Building Real-Time AWS Guardrails: A Serverless, Homegrown Engineering Blueprint
Show original YouTube description
Show transcript [en]
All right. Uh, building stuff has never been easier than today. Um, all we need is an idea and hopefully I can give you one today. Um, I'm assuming everybody's writing more code this year than a couple years before because of AI. Uh, anyone reads every single line of code that AI writes? >> Good job. Um we've seen many presentations. This is not one of them. But um take a look at this news article just from this month. A threat research team discovered um uh an attack where credentials were discovered in S3 bucket rapidly escalates escalates privileges through Lambda function code injection moves laterally across 19 principles. abused the bedrock and then launched instances all in under 10 minutes. The second
bullet point is probably more interesting is that it says affected S3 buckets were named using common EI tool naming conventions which means that somebody just used AI to vip code. Uh and uh it's okay you know we we want people to experiment and move fast. Uh it's a good thing but unfortunately not everyone is AWS expert. Um, so we want to have some sort of guardrails to make it easy for them. Uh, and wouldn't it it'd be nice if uh we could just prevent those uh misconfigurations because that's what I want to believe. That person didn't intentionally uh created the bucket and made it public with the credentials. It's probably a genuine misconfiguration. um wouldn't be nice if we prevented it,
but if we didn't prevent it, then couldn't we just fix it on the fly? They pushed it out and we just fixed it. Um that's why we have guardrails. So, let's define what they are, what the guardrail is. Um I define them as the automated controls that enforce security and compliance in real time. The benefits are obvious. Uh we talked about security one uh with AI adoption and in general everything is moving super fast. Uh we need automated security response. Uh in general we want to have an ability to respond to events in real time. Whatever happens in in your environment you want to be able to catch it and kind of do action with it.
Uh compliance nobody likes compliance after the fact. Uh again if we can enforce compliance in real time uh that will be a huge help to everyone. Teams are generally happy to do the right thing if we give them the the feedback in a timely manner. And cost uh it's it's a byproduct. Uh security generally doesn't go after cost directly but that's also a nice uh benefit. I'll give you one example is that uh with um compliance policies you have data retention policy for sure and none of them says that you should keep the data indefinite. uh one of the examples is cloudatch log groups. Most of the times you do not create cloudatch log group explicitly. You create a
lambda or you create RDS instance or you create kubernetes cluster and uh let's say lambda you create a lambda. Lambda is super chatty. It generates a bunch of logs. The logs go to cloudatch log group and that log group stays there indefinitely. That the data is stored there indefinitely. Uh that's one of the ways where you can implement the guardrail and automatically enforce the data retention on that uh cloudatch log group. Best part is that if you delete the lambda actually because you didn't explicitly create cloudatch log group for example is that you delete the lambda but the log group stays. Uh so that's one of the examples of the guardrails and something it to look in
in your environment. I can guarantee that you have log groups that are years old and storing terabytes of data. Uh that's something you can fix by enforcing compliance and um uh save some money. Uh so guardrails is not one thing. It's a set of tools. Uh you pick the right tool for the job. Uh AWS has probably dozens dozen uh different organizational policies, different types, service control policies, declarative policy, resource control policy, S3 policy, tagging policy. Uh if you can use the or policies, they are the easiest ones to implement. They are the broadest ones. uh but because they're the very broad you also can't always use them uh because of uh specifics to in your
environment. Everything that we'll talk about today relies on cloud trail being enabled in on the org level. Um so again one of the examples of something to do on the or level that helps uh kind of general security posture in your organization in code is u very important um it's much easier to give developer feedback in the CI/CD pipeline. So when somebody is using Terraform or cloudformation template or whatever to push the code changes, it's so much easier to give the developer feedback right there right then in the CI/CD pipeline for example than going after the fact and trying to fix the resource later. I think of it as like if all fails then you go to the event- based automation
that we're going to talk about. uh before you build stuff uh it's always fun to build stuff but u take a look at the existing solutions uh AWS recommends um AWS config for a lot of this stuff uh unfortunately you see a dollar sign at the end if you really want to get to uh real time remediation you would want to enable config with continuous recording and in our environment at least because of the size and how frequently we change the the resources uh that was just cost prohibitive to put it mildly. The second one, security hub also relies on you being security hub customer which is not always the case. But do take a look at
that repo. They have a lot of code examples for um how to remediate um specific event types kind of specific findings. Last cloud custodian great uh open source tool. If one thing you take from this talk is probably take a look at the cloud custodian has YAML based rules. It's um works AC across all cloud providers. Great tool. At the time when we were doing this it had some weirdness with orwide deployment. Uh so we do not use it for real time remediations but we still use it on a schedule based like if you have something in mind that you want to just find in the existing environment and reme remediate it. Cloud custodian is a is a great great solution.
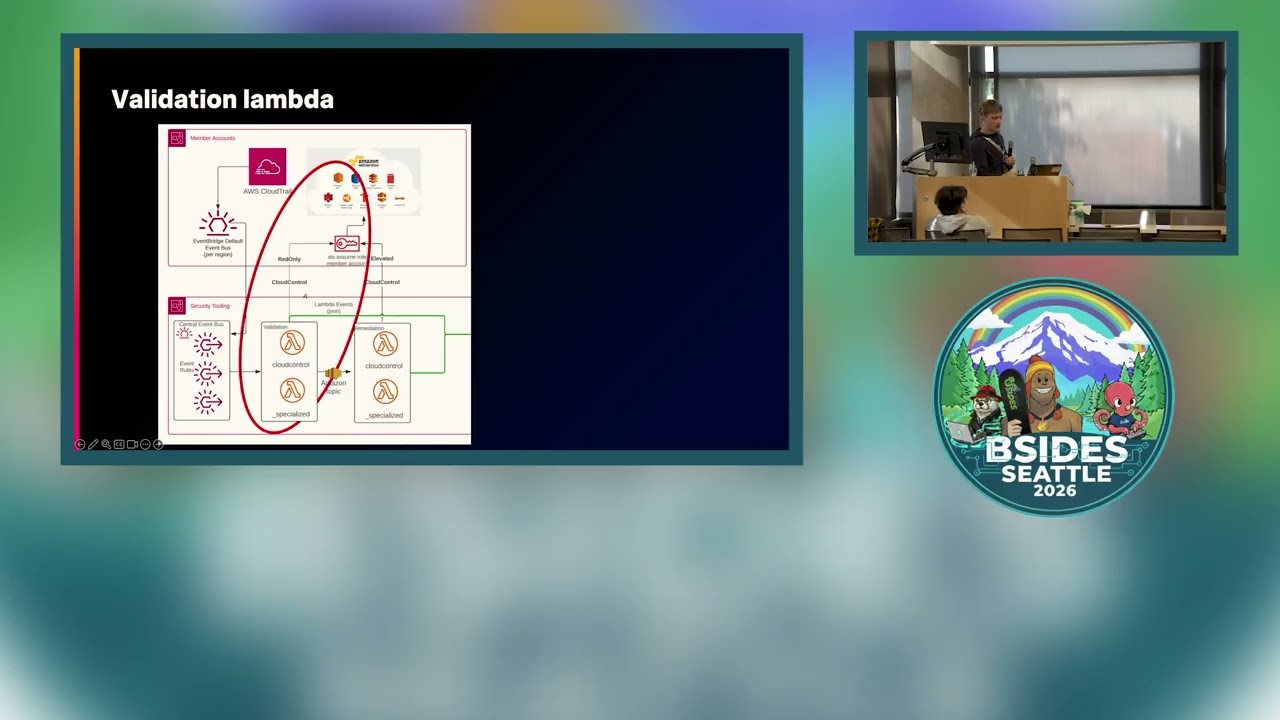
Um so our solution is not totally kind of new. Uh this is uh something that um this second bullet point security response tool is doing. Um the idea is that you forward forward all the events that you're interested in to a central place. You analyze those events and then you take action. In this case, anything that happens in AWS generates a cloud trail event. All you need to do is the where the number one is is that you need to uh specify the events that you're interested in, forward them to your central uh event bus and then take action. The reason why number one starts there is that because cloud trail goes to event bridge by
default. uh you don't you do not have to set anything up there and cloud trail also goes to event bridge for free. Um so again you don't have to pay anything for it. Really what you're paying for is uh from number one to number two uh and you're because you're only forwarding selecting selected events uh it's the the cost is very cheap from the arrow from lambdas going up to back to your member account. So the in general you have member accounts at the top. So that's every single account in your organization and we call it security tooling. This is where we uh just have all of our tooling. So from every account from every region you
forward events that you're interested in to your central account and then you just have uh lambda functions analyzing those events. Um the arrows up from uh lambdas up that have a cloud control tag on it. Uh that's the kind of the most important piece. Um, that's a secret sauce. Anyone used the cloud control APIs in AWS? I see one person nodding. Okay. Um, cloud control API, think of it as a CRUD operations for cloud resources. Uh, if you use Terraform or cloud for all of those work on a CRUD. Um, so it boils down to create update delete uh list. In this case, it's like get create update list resource. It standardizes the verbs uh
for the uh operations. This is an the top one is an example of the classical AWS CLI and you can see the verb inconsistency. You can see when you're trying to script something and when you're trying to do something, you would need to know those different verbs. You describe log bucket but then get bucket version and then describe and then get again. It's very inconsistent. And the same thing with the flags uh after that. It's like d- log group d-bucket d-group ids just inconsistent very kind of difficult to uh code. Uh the bottom part is the cloud control API example and you can see how it is uh much more standardized where uh you just have a type name you specify
which type and then identifier is usually just the name of the name of the object that you want to uh manipulate. Same thing with the update uh commands. Again, the top portion says um shows an example of the traditional CLI and the bottom is um with a cloud control. The lines are split a little bit and that um patch document seems intimidating. Uh but in fact, it's just manipulating the JSON object that you uh get back that describes the object. Uh so when you look at it, it's follows the same crowd operation. So up get add update or delete a certain value from the from the JSON and the same pattern uh gets across to
code. Uh this is what kind of obviously simplified example but this is what you would use in your lambdas uh for validation remediation. when you get an event that you're interested in, all you really need to do is call cloud control API and you can see that you really just substitute a couple of parameters. Uh on the line four, you would traditionally uh initialize client for every single service. So you would do client EC2, client S3, every type of service that you want to interact with, you would have to initiate a separate uh client object. And then um all of those inconsistent verbs again you would have to write separate uh functions to make those calls which make coding a little
bit harder to scale once you go after more and more use cases. With the cloud control API uh the code is standard. The only thing you're substituting is line seven and eight, right? So you're just specifying which resource you want to uh kind of check and then the the name of that resource. And about the same 10 lines of code for if you want to manipulate the object. Uh you would um just substitute line 15 type identifier and then the patch object that you want. But it's really a super nice template. Back to the diagram. Let's let's focus on the what we call validator function. Why does it even need this cloud control API uh and like assume roll into a
member account if we have everything in the cloud trail event? Well, the problem is really inconsistency that sometimes I call it the happy path. Sometimes a cloud trail event indeed has everything that you need to do to respond to an event in real time. Uh but there's a lot of times that it doesn't. So in this case, you can see that this is an example of the authorized security group ingress. uh when you're modifying security group in AWS and cloud trail itself right there has everything that you need to do. So in this case we're just catching uh when somebody is trying to authorize security group with any any any port any uh any protocol from port
and two port are any minus one means any uh and at the bottom right you will see an example of the rule that we write and we use actually rule engine and you see the link at the top if you want to take a look. Uh rule engine lets you just write rules uh against the any JSON object. Uh, and this is one of the more complicated rules because we're trying to catch uh multiple ports there. And this is a truncated example, but you see if you were to um try to catch when somebody is trying to open port 22 um RDS admin ports and stuff like that, you would just list all of those ports in
the array and then this rule would automatically tell you when somebody is authorizing um an ingress with those ports being wide open from like quad zero. Uh this is uh not a happy path. So you get an event uh from cloud trail and it says somebody created the cloudatch log group or S3 bucket or whatever and uh you can see that all this event has is the um you know the name of the event and then the the name of the resource. But the actual configuration event comes seconds later. And that doesn't work because in this case you actually uh you need to stitch those together in in real time and requires building a complex
state stateful event correlation engine. We didn't want to do that uh and we just wanted to keep it stateless. Um so the way we do it is that we just uh use the initial create notification event. We take all of the information from here like the event name and then the actual uh resource name and then we call cloud control API uh here to go assume the readonly role to the member account look at the state of that resource because we don't know if that configuration event came in later and what the configuration was. Um, so we just kind of ignore most of that stuff and we just take the information that we need from the create
event and we immediately go back to the resource and just check the state of it and then we write the run the rule against that output uh to see if it matches our u kind of standard. Uh this is an example of the just running it in CLI. You can see this is how you would get the state of the um cloudatch log group and the rule using the rule engine is super simple because if retention is not set then you would just not have that key JSON key in the in the response. So our rule is actually just not retention in days. If that key is absent in the uh in the JSON blob then
this is a matching uh rule and we would go and then patch that object and uh add uh retention in days to that. You can see there's two more examples of the Kinesis stream and Kinesis fire hose. Uh this is an simple example of where we do sort of like a compliance thing of just adding uh encryption to those Kinesis stream and Kinesis fire hose. again security and compliance at the same time. Uh testing is simp super super important. Uh just a simple slide that every time you write the rules uh we have a simple YAML file again uh we're simulating uh passing different JSON objects to our kind of rule engine and expecting it to either match or not
match. Now if we put it all together really uh when you look at the diagram on the right again uh and everything that we really need to configure and think about simplified 20 lines of code of getting the state of the resource and then patching it really all the information that you need is in this u YAML document that we came up with. It's just a simple schema and we're saying that uh really on the number one where we are interested in a particular event types. We write the rule and we specify which events we're interested in. So on the line 3233 we're just saying this particular rule works on a create log group event or create S3
bucket whatever the the case. Um then you can just have a simple script that parses all of your rules and gives you exact list of events that you're interested in and then you can plug it into the cloud for template and um uh you know deploy to your org. Uh same thing with the remediator lambda. You do not want to give that lambda just admin privileges across all of your resources. Um we just put it right in the YAML. All that re all that lambda really needs is the put retention uh configuration. For example, the same three same thing would be with uh S3 buckets and any other resources. You you're just giving it bare minimum permissions that it needs
uh to remediate the resource. Uh the top portion is a documentation. Uh so this YAML is not only configuration for the lambda, it's not a configuration for the event bridge, it's all of it. A it's a low code kind of approach to write rules. Next engineer that comes in, they want to write a next rule. They fill out the documentation portion. We use MK docs automation MKD docs library from Python. We parse it. We build a web page and it automatically um publishes for everyone to see what the definition of the rule is, what the guidance is. Um so this YAML is everything. It's a documentation. It's CI/CD. it's um you know configuration. Um so is it really that simple? Just 20
lines of code and uh you you get it all done. Uh it probably never is. Uh don't get me wrong, like I said, for a lot of the use cases where you just uh have a simple flag of set retention, set encryption, set uh something simple uh works great. You can automate a lot of the use cases that way. Uh but there is some things that you need to think about. Exception handling uh just like everything else there's very little um there's very little very few things that are just black and white. There's sometimes exceptions. What we do with exceptions is that even if it's a public S3 bucket for example, there are legitimate use cases when people need S3
bucket uh public. You're hosting a website out of S3 or something like that. So we are doing uh exceptions based on tagging in that YML file. We also have an exception uh tag that says if you need an exception you just specify the tag with this specific value and then it's going to go through the our guardrail will bypass it. So think about that. Uh slow resource provisioning. Again, if you want to get into more of a complex use cases, for example, you want to check the state of your uh RDS instance or Kubernetes cluster, you will get creation event super quick from cloud trail. However, the RDS instance takes time to to come up. Therefore,
when you run the call to get configuration and check for the compliance, you won't be able to until RDS is ready. Um, so we use like um step function step function. Yes, I think so. Um, and um it it gives you a backoff um uh algorithm where it can wait a little bit longer. your lambda can can pause and wait until the resource is ready and then you get the the state of the resource and unfortunately uh this cloud control is not perfect on its own. One example is that sometimes the traditional CLI offers you gives you an ability to update resource whereas cloud control would do it with delete and create. Uh there is a very few examples where this
causes problem because the resources are linked using ID. Um so if you actually delete it and recreate it, it may cause some confusion uh depending on how developers are building it. So just pay attention. It's all listed in the documentation. You will clearly see if API lets you update or if it will kind of tear it down and recreate it. And uh last is the really annoyance with AWS API or cloud trail I guess is that um it's inconsistent API response for some events in the name of the resources you will actually get the the name of the resource and the other times you would get the ARN. Um so it's just confusing I don't know why AWS does it
but um it is what it is. So there's some gotchas that uh you need to pay attention to. Uh but really this is a low code approach to build a couple of those guardrails. Uh super quick uh takeaways. Um better to prevent than remediate. We talked about it. Use the orc policies. Use account level settings. Use stuff that prevents the misconfiguration from going in versus fixing it later. Uh that's always better. Uh cost. This solution is really super cheap. you run this for dollars versus if you enable AWS config that's going to cost you a lot. Uh and then a couple of examples of guardrails. Um I took cloudatch as a super simple example people can relate
to. Uh duplicate cloud trail is really a fun one. I mentioned that cloud trail goes to event bridge by default. Uh that is true and AWS gives you uh cloud trail for free but only the first cloud trail. If your developers are for some reason configured a duplicate cloud trail, then you're going to start paying for it. So take a look. It's a fun fun one. Uh you're really cloud trail bill your cloud trail bill should really be zero. But if you're paying thousands of millions, uh you're probably looking at some uh duplicate configurations. Again, something super simple to um to build a guardrail for. And then public resources, a bunch of examples. Most of
those are a simple flag, public or not public. again good candidates for this type of guardrail. KMS encryption, same thing. And then something simple like catching a trust policy with a principal star could be one of them. Um otherwise analyzing IM is super hard. Uh yeah, I think that's it. Thank you very much.
Yeah. So the question is boto3 example versus uh cloud control. >> This is the reason because uh when you use boto 3 you would in the code you would have to initialize and so where was it the here so in boto 3 when you write the new use case uh on the line four you would need to initialize the all of the resources differently. you would initialize the client for EC2 and then on the line six instead of doing get resource you would do you know update S3 bucket but then you would have to initialize the code uh different different functions for every single resource versus this it's a really simple template. All right, thank
you very much. Have a good day. Thank you.
Related talks
 56:40
56:40 51:33
51:33 50:25
50:25 46:38
46:38 49:30
49:30 53:36
53:36