Making Sense of Unstructured Threat Data
Show transcript [en]
our first talk here will be making sense of unstructured threat data by Xena and Nikolas our presenters on the data science team at Troost are working on improving threat intelligence platforms and workflows let's go Xena a warm welcome alright perfect thank you so much for introducing me but I'm also going to introduce myself so I'm a data scientist at free star I have we do a bunch of interesting machine learning and IV stuff and all of that stuff usually has an impact on the prior and one of the those NLP things that we do at least are I'm going to be talking about today before this I bought my master's in data science from USF and when I'm not doing
a sign saying I'm drinking chai and I know I look really nice in this victory alright so the title of this talk is making sense of unstructured data and a lot of people told me that the style is sounds kind of boring and maybe I should introduce some interesting pop-culture references and you guys I tried you know I really try to think of something but I could not and therefore I'm gonna leave you with us apologies in advance to people who do not watch Game of Thrones but I swear to god this makes sense so Daenerys speaks a bunch of different languages and this is natural language processing right so yeah all right so we're gonna dive right in and talk about
the purpose of this entire exercise and the purpose of this exercise was to establish some sort of a link between two completely diverse sources of data so you have data from the nest vulnerability database and you have data from the miner attack framework and even if you do not have a security background I'm definitely going to go into the details of what each of these things means so don't worry about that let's start with the matter doc framework so I feel like in order to sum it up the two most important concepts that anybody needs to know about The MITRE tag framework would be tactics and techniques so a tactic is an overarching objective right it represents the why or
what are you trying to achieve and a technique essentially it represents how you're going to achieve that tactic so to make it more concrete let's look at an example on the right hand side no sorry the left hand side you have a really pretty graphic of a matrix I made that myself and every single column of the matrix represent a tactic every single row of the matrix represents a technique so initial access let's say is a tactic and drive-by compromise exploit public facing applications these are all techniques that you can use to accomplish the atactic so the entire point of showing this slide was to just make sure that everyone knows how data rich this repository is once you're able
to connect any indicator data to the miter tag framework you have access to any character groups that might be targeting you any medication strategies for the techniques detection methods as well as any references that may have been made in the past in terms of you know a malware or a software that leverage that technique or any other article that was written about that technique so to make it even clearer let's look at some of the attack objects and look at how they're related to each other so there is the concept of an adversary group these are the bad guys and they would use a technique which accomplishes a tactic right and the adversary group in order to use that
technique will have to use a software so the software in this case is the bad kind right it's a malware and the malware will implement the technique in order to accomplish the tactic so what am i introducing into this entire framework I'm introducing the concept of a vulnerability so this is where I believe a vulnerability and into this entire graphic write a malware with target a vulnerability which would implement a technique which accomplishes a tactic so if you're foggy on the idea of a vulnerability it's essentially something that's wrong with your software and there's thread actors right there's bad guys out there that want to target that vulnerability in order to target you and essentially what
you want to do is you want to patch those vulnerabilities up so you're safe from all of those targets so let's go into the fun and healthy stuff and I'm sure every time you guys open LinkedIn you see the words NFPA I did a science and I'm sure most people are just tired of hearing these words and I'm sorry about that but I promise this isn't fake we actually did this stuff and it works so let's drive in word to back is a cool NLP technique and what does it do it teaches a computer to understand interpret and manipulate human language right and why do you want to do that you have a bunch of unstructured data and it
has to make sense mathematically somehow so what you're going to do is you're going to take all of that data and convert it into numbers now the how part is actually what's really interesting so how does where to back actually make sense of all of those words right it works kind of like our brain does except like all of that stuff is happening unconsciously but imagine if you don't know another language and you hear a word from another language thrown around around with a language that you do not write you're going to use the context that you do know off to understand the meaning of that word similarly like that's just how we're due at words so as
the example I have over here is I see ants on the tree and let's say that your target word is ants so you're trying to understand what the word ants means and I mean you're gonna leverage the words that you see around and so I see on and uh in order to understand what ants means now you're probably thinking but wait like none of these words actually convey the meaning of the word hat and that is true right like you can pretty much see anything mana tree you can see trees branches pretty much anything I just say who can see a tree on a tree I think I did anyway so my point is that
there is going to be other sentences in your corpus that will actually have words that are representative of the word hands and what happens is it goes through this neural network and eventually what you end up with is a vector that represents the meaning of the word axe and on its own that vector means absolutely nothing but if you look at that vector in conjunction with other word vectors it means everything so the vector for the word hands should technically be close to the word vector for spiders right because spider is also an insect ant ant is an insect beetles maybe and similarly let's say you have the vector for the word King and if you add another
vector through the word King you should get the vector for the word Queen and that same relationship should persist between all the other male and female objects so so far we've done like a sort of a Couture example now let's dive into what we actually did so I know this is an information overload but we just talked about where to bike and how I'd love which is context in order to understand the meaning of words now we're going to talk about dr. wack and the idea is still the same still leverage in context and what you're trying to do is you're trying to predict a vector for a document except this time it's a paragraph and you're taking
context words from the paragraph in order to get a vector for the paragraph and what eventually happens is it goes through the network and you have a neat little vector that represents the meaning of that document so let's go over our process really quick we had data from the NIST database we had data from the attack framework all of that data comes in we clean it up we get rid of anything that we feel is not really going to convey the meaning of that document so we got rid of any emails any URL it's all of the stuff that we thought was unnecessary after that you'd organize it so tokenize essentially just a process of breaking a paragraph down
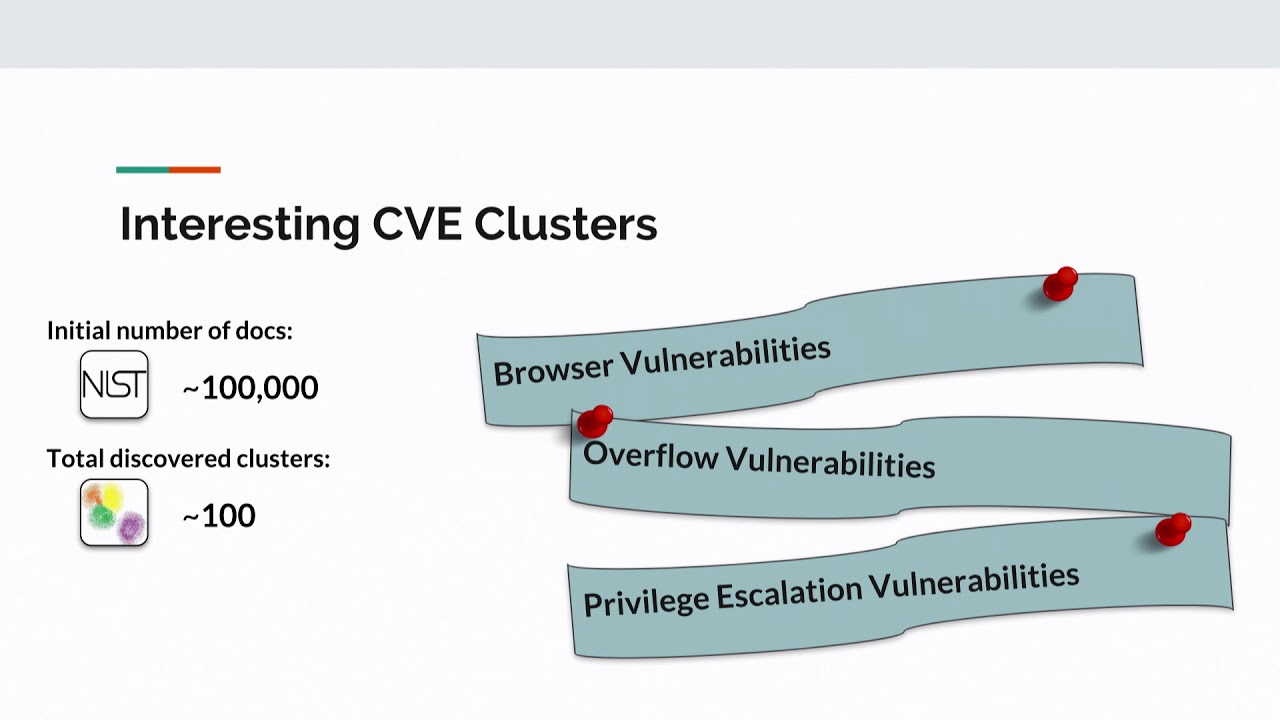
into its component words after tokenizing it goes through the algorithm which is the brain or the neuron that break that I just spoke about and what you end up with is a vector that represents the meaning of every single document in your corpus so now you're probably wondering okay we went through all of this what came out of it so I'm gonna start I'm gonna preface this discussion by talking about some interesting CVE clustering that I did so I cluster together a ball of the CVEs that I had all of their word backers all of their paragraph factors actually and I found some really interesting clusters so there was one which only had vulnerabilities from web browsers and I
thought it was really cool how the algorithm actually managed to recognize that Google from Safari Mozilla Firefox and Oprah are all web browsers and put all of their vulnerabilities together in the same cluster another cluster that I thought was worth mentioning was this one so this one just had something about DLL hijacking honestly I've read through so many vulnerabilities by now I manually label all of this data I still don't really know what's going on here but you know I just know it's a few words like DLL and that's what I saw over here it was all talking about fat reversal vulnerabilities DLL hijacking that's what was going on in the semester and there is a reason why I brought this up
so our initial our initial goal with this entire exercise was to make a connection between the attack framework and the vulnerabilities database so over here I have an example of an attack technique it's a description and I don't really expect anyone to be through this just really focus on what I've highlighted which is die lame right and what happened is it managed to make the connection between die live and a vulnerability description which talks about DLL now what I also want everyone to notice is die live is not mentioned in the vulnerability and DLL is not mentioned in the attack description however it lovers that contact that I've been talking about again and again so
far and managed to understand that DLL and Die lab actually mean the same thing and that these two are probably connected and now why did I show you that cluster from vll hijacking because if you manage to make connect this technique to even one vulnerability you know all of the other that looks similar to this one durability so essentially you have managed to connect this to all of the vulnerabilities about DLL hijacking so let's actually see this in action does it really work I have uploaded all of this data in a repository do not worry about that let's do a quick run through of this notebook just gonna talk like really vaguely about everything but
everything's on github so god the libraries there's a few helper functions that clean the data you know I'll get rid of any URLs and the citations there's a wrapper function then there is functions that I got from The MITRE a github repository super hot code by the way definitely check it out all of this all of these functions essentially help me help me fetch the data and then you extract the data from my adorable as nest did you band clean all of that data up create APIs get it in a format that the algorithm accepts set up doctoral training we tried three different models just to make sure that I had the best results and the one that worked best for
me was distributed bag of words representation if anybody is interested I have linked the two research papers that I read for this where to work as well as dr. back in my slides go through them super cool so over here is an example of a vulnerability and like what other vulnerable uper close to it and again sorry it's annoying to read but they're actually very similar I read through them so I can promise you that they're also on github so of course with that then let's talk about clusters so I talked about how I made vulnerability clusters and this is an example of that same cluster so you have a cluster about that's about DLL hijacking and we
managed to connect that to an attack pattern so this is the example of the attack pattern that I showed talks about die Lib and it's connected to a dll hijacking vulnerability I'm sorry that I went this fast through this but definitely look at github everything's there you can take your own time and like really slowly go through this so I've shown you sort of a demo let's actually start talking about results how well did this work now the thing with this kind of stuff is when you actually want to evaluate such stuff I had to like manually peruse all of these clusters read through all of these vulnerabilities see if the cluster has made any sense I actually labeled a lot
of clusters myself also labeled a bunch of attack and vulnerability legs and these are the results we've got now yes I'm giving myself a medal for fifty percent accurate associations and you probably pay wait no that kind of sounds not that great but bear in mind that these are two completely different datasets right so normally when you do this exercise it's on a dataset that's talking about the same thing or a similar thing so let's say I am DB movie reviews dataset right all of those reviews are essentially centered around around a movie whether or not they're saying good things or bad things that doesn't matter what matters is they're all about a movie in this
particular case though the structures of the two datasets are extremely different so with the attack techniques you have a very verbose a very detailed description of a technique right except with the vulnerability data you know it's usually a one or two aligner very to-the-point talks about a vulnerability super-quick and that's it so the point is that connecting these two diverse datasets and like managing to get this level of accuracy is pretty decent and the only baseline metric that I could think of actually comparing this will was the probability of getting it right if I assigned it at random so that's to a little bit of math here we started with a hundred thousand mother abilities we created a hundred clusters
because that was the most naturally occurring number of clusters I tried it with a bunch of other numbers I tried like more than 100 less than 100 and 100 was the number that we settled on we felt like naturally that's number of teams that are represented in this vulnerability data so the probability of actually getting it right if you assigned a vulnerability to an attack pattern at random it is 1% so this is 15 times better than that so what does it all mean if you're a security analyst for a security engineer and how will this entire exercise help you the only way that I could summarize this was to say organization prioritization as an
organization you know in the attack framework where your weaknesses lie you know what you need to focus on and if you focus on those techniques and if you manage to connect those techniques to vulnerabilities you also know what software you've been using and then you can patch all of those vulnerabilities and actually you know save yourself from threat actors and that brings me to the end of this presentation I feel like it was super short but maybe it's because I started early huge shout out to Niko my manager who encouraged me to actually do this and told me to on this super excited to be representing women at the stock also it's kind of unfortunate that
my talk - is with diversity and cybersecurity you talk I wish I was able to attend that but I see a few women at least like seven women in this room so that's great thank you for being here and questions I guess [Applause] Wow
so I'm not entirely sure I understand your question you're talking about like using a much bigger deicide to do this
a few what
uh-huh
oh yeah 100% so it's an ongoing process obviously as you add more and more vulnerabilities they've become part of the training set and eventually you will like these clusters may process maybe you'll have even newly agrarian clusters that come as the data as more data comes in so 100% it's an ongoing process and yes you can do that all right so you have the train data you have the Train model right well the only thing that you really need to do is just feed it data so the functions that I have on my github repository very friendly the only thing you need to put in is the attack technique or like a CV Eid and it throws
you everything maybe that serves all of your questions any other questions yes yes that's what's next that's a great question very open-ended thank you so much for asking that so I have open source this tool already I'm gonna make it better I'm gonna make it more friendly I'm actually planning on working with a few security professionals so right now I feel like maybe like that guy said maybe I've been focusing on the data science aspect of it but I need to make it more user friendly so the idea is to turn it into a full-blown tool that people can actually use without any discomfort yes
oh that's actually a really good question so as I was going through these clusters I realized that there is a lot of overlap between techniques in the attack framework and like in some cases actually notice that some techniques exactly the same different attack ideas that is very space and efficient another thing that I noticed was that some techniques they actually have this very similar descriptions conveying the same meaning obviously we're to get caught onto that but again different attack IDs which is something that they need to work on maybe they can cluster them together put them all under the same heading instead of like having several different IDs attached to the same thing so anymore we've got some time okay so
why did I give Zeinab a token of appreciation from besides for presenting thank you
Related talks
 28:29
28:29 29:24
29:24 32:13
32:13 30:17
30:17 38:53
38:53 32:39
32:39