Overwatch: A serverless approach to orchestrating your security automation
Show transcript [en]
hey everyone theater15 let's give it up for Sanchez our next speaker
hey everyone thanks for coming to this talk about OverWatch my name is Sanchez I'm super excited to be here uh b-sides is where I've learned I think most of my security Knowledge from so it's very humbling and you know I'm extremely honored to be able to speak here today um before I actually talk about OverWatch or any of these other buzzwords that you see on the slide just with a show of hands how many of you have heard of the phrase shift left before okay yeah I the lights kind of bright but I think I saw pretty much everyone's hands go up and obviously shift left is this very powerful concept that's been used in our industry quite a bit and
it's generally just to refresh everyone's knowledge it's this idea that the earlier or left that we go into the software development life cycle um the cheaper uh security bugs are to fix and you know just the more traction we get and that's fundamentally why we're here right we're trying to stop security problems before they become a real problem post-production and last I checked which was this morning AI has not completely eliminated our need for shift left just yet so I think this talk is still relevant today um and it was about you know some of the buzzwords on that slide reference security automation right and when we're talking about security Automation in you know while referring to shift left
typically we're talking about the pull request stage uh it's sort of a phase where developers are pushing some code up they're looking for some feedback and we can kind of inject our security feedback somewhere over there and so today we'll talk a little bit about that pull request phase and so what's a practical implementation of shift left add a pull request phase well it could look something like this a simple GitHub actions file that runs some you know my Custom Security Automation and in 15 lines of yaml we have shifted left right we have a way to funnel feedback to our awesome developers that are just waiting to hear about all these security issues that you
know we're detecting in their pipelines but what's what's one of the challenges with this well this is installed in every repository and security is an ever-evolving landscape so as things inevitably change we have to go modify this in every single repository that we've gone and install this in and that's not the only problem sometimes we have one version of our automation that needs to run on a set of repositories and a different version on another and again we're managing managing all of this on a repository by repository basis right which can obviously get a little bit dicey you might say hey that's fine I only have 10 repositories and I'd say God I wish I was in your shoes um
because standard positives I think this approach makes complete sense but as our organizations grow what happens when we hit 100 what happens when we hit a thousand and at chime we're closer to that number and also we understand that there's organizations that vastly outsize us too right it just can get pretty dicey I think again we're all bought into this idea of shift left but I don't think we all signed the dotted line that said hey I want to be a glorified pipeline manager for the rest of my security career um in addition to this you know as we're you know adding different forms of security automation as we identify all these Cool Tools that we want to just
inform developers at their pull request about this is unfortunately what a triaging experience can look like for some people it's you know navigating through a CI Pipeline and parsing the output figuring out if something went wrong or if the tool just broke and for other people it's like logging into single sign-on for the first time of that tool finding their dashboard and the necessary security vulnerabilities and this is obviously just the frustrating experience right so we're trying to combine these two ideas this like non-unified vulnerability management you know way of surfacing issues at the pull request level and just this growing SRE devops type busy work that we didn't really sign up for we're like can we do something better
because we feel like we can so let's quickly throw on our product manager hats and go like what can we build to kind of solve some of these problems and so uh one approach which obviously the paypath concept very well popularized by Netflix we're saying can we use that concept of the pave path but apply it to enabling and managing our security automation right create One path where we're not reprimanding people for not using this what we want to do is create an attractive enough solution that people will voluntarily come and choose our paid path to spin up their own forms of Automation and if we truly are able to get a paid up and running then we
might have a chance of unifying and kind of having an intuitive triaging experience that can come of it you know of like one single path so we're going to try to solve that um we're also trying to going to use some other aspects right like automation should be isolated from each other we don't want it to impact each other we also want to ensure that we're lowering the operational burden we don't want more responsibilities to come so really any failures that come from this should be async we don't want anyone to be on call and lastly you know by default we don't want to play whack-a-mole with our GitHub inventory it's constantly changing so by default everything should
just be covered new and existing and so that last point is actually the simplest one to address first if you're on GitHub and familiar with GitHub apps you can just kind of install this org wide and you can get events from everywhere so this part's fine if you're not familiar with GitHub apps uh basically think of them as glorified service accounts with some amount of permissions you know fine grade permissions you can have it just do very specific things like on pull requests and receive events um just related to pull requests so as we're receiving all these events like for example maybe we receive an event that a certain developer has pushed to commit to a pull
request and now we want to do something about it well we have to send these events somewhere so what we're going to do is spin up a very simple go web server and we're going to send events to like this GitHub events endpoint right so we have some place that all these events are landing and and as a name suggests it says that blue box says orchestrator right so it's going to do some orchestration like things it's going to decide for a given event should I run any forms of automation or not and these forms of automation as you saw from our requirements very easily kind of lead us to this Lambda route they're isolated there's less Ops with them
they're ephemeral they kind of fit that requirements very well and as we're going through this remember we're trying to reduce the burden on anybody spinning up or using our pave path what we're going to do is take any common functionality so think of parsing a git diff or cloning some code or you know manipulating in any way that is shared across multiple forms of automation we're going to have our orchestrator just handle that don't put it on the lambdas let's take the burden on the platform and just create that pave path for everyone to walk through there's two names of lambdas up there somewhere up and break man but they're not the only ones we've integrated we have six today
one around the corner and more coming and I promise this isn't some type of flex of like we have more automation than you like that's not the purpose of this at all this list will grow and reduce in size as required we're just chasing high confidence stuff that fits into our program but it needs to be very flexible this is just transparency um a little bit more insight into this orchestrator itself uh I mentioned you know four given requests should I trigger some automation or should I not um so some examples are like there's depend about pull requests and we get tons of them we don't really need to trigger any automation for that um any
security automation for that because really they're they're actually opening pull requests to solve security problems usually in the first place um and so this orchestrator is going to filter out these events and decide for any given event do I actually need to invoke a given Lambda or not that's one of its core responsibilities and everyone's definition of scale is you know something slightly different so again for transparency we receive you know like roughly 22 000 events per day uh which is plenty for the go web server to handle I mean you can handle that just fine spikes can look like you know 3x 4x's volume mostly depending on the GitHub activity that's coming in and
roughly 15 of these events are worth acting on like at least one Lambda will get triggered for any of these given you know for this volume of events basically and as you can see from the slide they're just very cheap to run in case you were wondering about cost um so this is all great okay for a given event it's deciding what to do but the orchestrator still needs to know what lambdas are available which ones to trigger and so kind of emulating that CI experience we have one yaml file essentially inside the OverWatch repository where you can Define and place your lambdas that you want to spin up these have additional certain options you know for example for Brakeman or
sembrap you can add extensions you know certain file names that you want to trigger or Lambda on these are in addition to some of the core you know event parsing that our orchestrator is already doing but remember we're only defining this in one place one yaml file and you can deploy your Lambda out to our entire fleet through this flow and so going back to our diagram a request came in orchestrator decided okay maybe this one's worth acting on you know based on the configurations we triggered some forms of automation some of these lambdas and using some shared flow like the S3 flow and then these lambdas perform their operations they they go ahead and you know drop a
in this case a report to another S3 bucket so as they're finishing they're they're dropping their reports and as those reports are being generated we're going to go respond in a sort of unified way back to the apis we've integrated with in this case GitHub and slack these are the two that we've integrated with yours might look different but just think of these as replaceable apis in case anything ever changed and uh fortunately unfortunately this is not a system designed one-on-one class so I'm not going to talk about every single failure point that could go wrong but just think about this diagram as anything should be allowed to feel here we're not trying to add burden or Ops
work on any you know individual or engineer that is maintaining any part of this diagram so just add you know your SNS topics or retries as you see fit over here and that's something we can talk about later too okay so we talked about unification of alerts a lot so what does that actually look like so here's an example of an alert coming from the semcraft Lambda it's reported inside GitHub and has a pretty intuitive experience there are some triage buttons here if you want to know how to fix the alert you can click on show more details now a lot of this is actually powered by our usage of GitHub Advanced security we are
partnered with them and we're using these API calls so it's really not super magical that this is this alert is showing up but what I think is cool is that for every Lambda that you integrate with our platform there is a unified playing field so now our Breakman alerts our mob SF alerts and every other Lambda you saw integrated they can all report alerts in the exact same way you're not logging into a multiple dashboards and you're all trying to find how to fix vulnerabilities if you've seen even one of these alerts you probably know how to triage them with you know some uniqueness to to each of the lambdas in addition we want to take the Ops down
on our security team we mentioned that and so our security team generally consumes alerts in slack and these are also looking strikingly familiar at this point and so here's alerts from two of our lambdas and Piers alerts from two other lambdas and they're all using a very default template that has been defined by our orchestrator and like anything in this flow you can override it if you need to so need something custom feel free to go at it but here's the pave path or default mode of operation um one note about those buttons our source of Truth we're using as GitHub so any triage you do whether it's a security engineer on the slack side or
if it's somebody triaging on the GitHub side fundamentally they're mapping to the exact same alert we're not syncing alerts across multiple sources and so this lets us do that and any on fixed alerts or anything again they're living in GitHub it's our source of Truth for code related you know security vulnerabilities and that's how we use that and so you might say okay this is all fine cool that you found a way to slightly unify your alerts um but I haven't dealt with Lambda before and like what does that take I kind of miss my 15 lines of of yaml at this point um so let's let's kind of break this down like what's in this Lambda how do
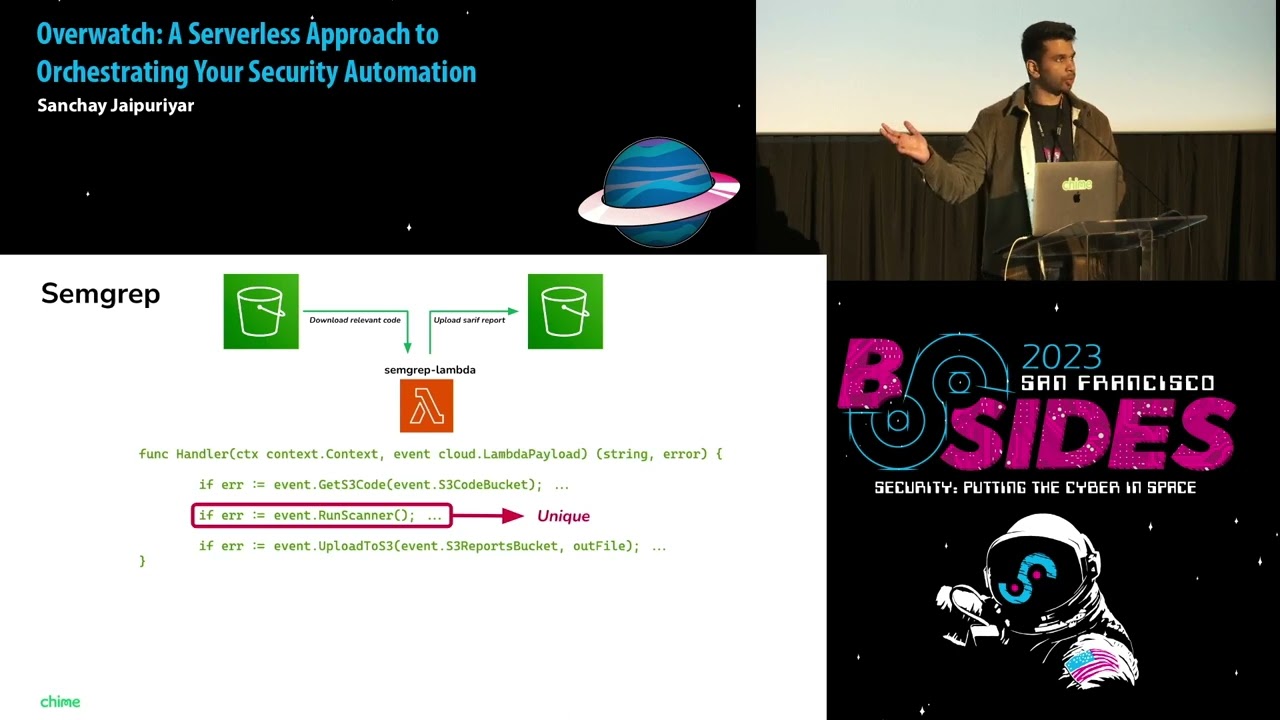
you set it up so we've gotten to the point where all you have to do is add basically one line which is your Lambda function name with some optional parameters like timeout or memory it's going to automatically configure all the necessary resources and permissions that Lambda needs to do its job and just as a reminder its job is essentially pulling some code from S3 running its automation whatever that means and then uploading a report to S3 if it kind of fits that mold and so again if you're not familiar with the code here this is totally fine there's basically just three functions mapping to those exact operations I just destroyed get code do some automation
dump the code I mean sorry dump the report and so the only bit that's actually unique is that section in the middle that's the one that all Lambda authors really control and they can do whatever they want in sem group's example it could be as simple as this one line let's look at the difference in Breakman it's just a different line but that run scanner interface is essentially identical and depending on your automation needs it's in scale upper up or down but the point is it's fairly simple you have the terraform module and then you have this one line that you're fundamentally controlling everything else is shared and imported and you kind of probably need a way to
test this right like hey I have a Lambda I want to see if it's working with the orchestrator I want to see how the alerts are showing up or what it looks like in GitHub and so if you're familiar with versions and aliases and Lambda this will be a little bit obvious too but if not just know that there's a way that every time you push a commit on your test Branch or your custom Branch within your Lambda repository we are creating versions and aliases of your Lambda that you can pin to and you can use so as you merge to main or you know your main production Branch there's a prod version now available and you can you
know in the orchestrator remember that one yaml setting file not just the Lambda function name you can also add this custom version or Alias to pin to that exact version that you want to run with additional options and so why is this powerful why am I telling you about all these versions and aliases well just because we found a way to spam GitHub in the pull request comments it's not what we want to do with all our lambdas so a typical rollout strategy would probably look like hey I want to take the test version of my Lambda I want to run it in slack for a while feel confident about the rules you know maybe a test version
on my test Branch once I'm confident I can merge that in I have a prod version now available and maybe if I'm happy I can turn on GitHub commenting for that and that's a little bit more thoughtful that is not going to ruin trust with your engineering counterparts and gives you a lot to play with one thing to note is you can actually run multiple versions of the same Lambda right like your prod Lambda and a test Lambda all in one place in parallel it's it's all up to you we're just giving all the options to everyone that wants to roll out this Automation and once again remember that anytime you define anything here it's getting deployed
Fleet wide across all your GitHub repositories and so all this also might sound great but really let's highlight what is happening by separating out all these automations like by not rolling it up into like one golden image or keeping them all playing together um really the brakeman Lambda can just fail and it should not impact anything else right and so typically if you were rolling a Breakman check let's say in CI uh this is a flag or like you know a pipeline failure that a developer might see um if you know even if github's down or breakman's not operating well anymore and we really don't want to add this cognitive load to developers in GitHub
at all if it's something that they can't fix if it's something that only the owners of Breakman or that Lambda can fix like why even bother people in in the pull requests so because we control every API call in this entire flow we can actually just suppress it we can suppress from all the pipeline checks that hey Breakman actually never even ran just check out the other stuff that did if there's any action to take on that and and this doesn't mean we're suppressing the alert from Brakeman at all what we're doing is reducing the burden on the team managing brake man because we're filling up their dashboard so here's a default data dog dashboard
for the Breakman Lambda they can come and debug this as they see fit in their own time they're not on call they don't have to respond immediately and they're not blocking any CI pipelines in GitHub um and so one of the cool things of setting up a flow like this is we actually have an extremely talented team at chime working at service to service authorization authentication if you don't know what that means that's totally fine just know that they had a custom enough way that they couldn't just roll up rules in semcraft it required spinning up their own automation very custom configuration checks that had a lot of dynamic elements to it and really what they
wanted to do is nudge developers to use the right authorization schemes over time they wanted slack alerts for every invalid configuration and you know spoiler alert do we have a tool or a pave path that can kind of solve their problem for them and that's exactly what they chose so we rolled their form of automation fleetwide via OverWatch and it's not exactly an appsec example right it's not like running semcraft or Brakeman this is slightly modified but still fits the pave path model going even further and this one excited me a lot is we had engineering teams outside of our security team reaching out to us they were like hey we heard about a tool that can nudge people to do
the right thing in a different direction it can give us slack alerts you can deploy it Fleet wide on you know just one yaml configuration we're deprecating a database and we don't want people to be using this database pattern anymore can we add a rule to OverWatch of course we said yes and so here's a Sam rep rule that basically they added to dynamically you know prevent people from changing a deprecated path and they had a rollout strategy for them and that team completely owns that rule but they're not taking any SRE burden they're not they don't have to flag all these anti-patterns or spin up their own automation NCI pipelines they're just getting this through our pave path
approach for their non-security use case and so going back to the diagram right like this flow like a good way to think about it is sort of like Lego blocks each component is sort of independent you don't have to use this entire diagram from left to right we're not creating one right way to use it you saw different scenarios where people are just taking advantages of what we've built and the flexibility we've done it with and just building on top of it and so maybe you have you know some automation you're happy with in an AWS account or a confined kubernetes namespace and you just want to drop a report in an S3 bucket and get it take
advantage of the apis that we have with GitHub and slack that's possible too you can skip everything in the middle totally up to you um and you know surprise surprise like most engineering projects things are not linear I wish they were but they're they're really not so there's bumps along the way and especially if you're building something like this from scratch like a platform from scratch most likely you will regress first before things get better um and so there are some examples of you know we didn't have our terraform module uh and so until we had that it was slightly harder to spin up a Lambda so all these things can kind of cause different sort of bumps and local local
maximums as you're going forward and it's not a linear path I think this is pretty obvious for most engineering projects but it's worth reiterating um and so with that just like some you know key takeaways uh we totally understand OverWatch doesn't fit everyone's you know organization it won't or this approach won't but you know can your organization sort of benefit and by your organization I mean your security Engineers your developers sort of benefit from a pave path like approach to managing your automation you know burnout's pretty prevalent in our industry I don't think we need to make this problem worse um and if if not through OverWatch I think there's a lot of other projects or
vendors depending on your requirements because they'll look different than our requirements um that could fit your needs so coinbase has had a project for a very long time I think it's it's fantastic again you'll see where it deviates uh from our approach where we've split up our Automation and we're heavily leveraging the serverless aspect of it but if you know one image works for you and all the automations rolled up would highly recommend you check out that project in addition we use the sem rep app pretty successfully for a very long time while we were building up the capabilities of this platform it has fantastic commenting you know you can deploy it org-wide really well in fact one of the
downsides was it made our other tooling look bad because like all its triaging is good it's like how do we get Brakeman to look that good too hence coming back to our pave path approach and so lastly just wrapping up whether you love or hate this approach we'd love to hear from you um here's some ways to contact me directly or our team um we do intend to write more about this project but uh if you want us to you know prioritize open sourcing it or you think this would fit your organization definitely let us know it'll help us you know prioritize that roadmap we are not hiring as much as we'd like to at the
moment but we are hiring for a security engineer in the data security space that should be coming up on our careers website soon there's lots of other cool projects happening at chime um you know like this one and lastly thank you so much I know it's a choice being here deeply appreciate our time thank you
folks in the audience we have a little bit of time left for our next speaker uh folks who want to ask a question please raise your hand and speak loudly we're asked to have the mic so everyone can hear what you're saying and understand what beautiful thoughts you
hey Sanjay really interesting work uh I was curious about how you think about uh kind of the filtering or the aggregation layer on top of these alerts so like I assume that you know one of the images is you got a lot of you know um you're able to give you alerts in context but like do you see a lot of false positives and how do you address that yeah fantastic question so um really we try as much as self-service to uh whoever's spinning up the automation uh one thing we've seen in practice is security can be very specialized right so it's hard for one engineer to know kind of all the details about all these different types
of security tooling so really what we try to do is uh just give the flexibility to whoever's spinning up the automation to go tune the alerts correctly like all the versioning of lambdas and all that um to let them test out enough so that they're kind of happy with their results but we have um basically built out in the platform some certain types of Primitives to ensure that people aren't getting blocked or spammed so for example for any new form of automation rolling through a platform will automatically ensure that you can't block pipelines it's just like the default until we get some data again we control all the data throughout the entire flow so until we
get data that kind of indicates that hey people are actually fixing this or there's a good sort of hit rate then we can kind of open up those possibilities automatically but that's one way we try to look at it
oh I see one one hand I'm looking there
yeah great question uh so I think the question was uh I'm sorry I didn't repeat the previous question but I think the question was what what do you do when you need a copy of the full code and not just uh you know the diff code um so certain you know forms of automation oops certain forms of automation operate a little bit differently so things you know scanners like break man need a full copy of perhaps a code to uh performance execution things like code ql sound rep can just op copy on it you know sorry operate on a diff um and so the platform is just giving you all those options basically and so
that S3 code caching step it will upload both a diff and a full code copy and depending on what your automation needs to pull down and operate on it can just like pull pull the right copy but the actual parsing of it is happening by the platform um so yeah hopefully that answered that question see one hand over there um oops
hello yep okay so uh what do you think about uh individual pull request scanning versus an entire repo scanning uh the use case that I have here is uh maybe 15 to 20 lines of code pull request might not be containing the security input validation or any kind of mechanism that we want to actually check so which basically triggers some kind of false positives for the developers right so in those particular situations how how do you guys actually handle it and find unit right great question just to make sure I'm understanding the question correctly essentially what you're saying is hey like the diff only modified like let's say 15 lines but you know without the full context of everything happening
around it I mean Miss vulnerability so how do we handle those type of situations is that the question even with the false positives I mean let's say for example some kind of vulnerable function has been used and you are basically flagging it out but at the same time the developer might be implementing some kind of controls at a different uh stage of that particular code right right so so basically great question it's just so like how do we get the context from all the other things that was not modified to get the the best answer to whether this is a vulnerability or not and actually very related to uh mukin's previous question uh what we do is if an automation
requires a full story you know compiled code or full code to give you the more concrete answers we will let it do that even at the pull request level all it will do on top of that is once it's fully computed you know the full code and it's gone through everything what we will pull out is if the vulnerability truly was created by modifying those files like did the net new files really cause this new vulnerability and if so we will report it back in the pull request if not if that wasn't the case and that vulnerability is just lurking around from you know some other means or Legacy code we're just uploading it you
know regularly into the GitHub Advanced security dashboard but not on a pull request level That's Just Happening as sort of a nightly roll up okay and doesn't that slow down the scan process the full code technically it doesn't because the the lambdas really like because we're caching one copy of full code and each Lambda doesn't need to pull its own copy and oper you know operate on it for the most part all the git stuff is already taken care of and so if a Lambda fails it can just retry from the point of pulling that you know zipped copy of the coded needs and then to operate typically we just put a five minute timeout in every scanner you saw
is able to operate um you know within that timeout but we can increase it slightly if we need to thanks great questions thank you for question thank you so much [Applause]
Related talks
 20:40
20:40 46:38
46:38 47:24
47:24 30:48
30:48 46:31
46:31 30:28
30:28