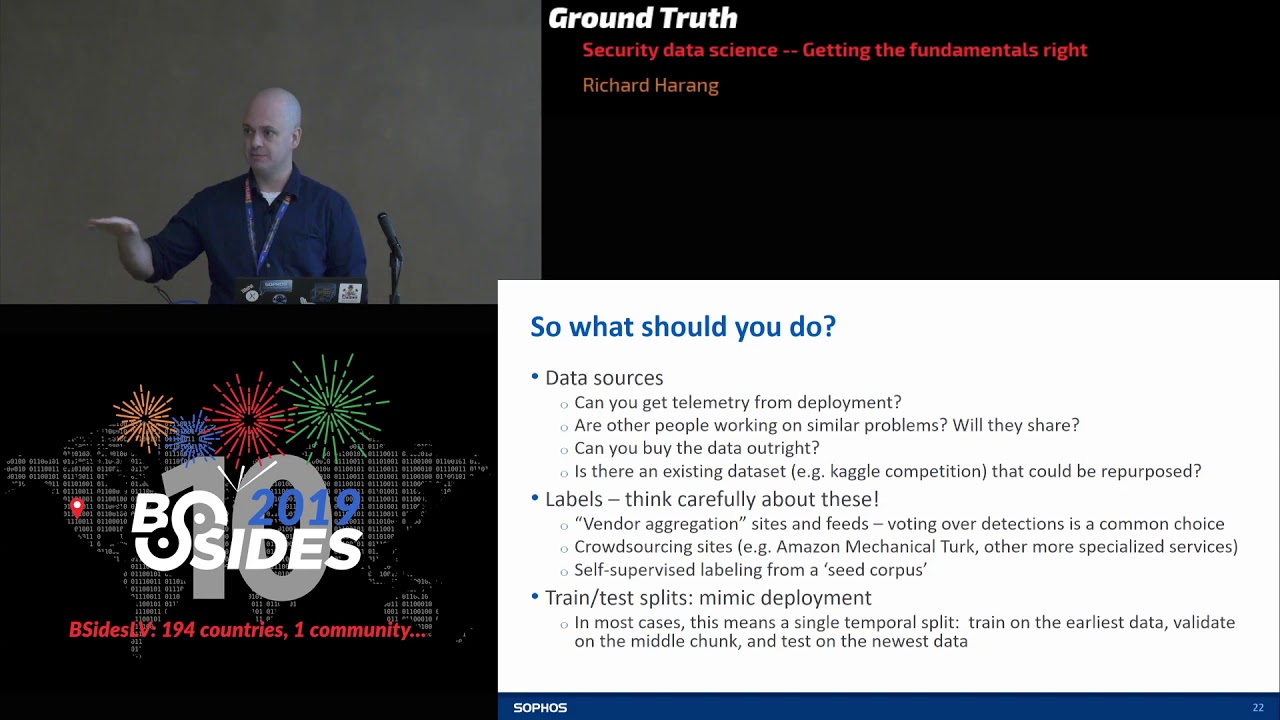
right I'm not sure that they're relevant so when it comes to data what should you actually be doing the gold standard is going to be getting telemetry from deployment if I can get real-world data that's my gold standard if you can't get that if you've got a like mock-up a proof of concept before they'll let you out you know the precious bits then there's some other things you can try right are other people working on similar product problems especially in academia this is sort of a criminally underutilized resource in this industry very often if you talk to an academic researcher working on the same problem and say hey I'm working on this to want to collaborate want me to cite your
paper they will fire you the data almost as fast as you ask for it so if you've got like an academic paper that's tackled the same problem asked there very often be willing to share sometimes you can buy the data outright you know for again for malware or maybe malicious HTML and religious URL problems there are a lot of commercial feeds that you can license and just start pulling in data from those sometimes their existing data sets that bearing in mind questions about label and sample bias you may be able to pull in and use those at least to bootstrap a little bit so again in the malware space Kaggle had Microsoft's malware data set which has you know the
header stripped from it so it's not perfect but at least it's a starting point if you're doing like web something with web-based detection you might look at like the common crawl data set which basically has tried to spider large chunks of excuse me let's try to spider large chunks of the Internet so look for other sources that you could maybe sort of adapt to your own nefarious ends especially in the security space labels are something to be very very critical and careful about a very common thing is is doing vendor aggregation so if you have like a threat intelligence feed where multiple vendors are giving scores for multiple artifacts doing a vote over those is a pretty common choice
but again academic literature is your friend here if you look up that process you can find a lot of papers that talk about different ways you might want to think about doing that voting crowdsourcing is another option it can be expensive it can be difficult to implement but once you sort of knock the bugs out of it it can be a very good way to collect labels for less sort of technically oriented artifacts you might want might not want to try it for like malware samples but for things like is this a phishing webpage or not you can usually get pretty good results finally you can go back to the machine learning literature and you can do things like
self supervised labeling from the stade corpus this can be buggy this can be a little bit tricky but it often gives you sort of a good head start on labeling data if you can form a nice small set of very cleanly labeled data when you're doing train and test splits or train invalidation splits because this is a cat-and-mouse game because adversarial samples change over time and what was mouth you know what was you know hot malware threat six months ago was note might not be won in another six months very often your train test splits need to mimic deployment which means splitting it temporarily so train on the earliest stuff validate on the middle chunk test on the newest data
if you don't do this if you mix everything up and you just do you know random k-fold you know fivefold validation you're gonna get wildly optimistic results because when you deploy it in the field you've basically trained the model to expect data from the future finally this is something I don't think I see quite enough talk about think about what data you actually want to keep right gdpr is a real concern you should be worried about it the risk of what happens in the data breach is a real concern you should be worried about it so well you know everyone talks about I've seen very you know different variations on this metaphor as security data as oil
security data is toxic waste my own contribution to the ongoing you know sir data is X let's think of it like plutonium right it can be really powerful you can do a lot with it it's got a shelf life and you know you want to make sure that you store it and handle it really carefully talk with legal early and often I am NOT a lawyer I don't even play one on TV but when you're talking about storing data especially stuff that has potentially personally identifiable information on it talk to your legal team early often and repeatedly a lot of times you can transform data so you can do stuff like tokenization or hash the features or
store extracted features that might not have the PII but remember the only data that cannot ever possibly be breached is the data that you're not keeping so think carefully about what you actually need to store and again talk with legal early often and frequently finally and so this is one rake that was particularly painful to step on when you have a good data set protect it it needs to be read only all right the the danger here is not that you're accidentally going to delete it no that's like the best case worst case scenario what you really don't want to have happen is accidentally modify the data in place not realize it for three months until you've been training on it
for the past three months and realize that all of your results are are crap because you've screwed up the data so when you've got a good data set you've got a nice labels for it its pristine it's beautiful store it under a different account and make sure that every other account that has access to it only has read-only access if you need to modify the data set somehow you should make a copy of it right local copy work with it separately so the next thing I wanted to talk about a little bit was internal collaboration have one way of doing everything important right never reinvent the wheel and make sure everyone on the team is
using the same tools frameworks and so forth you can get a lot from open source code especially if you're using are python there are tons of really good really well vetted libraries out there so sort of avoid the not invented here syndrome when you're doing a lot of these projects you'll find that it it they tend to sort of your code tends to sort of split into three different levels right at the very bottom level you'll have code that's specific to in a single experiment with an in project and so that needs to live in one place a little higher up the hierarchy you'll have stuff that applies to a given a given project but might
work for multiple experiments so that might be things like labeling code and then at the top level you'll have utilities that your entire group uses across a range of projects that top-level utility code that's going to be used over and over and over again you need to treat that as mission critical software engineering project right that that means you know JIRA issues that means code reviews that means change tracking version control the whole five yards metrics code deserves a special shout out if you if you are computing accuracy or area under the curve or f1 score or anything like that for any of your sort of output statistics everyone needs to use exactly the same code right
down to the same function the same commit every single time absolutely no exceptions the reason for this is two different implementations of the same function can give you slightly different results and when you want to compare the outputs of one experiment that Bob did to the outputs of another experiment that Alice did and they're using two different two different functions to compute something like area under the ROC curve you might actually end up getting that hey this looks better than this when the reverse is true so documentation I love this quote the only difference between screwing around and science is writing it down documentation I like to think of it as enabling collaboration over time not only within
your team but also with yourself it's a continuous process if you wait until the end of the project to do all of the documentation you are going to hate your life when you do your sort of group level utility code that always needs to be well documented when you have your final experiment that you're going to run and do the final analysis document that code as well when you pass it over even if you're just doing like a modeling project very like I'm just going to hand them a black box and all they need to do is use it plan on writing an F an after-action review so that in six months when you come back to
us no problem you know what you did why you did it what worked and what didn't work so keep some form of lab notebook as you go so that you can actually write that after-action report without going oh god what the hell did I do that one time so I'm not going to go through all of these I'm just going to say that these are questions that in a power object sorry obligatory plug hear it for the aloha paper that the surface native science group is going to be presenting usenix in a couple of weeks we actually went through all of these and we're very careful to sort of make sure we had answers to all of them and the result
was an exceptionally smooth sailing project so common dataset is probably the most important thing if everyone is training models on the same data on the same training data and testing them on the same testing and validation data you have no doubt that those results are directly commensurate and you can say yes this is definitely better than this other things like what are the right metrics that should come out of your conversations with your external partners just simple things like am I going to store stuff in JSON or CSV for like my experimental results documentation and like how to manage source code and how to structure your source tree so from their care and feeding of features and you can think of
this as also future combinations if you're doing like a data science e-type report instead of an ml model how often have you said one of these things to yourself I can't get anything to work I got it to work but then I changed something in the code and it wasn't under version control and now I can't remember what I changed and everything's hot everything's garbage or it worked great on my machine I don't know what the heck's wrong with the bo folks over in production a couple weeks of this and you kind of end up about here the way to avoid that is to heed well the five commandments of feature engineering so step one is always always
always talk to your domain experts right this is I think this was brought up yesterday as well talk to domain experts heed well their advice feature extraction is critical you gotta track it so when you extract feature so when you run feature extraction code you are not allowed to run it unless it's checked into version control when you actually extract features link those features to that commit when you run an experiment using those features link that experiment to those features that are linked to that commit and then finally when you're doing research feature extraction code have test vectors right be able to say I should put these three files in and I should get these three exact feature vectors
out write that down record it somewhere save it for later domain experts are generally pretty accurately named they're experts they are a great space place to start forgetting features typically a lot of like especially like your really experienced analysts will have sort of this intuition of ahead that just didn't look right right why did you flag this TCP stream I don't know there's something funky about it drill into that right ask what the first thing they noticed was very often they will have a well established carefully curated set of tools that they're extremely familiar with and can tell you exactly how to use very often these can be scripted very often these will be great sets of features they'll also know
they've been playing the cat and mouse game for years they will know how the bad guys are trying to hide from them ask them about that and very often those will actually be very good features themselves right PowerShell with a whole bunch of base64 with no characters inserted in it right got it stick it into a feature then once you've you know gone forth and you've constructed features and you've built some models and you're getting good results take those take that feature extraction code back to them and say hey how would you mess with this and prepare to cry better tears as they break it ten ways from Sunday so the security difference here especially for stuff like Pease or
scripts or things like VBA or what-have-you tend to fall under anti forensics and the subsequent parsing headaches so a lot of these things right that guys very often use and I reversing or obfuscation techniques which are very common in their stuff but within your total corpus of samples that you're going to be extracting features from might be comparatively rare so you know your feature extraction be could be merely chugging along through all of your files it's one of these obfuscated things or one of these things that's treated with anti reversing techniques and it'll suddenly crash or hang or eat up all of the memory on your box or or break in some other hilarious way so make sure
that when you're doing bulk feature extraction you've accounted for these weird edge cases and you can recover gracefully so you don't you know come back over the weekend and find that only 1% of your samples have been processed think about what you can do if feature extraction just cannot be done on some samples right do you can you use models or do analyses that handle missing values gracefully and then as new attacks new evasions new techniques come out go back and constantly revisit your features in light of that and finally when you have samples which break your feature extraction these are really great to set aside as test vectors right and so your test should be I cannot
process this feature or I cannot process this this artifact okay so once we're through that we're gonna put the science into data science and how we're gonna do that is step one obey well Occam's razor start with simple baselines linear models are great right simple naive Bayes analysis is an awesome starting point and sometimes what you'll find is you can just stop right I've run my random forests on it it works beautifully I talked with my external stakeholders a while ago so I know what my metrics for success are and I have hit them great move on to the next thing sorry you didn't get to play with your awesome new you know deep learning model if you don't if you
haven't hit that criteria then at least having a good baseline lets you know what you are buying when you pay the price of adding extra complexity in terms of modeling or future extraction or something so always start with the classics there are classics for a reason when your model may have based random forest decision trees they tend to work really well and give you like a good starting baseline so you can give a get a good idea of how you improve in the future so if we're being scientific there's a couple of important questions that you want to ask yourself can anyone who's working on this project right you got a couple of people all working on
the same thing can anyone reproduce somebody else's results right can anyone compare what they did with all of the results that have been logged however it is you're logging if you find a model that seems to do suddenly amazingly well or find an analysis that seemed to be incredibly predictive can you explain what's different between that and all of the stuff that didn't work quite so well and then when inevitably your project gets shelved and then six months later someone comes down and goes no no we got to do it now no no no now can you pick up where you left off can you figure out what exactly you were you know have you
saved enough state to be able to pick it up off the shelf and keep going with it the key - oh yeah so if you've answered yes to all of this then you need to go back and ask yourself this again and make sure that you're really sure that this is true so to get the key to all of this is some sort of experimental management framework there's a bunch out there sacred and m/l flow or two that we've experimented with and we've been happy with both of them but really what you want is you want to be able to push one button say you know run this experiment you know Python experiment Pi and then save everything and save it in
a consistent format and you've already agreed with the rest of your team what you're gonna record and how you're going to record it you get dependency information you get critical source code you get you know which features went with which feature extraction function and finally make it force you to write down notes I am doing this to look at I'm doing this run to look at this question and if you have all of that saved in one place then coming back to it in six months should be pretty straightforward so know when to shift gears so again when I'm doing these things I tend to sort of think of them in three stages of escalating complexity the first one is
tinkering I've got some problem I've got some data I'm gonna fiddle around with that I'm gonna try some stuff and I'm gonna see just what seems to work right do I have some good plots some good visualizations and some quick off-the-shelf stuff I can try so this is like done at a read evaluate print loop or you know in a Dru burn notebook or something like that once I've got some good candidates for what seems to be doing okay that's when you move to testing so you're gonna scale it up if I scale it up does it keep working are there particular variants on this problem that seem like they're worth full-scale you know full-scale tests so
at this point you should be splitting it out into scripts you should have some basic logging in place you should maybe be saving some artifacts manually and then you get into sort of the rigorous study phase and at this point you're doing testing almost at full scale this is where your hyper parameter searches come in this is where you're doing sort of more detailed analysis and really like pulling apart what you found in your when you're sort of exploration of the data and at this point what you really want is clean code version controlled in a framework so I am prepared to die on this hill Jupiter notebooks are great for starting out they're great for small scale
one-off projects they're great for reporting for writing reports for actually doing large-scale collaborative data science research I think they are kind of a disaster they make things really difficult so go ahead and argue with me we'll have beers or coffee or tea and and fight it out so do your experiments support your conclusions this is always a good question to ask right if I change three things at once I don't know which of those three things actually gave me an improvement very often there is a random element lot of analyses so if you're doing k-means clustering right where those means start can sometimes affect what your final clustering is if you are fitting a deep learning model how the
weights are initialized can affect your final performance so when you've got something that seems to be really good run it a couple of times repeat that experiment get some idea of the variance in these statistics that you're that you're reporting finally you need to be really critical of your own work before nature has a chance to do it to you so think about how you could have possibly screwed something up so do your data support your conclusions so not all metrics are meaningful if you've been talking with external stakeholders you should be beyond that not all measurements are precise especially when you're dealing with label noise and very often you won't have enough data to measure what you
want to measure and I'm sorry for the quality of this but I thought this photo was like too perfect not to bring up so this is a actual baseball game that I went to and you can see at 5:30 1 in the afternoon the right fielder had a batting average of zero just before he went up to bat at 5:35 after the right fielder has had his at-bat he now has a batting average of 1.0 what's the right number right so that was you know if you go back and you look at the stats it was obviously his first at-bat he got a hit so you know 100% of his at-bats he's gotten a run or
he's gotten hit so you know sometimes you need a lot of data to get a really good estimate of something and if you don't have it you shouldn't be reporting those statistics so again the security difference here is noise and drift you always in security are going to have almost always are going to have errors in your labels so you could this can very easily lead you to over or under estimating error rates especially if you've got systematic errors and your ground truth labels right my machine learning models are really awesome at picking out these dos viruses that I've had you know years and years and years to analyze and pull apart and disassemble that may make me overly
optimistic about the performance of my model because I'm never going to see those in the wild or almost never if I've got a 1% in my labels and I'm reporting a point zero one percent difference between two models is that really meaningful you've got a yeah that's it's make sure that your statistics are not being distorted by the noise that's in your labels and again adversarial drift or even just plain old drift is always a concern so think about you know can you measure how fast your data distribution changes over time think about if old data could be biasing your performance estimates and then especially in the security space as you start implementing solutions or
implementing detection models or taking action based on your security analyses you're going to change the data distribution right if you find you know here's all of these miss configurations we can now detect these miss configurations we'll go tell them to fix these miss configurations those miss configurations are no longer going to appear in your data so you've sort of moved that distribution of data okay so how to deploy without just throwing it over the fence these next two sections are going to be kind of short because they are sort of inherently company specific but I'm gonna try and talk about having been in a couple of places ways there are some common themes that have come up so I
mean you have been talking with your customer the whole time you've been working on this project right if as long as you have you should be actually in pretty good shape right they should know what the model what the analysis covers what the assumptions going into it are what sort of data is going into it what sort of results and conclusions are coming out and if you couldn't it now couldn't analyze some stuff where you just couldn't get access to some data or you think that there's a data bias you should have told them about that right they should know sort of what the potential red flag areas are for this and where they might want to be a bit
cautious about applying the results or the conclusions so if needed in your documentation in whatever you pass over to them and you're nicely written reports and summaries and meeting minutes you should be able to explain what you did why you did what you did as far as modeling or a No this is also a great place to mention samples that don't parse well and you can't analyze feature issues where you might have missing data or you might want them to try and collect more data and stuff like that okay so if you've got all that under control then basically here's what's left a good starting point is always if you're delivering the model give them a mock up
a docker container you know a sage maker instance whatever it is however you're deploying it give them something that just takes the right inputs and gives out the right output so they can do integration and smoke testing do whatever you've decided you're gonna do to convert your model from research to production be that putting it all in a DLL or putting it at a docker container or just handing them over a bunch of scripts right as long as you've agreed on it that's all good once you've done that remember I talked about test vectors this is where they're gonna save you an unimaginable amount of time pain and money run your date run your samples through your production
feature extraction and through your research feature extraction and make sure that they match up run your production model on your research features or on your production model on your production features make sure those match up make sure that your production feature extraction fails on the same stuff that your research feature extraction does right make sure all of your test cases pass basically there are you know this is sort of a rule written in blood by us once you've finished all of that package and do the handoff right you've got some sort of conversion procedure do it toss it off and you're done so super easy right No so in practice every time you do this
it's hard it's especially hard the first time so again I know I keep harping on this but you got to talk to the people that you're handing these reports or these models off to be flexible about how you deploy but not too flexible you want to get this standardized and repeatable as fast as you can every time you go okay we're just gonna do it as a one-off this one time and just to get this out the door you are getting you are a crewing technical that will be harder and harder and harder to pay down the faster you can get this standardized the better off you're going to be so again the security difference here this tends to be sort of
a cultural gap thing the high level takeaway point is you're dealing with probability and Adric aggregate statistics not individual artifacts so if your model gives the wrong conclusion on a single sample it happens if it gives the right conclusion on a brand new sample it happens right don't despair or celebrate either way machine learning models in particular always are going to have false negatives and false positives you need to have some process in place to detect those and to work with those soar to plan around them or to mitigate the errors that are the problems that those errors might throw up people especially people rooted in a more sort of traditional security background sort of thing of like reverse
engineering malware or writing signatures very often will try and drag it back down to a population or to a sample level discussion right your model missed the sample your model didn't catch this flow and sort of again trying to educate and communicate to them that really what you're looking at is like population level right yes it missed that one but it catches 98% of the other stuff that's the message that you want to keep trying to communicate to them so yeah did it work this is where telemetry comes in so you are getting telemetry right if you deploy the model and you never hear anything else in six months you have no idea if your analysis
is still valid if your model still works if your process is still you know monitoring the correct statistics try it on real data if you can't get it to if you can't get the real data to come to you send the model to them and run it in some sort of silent mode for awhile right and get feedback from that check and make sure that the real data actually looks what you like what you expected right so sometimes you might get a description of the data from your own customers and then you go and you actually look at it and you have no idea what you've just been shown so make sure that those kind of match up if you're
getting telemetry you're getting results you're running today the model of the data through your model or through your analysis you should be able to tell whether or not it's adding value are you catching new stuff are you mitigating errors if you've got some sort of metric that you've deployed is a tracking what you thought it was tracking can you use the model to collect real-world data for later refinement and training right it's going through some process that you have some limited degree of control over already can you negotiate with them to say well yes you know this docker container or whatever it is it'll give you the results you need but it's also going to
send some data back to us right so that's one avenue that you can collect real-world data but again go back to the earlier slide where I was talking about the risks of holding on to data right make sure that you discuss it with everyone who's involved and then discuss it again and then go talk to legal the security difference here is model decay so you know it works great until it doesn't basically over time things change metrics degrade models models fall apart adversaries adapt and evolve so you always want to be cross-checking your performance against new threats new attacks new campaigns and again this is talking to the domain experts right when they see a new family of malware pop up
grab some samples from them run them through your model and see what comes out all of these things eventually have to be retrained reanalyzed redeployed you need telemetry to tell you when it's time to do that okay so to wrap up what exactly did we learn from all of this hopefully this at the end of the day what you want to do is you want to deliver a data science project that somebody wants the analysis should be useful to them the metric should have a business impact the model should detect something interesting and so on the way you find out what somebody wants is by talking to them so talk to your stakeholders you should do
good science that means a lot of things but mostly it means being systematic being reproducible and then make sure that you've delivered what it is they wanted they know what they're getting and how to use it and make sure that you can track what you've delivered and be able to tell when it's not working anymore and above all you want to build this into your daily routine right build processes that let you do this so you don't have to think about it anymore yeah so with that I know I'm a little bit early but that gives us that gives you time to ask me questions and I am contractually obligated to make you stir at this slide for just a second
[Applause]
hi I'm guessing that your team mostly works in the domain of violin alysus is is that accurate yes follow-up question I I guess the the new EDR product from Sophos you have the same sort of process and network telemetry as most of the other products is your team doing anything with that sort of time series data set so we are working there there are projects in the pipeline for machine learning on network traffic and I think that's probably as much as I'm allowed to say
so you spoke a lot about the importance of collaboration and in particular collaboration within the team that's working on the particular project and I'm curious if you have advice for people who maybe have a much younger security data science practice and maybe they're the only one working on that problem at a given time how do you suggest that they go about externally validating so to speak and getting that feedback from from their peers when they don't really have a ton of peers so not a ton of peers within the organization yeah yeah not within the organisation so I think at that point presenting at conferences like this is great right so this is a good place to
sort of to vet your ideas you know reaching out to other people that are working in the same space and talking with them is always a good a good idea very often you can sort of sanity check yourself against the academic literature and just sort of see what are other people working on and do they seem to be having similar intuitions as I do a lot of it even within sort of a one-person data science practice though you can still be sort of systematic and rigorous and reproducible and sort of building those good habits and gives you a jump start on doing things like presenting or publishing papers and you know getting feedback from that another thing that
that can be I know it's intimidating for some people but it's I think it's super useful is actually writing academic papers right submitting to conferences and getting feedback on your work from that even if the paper gets rejected very often you'll get very useful feedback on ways the analysis could have been improved or ways the presentation could have been improved thank you
so you talked about reproducibility which is one of my huge touch points but you also mentioned storing your data in like CSV or Jason have you looked at any using database with provenance at all or to systematically you know keep track of stuff so a lot of times the results that we store tend to be like very very large so like we could be just as one example in in the paper that I alluded to that went to usenix our test set was seven
over multiple experiments so we didn't look at a database with provenance but we did look at storing sort of all of the results in SQL to be like variable and cross-check of all and it just it turned out to not really be feasible for us between multiple people right you know running experiments at the same time and writing stuff to like different files so for us storing stuff in CSV and then compressing it ended up being the best result but yeah I mean looking at something with provenance actually it seems like a really good idea now that you mention it thank you
hi you talked about using Jupiter as a great reporting tool as for a singular analysis as a scientist for collaborative research or reporting it doesn't scale so what do you guys use and said so what so this is totally personal opinion at this point and and I will you know fight it out with anyone what works for me what works best for me is having key functions in scripts that are version control that are going through a change management management process of some sort importing those into the Jupiter notebook to write up you know here's my report on the conclusion of this experiment you import all of the stuff you import the data don't actually run the model fitting and
training within your notebook do the training elsewhere it's great for presenting and slicing and dicing and analyzing data I do not find them particularly useful especially when you're writing functions within the Jupiter notebook because then you're copying the same function from notebook to notebook to notebook you're tweaking it in every different notebook and suddenly you have to remember which version of which notebook had this magical feature extraction function that actually worked so if you're importing stuff from you know well-structured Python libraries into your Jupiter notebook and then running a data analysis it's awesome you know use it when you are actually doing like hyper parameter search or something my own personal opinion is that should be done sort of in scripts
through an experimental management framework I also found that Jupiter notebooks don't tend to play terribly well with version control you know you rerun it and all of a sudden everything changes and you've got a new version even if all you did was rerun the same cells through it so that's the pet peeve of mine which is some other reason I don't typically like them so the question is more along the if you're sharing with other people looking at the same time think of like Google sheets or confluence terse or some sort of wiki page that someone can watch as you're doing it is to use some sort of tool that's collaborative as you ports or work dine it let's see if
someone's was we're programming something similar to that you're teaching someone are these watching over your shoulder literally or is there some sort of tool that use that's similar to Jupiter yeah we don't and so we don't tend to do that sort of you know watch me program this analysis in real time type stuff we tend to sort of do it internally and then deliver okay static reports um Jupiter might work right in that use case I don't I don't think we've ever tried it okay thank you how that's going is there a threshold of data that you cook that you use for your modeling that you consider the most optimal it's like one year or three years worth of data
where by five years would be too much because it gets too skewed because things change over time and the second part of my question is regarding do you collect at all or do you remove out things like seasonality trends or cyclical trends that are maybe exist inside the data that you're collecting so I'm gonna give you the really weaselly answer to that question and I'm gonna say it depends on the problem so for stuff like for stuff like malware you very often actually for a lot of security problems what you're less interested in you don't there are some seasonal things you can see like you know everyone getting busy as everyone goes on like Christmas vacation or
something like that but in general what you're more interested in is sort of weird off you know one-off bursts that occur as the result of a new campaign or someone finds like a new exploit and drops a PSD for and it goes everywhere as far as how much data is too much data again it's really really problem dependent so when we're looking at things like URL data just detecting malicious URLs that seems to age out very quickly so we've done sort of our internal analyses of that and I think we've come to the conclusion that we really we want to save a couple of months of that kind of data whereas for malware it seems to have a much longer shelf life
because you know you definitely do have some like oldies but goodies that just keep coming back over and over and so you want to keep those in your training set so yeah it depends I think it's an analysis that needs to be done on a problem by problem basis but it should be part of your analysis hi again how much time is spent on the hyper parameter searching and testing phase and is that automated it depends and yes so again very often a lot of it comes down to what is our threshold for success so if something really simple works right off the bat or we have a couple of sort of in addition to like
logistic regression and then random forests and gradient boosted decision trees we have a couple of stock architectures that have seemed to work really well on a large range of problems and we tend to just throw them at them and see what what pops out and a lot of times because we've sort of set our thresholds for success in our criteria for our exit criteria you know we've run one of those it works great we're like good done if it needs hyper parameter search then yet there are several Python packages out there that will do hyper parameter optimization for you very effectively and you just throw it at one of those but again all of this
happens inside an experiment management framework so that when you run that hyper parameter optimization you know what the range of hyper parameters you tried was you know what it did and what the what the results are and they're all automatically stored and tracked hi you mentioned earlier about like regulations around data retention and stuff like that how do you make solid cases for retaining for longer periods of time than what you would normally have to be held to by the decisions of like your legal departments and stuff like that because sometimes some analyses really only have value if you have data outside of that scope yeah and that's that's something that we have to negotiate with legal right we have to
get their approval to be able to hold on to that kind of data and again what it comes down to is sort of doing the work behind it to show know if we restrict ourselves to you know three months of this particular data type the results are going to be too bad for general use and so we really need six months or a year or two years of this in memory and you know this is being able to show your work on that and show that you actually have considered only holding it for six months and you're not just doing the standard data science thing of no we couldn't possibly throw away any data ever tends to give you at least a little
bit more of a firm ground to stand on when you're trying to negotiate these things but at the end of the day if the legal department comes through and says no you just cannot keep it right that's you know that's that's the end of the story right we just tell them this is the business cost of not keeping this data and someone decides that they're gonna pay it
[Applause]
Related talks
 51:51
51:51 32:48
32:48 33:48
33:48 54:33
54:33 31:06
31:06 20:51
20:51