'Like at do ye'? Perfecting Threat Detection for Next-Gen SOC's! - Aaron Wilkinson
Show original YouTube description
Show transcript [en]
Well, you know what? I'll I'll do the awful job of introducing myself here. So, thank you anyway. I appreciate it. So, good morning everybody. My name is Aaron Wilkinson and today we're going to talk about threat detection and how we can change our vision to make threat detection work for everybody within your organization. So, this is not my first time talking at Bides Belfast. uh I did give a talk last year on detection as clo uh as code and now we're going to go for a little bit of a different angle but still in the threat detection world there. So one thing I will call out here is if you look in your pamphlets it does
say uh that I am a lead incident responder and the head of threat detection at a company called Orbia. Uh that recently changed. Um so I'm now the global lead of threat detection and response over at All State. Uh, I've got roughly a decade of experience working in incident response, digital forensics, really the wide gamut of cyber thread operations. And in my spare time, like to build some scripts. I'm a big nerd. That's really how I can describe it there. Like to build scripts, like to build computers. I find missing people through gamified open source intelligence competitions. And if anybody here has heard of the initiative Trace Labs, that's what we go through to do that. highly recommend people check
that out because it's a really really good cause for charity. And then as well, I'm very informal as you're about to find out. I like automation, building those scripts. I love memes. I love a bit of brain rotten doom scrolling because we live in an area of that's where what we have these days. So, we'll jump straight into it. And I kind of want to start this out with a little bit of a story for everybody because I think in this conversation specifically, it's going to resonate with a lot of people in this room. It may not, but we'll see. So, in my past life, we have a bit of a problem, and it's a problem that I'm
sure everybody in this room has came across at some point or another. And the problem is resources. You either don't have the tools in place for threat detection. You either lack the people for a threat detection function or threat detection service, or you simply just lack the budget for it. I don't think a lot of us in this room have a $50 million budget specifically for detection engineering or threat detection. If you do and you want to raise your hand, I'd love to have a coffee with you afterwards to figure out how you're spending all that dough. But in reality, we don't really have that. And that was the same in my in my prior
life. You know, we had very little resources and we really had to start thinking outside the box of how we approached threat detection there. And we had some good tools, right? you know, we have some of the uh industryleading platforms um available to our disposal, but how do we leverage those and how do we give ourselves essentially full control over all things detection? For anybody who has worked with various different tools like Crowd Strike or Microsoft, you'll know that tuning out your false positives or your benign things is very different between the two platforms. and personal opinion of mine, it's very tricky to do that very well in Microsoft. So, how do we go about
changing our vision from a technical perspective? How can we give ourselves more control over detection? How can we make things scale efficiently? How can we make things a lot easier to manage? And these are all questions that I'd love to answer today. And I think I've really come up with something that for me is the perfect vision. Spoiler alert, it's not a completely perfect vision for everybody, but I hope that as we talk today, you can take some things away about how we can look at threat detection a little differently. So, let's just jump straight into it. This is what I call the perfectionist vision for threat detection. There's five core elements. And before I even
jump into any of these today, I am not going to bore anybody about the fun things of SLAs's and health checks. Not about that life. Um, this is very technical focused this. Um, I tried to keep it as high level as possible, but if anybody wants to come and talk to me a little more afterwards, I'll be floating around all day. I would love to talk to you about it. But there's five core components here. You clearly define your logging strategy. You have an efficient alert pipeline and this is the critical one here. You have modularized enrichment functions. You have knowledge objects that are dynamic and constantly updating. And then finally, you have a clear structure
for your custom content. When you're building out these custom alerts or these custom detections, it all has a very clear structure to it. So, we'll jump in and we'll talk about these one one by one. Let's talk about that defined logging strategy. So, let's get a few things clear. Our SIM, be that a Splunk or a Sentinel or Gray Log or whatever it is that you're using out there, it's only as good as the quality of the data that it receives. Not all those logs do the same thing, right? So, your EDR security event feeds, your security alert feeds, very different from your VPN logs, right? right? You're not going to be using your VPN logs on a
day-to-day basis most of the time, right? Um, but there's another component to this and it may annoy some people, but I feel very strongly about this one and it's if you have a threat detection function or if you have a detection engineering function within your organization, that team needs to own and be accountable for deciding which of those logs make it to the SIM. And there's a few different reasons for that, right? First is cost. Again, we all don't have $50 million budgets to just loop everything into a sim and just hope for the best, right? We can't just ingest raw logs and just be happy with that. That just doesn't work. Um, but also detection engineering, you're the
subject matter experts. You're the folks who have a clear understanding of how logs are structured, the fields that you need to pull out to make a detection work and be enriched and contextualized effectively. So detection engineers should own this process. Now that's about as high level into the management side of things as I'm going to talk about today, right? But really we'll talk how do we prioritize some of the logs that come into the sim. So I've said that dete detection engineering should own this, right? But what are they owning? How do they prioritize that? And the prioritization model, at least in my head, is very straightforward. You just break it down into three areas. You've got your
primary logs critical for detection. That's your Crowd Strike security alert feed. Not the raw logs, your security alert feed. It's your NDR alert feed. These logs that are critical and the whole reason why your function exists in the first place, they must be available 100% of the time, 99.9% and it needs to recover very quickly. So the heavy SLAs's around that super built out health checks, you have to have that in place for these logs. These are the ones that matter most. If all of the other logs go down, you can wait. If these go down, you've got a bit of a bad day. You're getting woken up on Saturday mornings to fix them. You've
got your secondary logs after that. So your alerts have fired. You've got your critical logs in place. Now we're going to investigate those. We have our secondary logs in here. And these are things that provide additional enrichment to your investigation. So things like your VPN logs as an example could be secondary log and I'll show you some examples after. But then we have our tertiary logs. So these are our nice to haves. These are the things that we plug into the sim if we have the space to do so. If we have the budget to do so. And you're not investigating in these 247. It's great to have them, but you could potentially pull your tertiary logs out via EDR.
Maybe writing a script to say go and get my application logs from this server, pull it back, and pull them ad hoc into the sim. So, there things that don't necessarily need to be in there constantly pushing a SIS log feed, right? So, what do we think about here, folks? What do we think about as examples of logs when we come to prioritizing those? Well, our EDR and our NDR, those are primary. Those are your key. These are the things that we want in the sim all the time. These are the things that your sock analysts and your incident responders rely on constantly. And we're all aware of that in this room, right? I mean, how there's no point really having
a SIM if you don't have your security alerts in it, right? And you're not being able to triage them through. That makes no sense. But then you have your secondary logs, you have your VPN logs, you have your DNS logs. these things that will support your investigation as to how did an attacker get into our environment or is there command and control occurring uh through our environment and what's the source IP with that. So secondary logs can help you investigate that and then you have your tertiary logs your real nice to have. So you're thinking your database activity monitoring logs, you know, things that you can kind of go into tools like Guardian and just look at um your raw
application logs. Maybe you work for an organization that has lots of applications that they deliver to customers. Maybe you just bring those in ad hoc as you need per your investigation. Saves you a lot of space within your SIM. Saves you a lot of money. Everybody goes home happy. But really kind of the meat of this talk today is this point here. How do we make a pipeline for our alerts that is super efficient, super scalable, and really easy to manage? Because I'm sure there's a lot of you in this room are kind of thinking, oh, and you work in detection engineering and you're thinking, I literally have no idea what my SIM looks like right now. It is a
complete mess and this aims to solve that. Now, gonna put a quote up here. Somebody might have said this in the past. I'm going to quote it because that's just what I do. So, your detection engineering function ain't working optimally because your alert pipeline sucks. All right. I somebody else probably said that, but you know what? I'm going to coin that. Whatever. Um, but it's true. How can you perform an investigation effectively if you don't know what all of your alerts look like? If you have fields that are not standardized and normalized, that aren't enriched or contextualized, and then all of a sudden your director is asking you why your meanantime to respond is hours or days, whatever it
is. Everything that you do in detection impacts everything else downstream. So we start at prepare then we go to detect. Speaking for NIST, right? We go to detect and then everything after that is impacted by what your alert pipeline looks like. How can we make things easier for our primary customer and that's our incident responders. It's our sock. How can we do that? Right? but should be really really wellnown. This is a critical process, right? This is a critical point that we really need to spend a bit of time on here because it is super important for your function to be able to scale. Like how many people in this room, right, are either detection engineers or your sock
analysts and you have hundreds, like literally hundreds of alerts and bits of custom content that you maybe don't have detection as code for. It's very difficult to be able to track and maintain all those and you don't have the control. Probably a fair few of you, right? Well, let's get away from that. Okay, let's focus on letting the source systems do the job that they're expected to do and then build our content on top of that. But your your alert pipeline, it's the backbone of all of your capabilities. And as I've said already, your ineffective inconsistent alerts lead to extended triage and investigation time. No bueno. We don't like that. No habla. So, I'm gonna share this with you all. I'm going
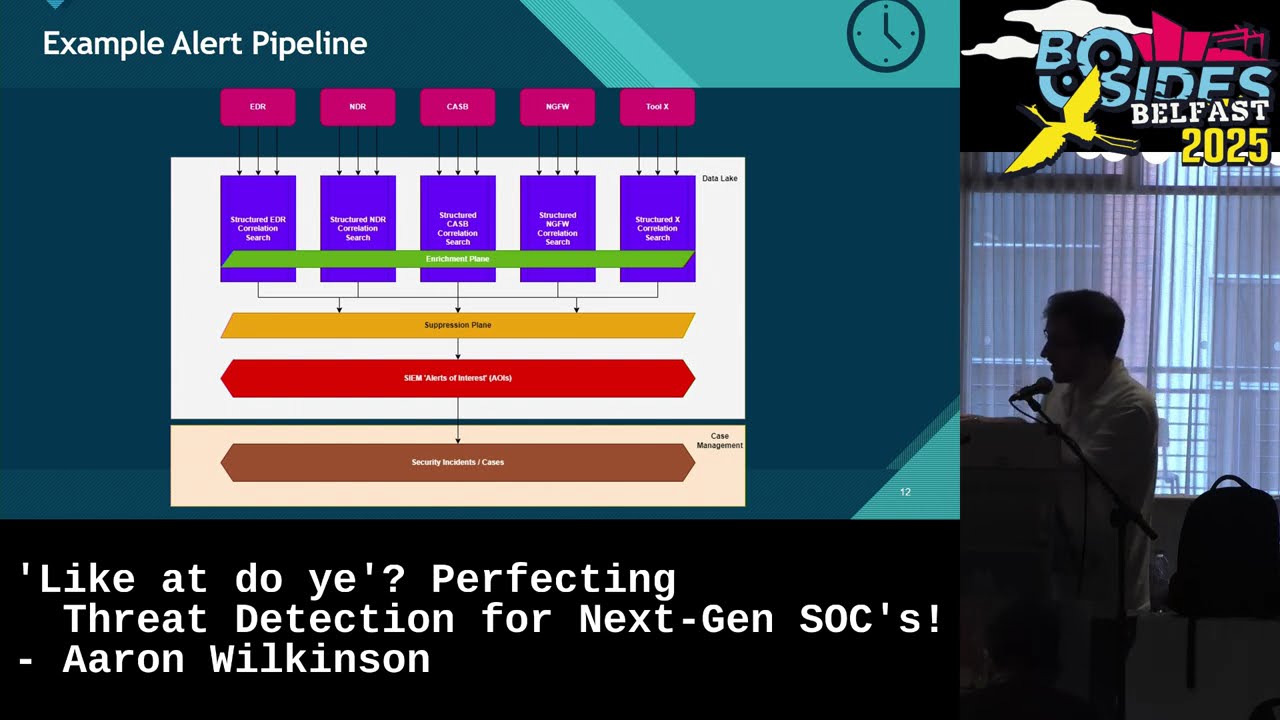
to take give you a little second just to kind of digest. I hope everybody can see this, okay? Especially folks in the back. I know it can be a little trickier to see, but this is my idea of what an effective alert pipeline looks like. I'm going to share it with you all here today. You start at the top. Let's see. Can we see this? See how awful my laser pointing skills are? At the top we have our source systems. That's your EDRs. It's your NDRs, your WFTs, your nextg firewalls, CASBY, whatever you want to insert source system here, right? Crowd strikes, dark traces, whatever it is. Well, instead of creating a single alert in your SIM for each alert that comes
from that source system, aggregate them all together into a structured I'm going to use Splunk nomenclature into a splur structured correlation search. That's these little purple parts here. And effectively what this means and we'll get into it more a little later on is all of these this structured content the output looks the same. So all the fields are all standardized all normalized. All your data is aggregated together. So you're not having six alerts for a single incident. I'm sure a lot of folks have had that problem as well of having to triage the same alert for the same incident over and over again. aggregate it all together. Gonna skip over this part for now because that's coming up next. But we
have an enrichment plane. And why does that look the same across all these correlation searches? And we'll talk about that. Once you have things coming out of your structured correlation search, they go into your suppression plane and that really is giving you full control over everything that you suppress. Again, going back to what I said earlier about Microsoft, you know, sometimes it can be a little tricky to tune and suppress in that platform. Well, what if you were able to tune and suppress and do it the same way across all of your source systems? There's your suppression plane in your s. Once things make it through there, they go to your alerts of interest. They go
to your sock. Sock goes to triage those. So in Splunk these are your notables or in defender these are your incidents right as you're working through there and then from there you escalate those to be a security incident or a case I know our industry at the minute kind of has a bit of trouble um with standardizing around what an alert is what an incident is and what a case is um but that's a nomenclature we're going to be using today so detection engineering is responsible for everything here and then your incident handlers are responsible for everything here. So let's go back and talk about those modularized functions. I said we were going to talk about that enrichment
plane. Like what is that? You know how what do you mean enrich alerts? Like we know about this. We have a soar. Our soar enriches things, right? No, we don't need a soar to do this. I want to make that very very very clear. You can use a sore, but if you're ingesting a lot of logs into the sim, why not use the data that's already there to enrich your security alerts for you? And I'll give you an example of this. Imagine you're a Microsoft customer. Again, really giving the goose away here, talking about Microsoft a lot, right? Um, imagine you're a Microsoft customer and you have your E5 logs flowing into the SIM. There is so much there's a treasure
trove of data in there. So in your identity info table, you can effectively generate a user inventory. For device info, you can generate a device inventory. If you are a Crowd Strike or a PaloAlto XDR customer, you can pull all of the endpoints out of there and store them in the SIM. You have new inventories there. But we can build that directly into our detections into our structured correlation searches. And really, what is this function? Well, it's just a reus. It's like in software engineering when you have a function. It's just a reusable snippet of code. So, you call your function, you pass a variable to it, and it does something or returns something or outputs something
to you. It's the same concept for thread detection. We just do it in the sim. So you have your raw alert fields coming in. So your source IP, your desk IP, your username, whatever it was. You rename username to source user and you standardize around a common schema like your SIM or OCSF or I think the new one for Microsoft is asim. I think someone will need to correct me on that one, but I think it's asim. Um, change it, transform it into source user, pass source user into your source user enrichment function, and then get all of this juicy details back again. So, your source user email, what's their email, what's their job role, what's their
manager's name, what's their manager's email address, what country are they in, is there a source IP associated with this user? Well, let's just throw it directly into our structured correlation search and it's just all there for you. And this is supported by a lot of different a lot of different tools and platforms. We talk a lot about Splunk and talk a lot about Microsoft today. Those are the big players really in kind of the SIM data lake space. So that's why we're referencing a lot of that and a lot of people here will be using platforms like that. But it's supported across both. So in Splunk they call them macros. In Microsoft, I believe they
call them just call them functions. Um, again, someone might need to correct me on that one. And the nice thing about these is that doesn't necessarily just have to apply to your alerts. When you go to have your sock investigate these and they're creating their own custom queries within the SIM, well, then they could just call source user enrichment, pass whatever field they want to it, and get the data back again. So, it's all about creating something once, maybe maintaining and updating and adding to it over time, but creating it once and just continually reusing the same code to be more efficient over and over and over again. So, we're applying our software engineering practices
to this. But where can a lot of this data come from? You know, we talk, oh, Aaron, you're talking about source user enrichment and yeah, it's in E5 logs, blah blah blah. What are you talking about? I don't know. All right. Well, let's talk about that then. Let's talk about dynamic knowledge objects. And in dynamic knowledge objects, essentially this is a reusable knowledge base. Stores all your data for you. Think of it as just a big CSV of all your data. Or in Splunk, it can be a KV store. Let's pull some data from that identity table. Let's pull some from the device table. And all of a sudden you have this lookup table, this reference table that
has all the users information as well as all of the information associated with their device, as well as all this information associated with the groups that they're in an active directory as an example. You then have that set as a scheduled query that runs every eight hours, looks back for two weeks, 30 days, 7 days, whatever your whatever you want to look back for. [snorts] And you'll have a constantly updating list of all of the users and their endpoints within your environment. So your user inventory.csv and all this is normalized as well under your schema. So your source user, your DVC or your device, your host name, device IP address, is the device isolated? Yes.
No. Like you can add in whatever you want here and then bolt that into your structure detection and have that output just for your sock analysts. So they don't have to go and look for this anymore. So I've talked a lot about structure here, right? It's been a lot of talk, what is this structure detection content you're talking about, iron? I don't know what you're talking about. Well, we'll talk about that now. All right. Now, this is another critical point here. All of these things that I've talked about so far, they work on their own. So, you can go out of this room now and create your own modularized enrichment functions. You can go out of this room
and create your own alert pipeline. You don't have to build all five out at once. But this is going to be something that really is going to take things to the next level there. make things really easy to scale, make things really easy to manage, and it's structuring your detection content effectively. So, it ensures that everything is accurate. It ensures that it's consistent. Doesn't matter if the alert comes from your NDR or your EDR platform or your W or wherever it is. They all have the same schema. They all have the same outputs. They all look roughly the same. Makes everything clearer, more manageable. And then on that the different components of your detection are layered as well. So if we go into
that we look at the perfect perfect structure. We start with our raw alerts. Okay start up here. We bring in our let's talk crowd strike as an example, right? We bring in all of our crowd strike alerts and we bring them into our structured correlation search and statistically aggregate on them. We filter specifically down to the alerts that we want to see. So, we want to see crowdstrike alerts or we want to see uh all CrowdStrike alerts that are not compliance alerts. So, we're working in cyber in the cyber incident response team. You want to see security alerts, maybe not necessarily compliance, different different business use cases there. You then do some transformation. So let's take whatever is brought in as
a raw alert, transform it into our schema, do a bit of renaming, do some custom evals to make sure that we have all the data structured and looking exactly how we want it to. We then enrich based off that data that's been transformed. So maybe we've transformed what is it in Crowdstrike? Is it just username of an endpoint? We've transformed that into source user. And now we're taking that source user field and enriching it to say all right give me everything about that user. Give me their email address. Give me their location. Give me their manager. Give me everything about them. I want to know. We're then aggregating all the data together and dduplicating it all so that
the final output once we hit aggregation is super clean, super structured. It's all coming from Crowd Strike. This is all just the data that was provided, but you're enriching it at the SIM level and your output is just a very clear alert that has a bunch of fields that a sock analyst can now go and look at and they don't even need to go into CrowdStrike anymore because you have enriched and contextualized the alert so much there's just no need to. They have their file names, their file paths, who the user is, is this abnormal, have they triggered alerts in the past? it's just there. It's great. That greatly increases the efficiency of the sock. But then maybe the sock comes back
and they say, "Actually, this alert sucks. I don't need to see this anymore." Maybe it's anformational severity alert. Well, then we just suppress it out. Where severity is not equal toformational. Done. you've just taken down 20% of your alert volume from a source system and you still have all that superenriched and super contextualized data there from all of your alerts. So that's how we structure it. And if all your content follows this structure, be it coming from a source system or be it coming from um you know proper custom behavioral content that you develop, as long as it follows this structure, you're easily able to identify if something breaks, oh, it's a transformation issue. I'll go fix that.
It's at this line of the of the query. Go fix. Oh, my source user enrichment broke. Okay, I'll just take that macro out or that function out. Oh, no, it's I'll go and repair that. The rest of the detection works fine. And that's what we're going for here. We're going for simplicity. We're going for easy to manage. Don't going for scalability as well. You don't need to have separate alerts for all of your alerts that come from your source systems in your SIM. It's just not manageable there. And you can augment and bolt on this with detection as code as well. So you can control all of these custom perfectly structured alerts in your alert pipeline through detection as
code. Make it even more scalable there. So, let's close the loop. Let's come back full circle on this. We talked about clearly defining a logging strategy and how your detection engineering team should be at the forefront and be accountable for the logs that go into your SIM. We talked about that efficient alert pipeline and how we can essentially scale threat detection up. That's in perfectly our our own control. We're the owners of the SIM platform. We talked about how we can enrich detections that come from our source systems or our custom content that's already in the sim without even needing a sore through our modularized enrichment functions. We talked about those dynamic knowledge objects which I'm sure a lot of you are
using today. And then we talked about how we can structure our detection content to make sure that not only is it easy to develop and you get start to get muscle memory of how to develop this type of content out, but how we can fix things and where to go to fix that because the entire detection is an easy to follow structure. And coming full circle on these, like I said, you can take any of these with you today. You can go and use any of these. You can take two of these, you can take four of these and go and plug them into your own solutions within your organizations and it'll work well. But
to really get the most value out of all of this and think differently about threat detection, you can take all five. Reimagine how you do things within your organization. Simplify it. Know a lot of people say that security should be simple. I'm a big proponent of that. I think it should. We're not reinventing the wheel. We don't need to overengineer complex solutions like this. Shrink it all down. Keep it simple. Keep it scalable. Keep it manageable. And all of a sudden, you'll find that you have a very efficient threat detection service there once you build out your SLAs and your health checks and things like that. You know, all the boring the boring things. So,
that brings us to the end of the talk today, folks. And I hope you were able to take something away from this today. I'm going to be floating around all day. I'd love to talk to people about this approach and this idea and simplifying threat detection just to make life easier on all of us. I open the floor to you all now. Anybody got any questions?
>> Hello. So with a lot of your methodology, could you do a lot of the same thing with you could? Yes. And that's a really really great point. Everything you have seen today can be done in those common languages. So SPL, KQL, it's actually works really well in both of those. So it does not sure necessarily how much of a grey log but um for the main the main set of data leak sim providers yeah it works perfectly well in those. I actually um built something like this very similarly in SPL before and need to play around with KQL a little bit but similar sort of idea. Yeah I think there was somebody else had
their hand up. I'm not sure. Yes. Hello.
Exactly that. Yes.
>> Exactly that. And for anybody who didn't hear that, um, the lady here said that you need a lot of discipline. You essentially need to approach threat detection like a software from a software engineering standpoint. in a software engineering mindset. And the reality of that is yes, that's very true. And that can actually be a difficult part there is making sure that your team are disciplined and are open to the idea of change and new structure and simplification. Um, but yes, we're moving into a world where data is everything. It's critical and we really need to make sure that we move with the times. We don't get stuck behind. Otherwise, we're going to have to move
to something like this eventually. Why not just do it right now? All right. Um I put these slides up on my GitHub if anybody wants to take these. There's some information in the notes and things as well. So um github.com definitely not Wilco. I can assure you it may may not be me. Um so you can go to there. These slides will be up potentially be up there uh in the next couple days. And yeah, I look forward to chatting with everybody for the rest of the conference today. So, thanks very much everybody. Appreciate it. [applause]
Thanks Aaron. Really interesting talk and uh yeah, lot of fun. Uh so we have a short break now for coffee. Um talks start back up at 11. It for some reason it says 45 minutes duration on the program, but that's just a typo. So you don't get that long for coffee. And uh yeah, I'll see us all back here or back downstairs at half 11. Thanks all. >> Thank you so much for letting me borrow your laptop. >> I appreciate that a lot, sir. >> Now my battery hopefully the battery doesn't die halfway through. >> I never had that problem last year, so I didn't. But hey, >> it's weird setups and yeah, driver stuff. Hello.
>> Are you on after the break? Andrew will be your friend for that. >> Yes. Um, [clears throat] what am I doing? It's just an intro. >> It's just intro.
Related talks
 28:33
28:33 32:15
32:15 21:39
21:39 34:36
34:36 47:02
47:02 10:58
10:58