LeXSS - Bypassing Lexical Parsing Security Controls

Show original YouTube description
Show transcript [en]
my name is chris i work for bishop fox doing offensive security today i'm going to demonstrate a hacking technique a little context behind this talk if you've ever been hacking a website and you have like html injection but not quite cross-site scripting this is a technique you can use to potentially get cross-site scripting so in order to fully understand this you have to have some like basic understanding and a little deeper understanding of how html is actually parsed um a very relevant pieces name spaces and their relation to the html parser so we'll be going through that as well and then some special parsing rules uh once we go through those understandings we'll get to actual exploitation and go
through some like real world hacks that came out of this uh so here's kind of a high level of how the html parser actually works so the network stage is mostly relevant to us for this talk that just refers to like the html document actually being received by the user's browser so like the network transfer the tokenization this is very interesting to us as attackers this is the like lexical parsing piece of the html parser what this does is essentially when it comes across an html element it's going to create a token for that and it's going to determine the data type that is in that element right and there's four main data types so we have rc data raw text plain text
and data rc data raw text plain text those are all text like pure text all they're going to do is update the page's text data is like computer instruction that's going to alter the page that's what we want as attackers tree construction refers to like when the dom is actually built and written to a tree and then it's actually pushed to the dom which is the html document as we view it script execution is just if you have like a document.right it'll run this process again so to better understand it here's like a visualization of what that looks like say you come across like an iframe tag tag everything in that iframe is going to be
raw text so anything in iframe tags like not the attributes of course but the tag itself is just text so it's a non-dangerous data type which is going to be key once we get to exploitation h1 is just an example of something that's actually computer instruction changing the application so again another way to visualize that is into kind of two categories so we have non-dangerous which is text data and dangerous which is any kind of computer instruction that's we're gonna we're gonna get our like javascript execution as an attacker we want data
so html parser recognizes more than just html it also recognizes math and svg um so these are actually completely different name spaces what that does is it doesn't actually parse exactly the same so it's important to keep in mind that you can use math svg to kind of confuse the parser more so and we'll get into kind of like what that looks like a bit later but the the important takeaway from understanding name spaces is there's three different types they parse slightly differently and the html parser is going to recognize all three
uh in addition to those kind of understandings all the tags you see here and sorry for the like large blob i i pulled it for straightening the spec but every single one of these tags has special parsing rules meaning certain things can occur when these tags are encountered and we'll go through a couple of them and the relevance to that for exploitation so again from the spec these are some of those special parsing rules these certain flags here like title title text area style script iframe no script these are all like non-dangerous types rc data raw text raw text and then plain text is the only one that's actually plain text and then we have
all other tags our data state that's what we want right so on on the right side you can kind of see a visualization of what that looks like rc data is going to be that output encoding if if you've hacked a lot of websites and you can't get xss it's usually from rc data raw text very similar although it looks like it should work but it's just text and then data type you can actually see it's trying to load an image it's trying to alter the page
alright so those are all some caveats kind of a little understanding of how the html parser works we'll get into the relevance of all this now so when html is parsed twice this is what we're trying to hack so when you can inject like a little bit of html this is generally the process you're going to see this is pulled from a what you see is what you get editor if you're unfamiliar with those you've probably used them in like different chat apps things like that where you can like bold text things like that so what happens is you input data it goes through the html parser it then goes through the editor's parser itself
and that's our target as an attacker right so that editor how it works at a like a security level if it detects that data is non-dangerous raw text plain text rc data no further processing happens it just goes through if it detects it's a data type your like on errors are going to be stripped your javascript's getting taken out you don't have code script execution so that is what we're trying to target so essentially like this is the logic of the attack like we supply html we're using the html parser's logic to exploit the sanitizer to be reconstructed because it gets parsed again and that is written to the dom where we get our javascript execution
and that's our goal like as an attacker so here is a test case in tinymce if you're unfamiliar with tinymce it's very widely used what you see is what you get editor and this is a payload that worked so essentially what we're doing here is wrapping text area and iframes followed by the payload so what we're doing is confusing the parser essentially and i'll show you more visualizations and break that down a bit more but the whole goal is to convince that sanitizing parser that it's safe data and in this case this is the payload that worked so we'll look at a little bit what that looks like so here's like a visualization with our like initial
attack plan on how that came out so first we inject our payload the html parser is going to see it correctly right but the sanitizer this is where the bug lies right so it doesn't parse exactly the same as the html parser and that's where you're going to get your bugs that's what you're looking for so that's how it sound it thought everything was in that text area but we had contained text area in an iframe so it's confused it thinks that's safe and then boom we have javascript execution so here's a like another view to like kind of visualize how this attack works essentially you could see how tiny mce would view that so it sees raw text and
everything in rc data so it's not gonna process or strip out our payload we're gonna get javascript execution we're going to be able to control the user's experience how it actually ended in the dom of course we actually got data type in which is the goal
uh here's a little like tree view just to better visualize it really but you can see rc data is essentially a text node in the dom and uh if you're familiar with like how that works if it's a text node you don't have gross site scripting like it's just text there's essentially no way that i know to break out of that data type however you'll see it's actually like a node in the dom that is computer instructions all right so here is another test case uh for walla very similar to tiny mc it's another text editor very common same principle applied to this one right so we're using iframe this time we're wrapping it in a comment
because each parser's a little bit different this is kind of the tricky part of exploitation is figuring out how it works and like what that parser is looking for what that parser allows in this case just wrapping it with like rc data raw text wasn't enough we had to introduce a different name space but as soon as we put math in there um boom we won and it might be hard to see down here but you could see how it actually landed in the dome it was trying to close out the comment because it thought the whole thing was in a comment but we had restricted it
so yeah here's an another view to just like better visualize it because it's pretty key to the like concept here you could see how it ends in the dom like comment this is how it viewed it this is what it thought was happening uh comment of course non-dangerous it's not going to execute if it's a comment this is not actually how it landed in the dom of course because we had contained the comment within iframes and like here's a view of how it actually turned out so the comments contained in that iframe and then we have our data image boom javascript execution popped for a while
this is an organization uh no affiliation but lap analyzer if you've never heard of them they do like data analytics on like what tech stack is used in main large applications so a bit different but it is a parsing vulnerability that's similar uh this was in dom purify if you haven't heard of these two gentlemen michael pintowski and gareth hayes highly recommend reading their work they're really good great work so some testing tips when you want to exploit this yourself or your clients bug bounty whatever you're doing essentially there is kind of a common exploit pattern that's been occurring when we've been employing this tactic it doesn't always work like that though so fuzzing is going to be your friend
essentially try a lot and take notes like an example of that is like if you use a math tag and no further processing occurs don't use math tags like it's not going to work if you're using iframes and you don't get xss but you can see your payload still intact and hasn't been modified but it's encoded that might be like a viable source you want to use that tag of course you can script this out as well although it's like situational i i did write a script but it's a little too janky i wasn't going to release it essentially here's a ton of resources if you want to read in to this subject a bit more
i do have a blog post on this topic i put out recently um actually really proud um happy to like port swigger did an article on it and i was beyond psyched because i have a ton of respect for those guys so to get a mention was was great um that's about it
Related talks
 1:00:03
1:00:03 1:03:19
1:03:19 33:53
33:53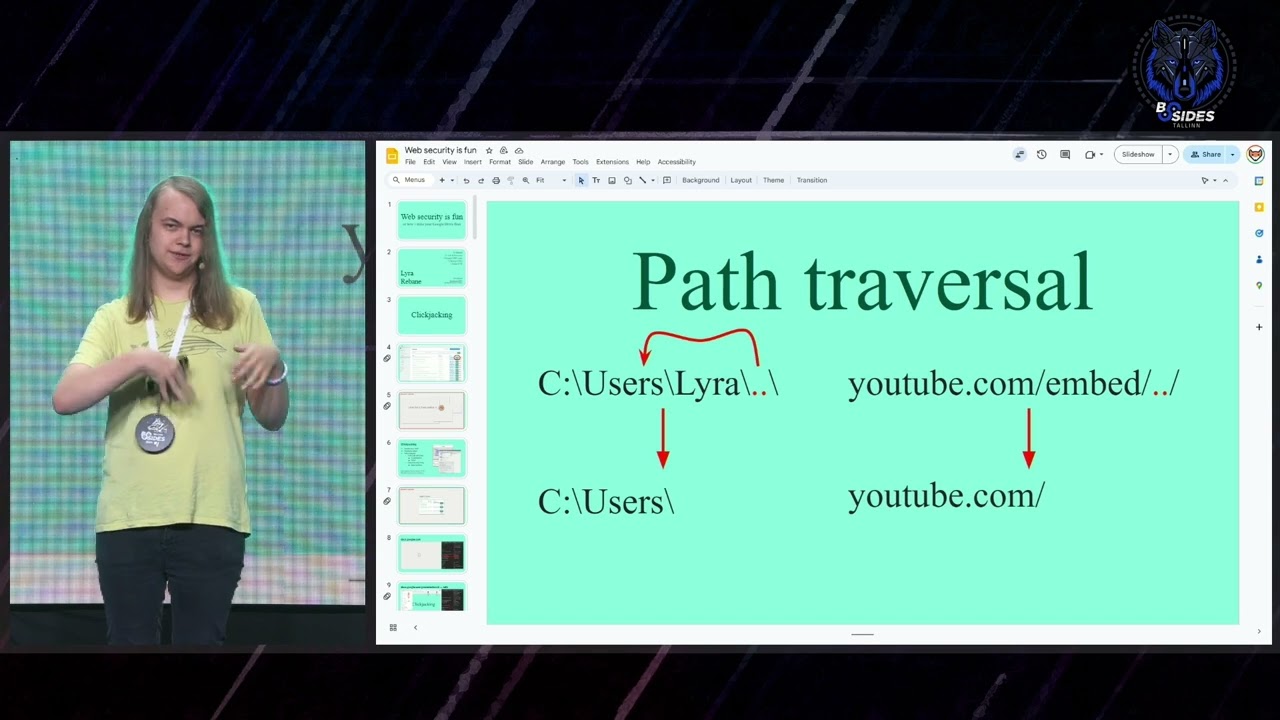 30:26
30:26 41:35
41:35 31:58
31:58