Building a sustainable detector development lifecycle
Show transcript [en]
hey everyone I've got Paul limey from tuteria and I'm going to be speaking on detectors as code all right I'm going to try to do this without a mic because I don't like using mics and I'm also going to try to speed run this uh presentation so hold on to any questions till the end uh real quick my name is Paul Ami I'm a co-founder of soteria my background I've done some work in the air force uh offense at the NSA and cybercom uh that work from JPMorgan and IRS and their defensive units uh also can really operate an edger and make a mean chicken tender if anybody wants anything like that but in my career I've done a lot of
uh the offense defense and and special teams GRC type of stuff so I've kind of been around the block and done a lot of different stuff but today we're going to talk a bit about detection engineering so just uh setting the stage real quick for what is detection engineering uh to me it's really about going and trying to find the capabilities that you need to build in order to find bad things happening within within your environment right so it used to be that you would go buy uh you know whatever uh you know McAfee selling at the time install their antivirus and hope for the best you know throw a firewall in and you know you can
go at it but for the last 10 years or so between you know EDR tools Sims ndr tools those types of things you can really build very customizable tools that are very unique to your environment can meet your needs so to me detection engineering is about figuring out what's out there on the market going out procuring those tools or installing them customizing those capabilities building your own rules detection logic so on and so forth testing verifying that they make to make sure that they work in your environment the way that you want them to maintaining them to keep up with threats and then you know when things don't make any sense from a cost benefit analysis
anymore you get rid of them and go on so it's a life cycle and it's something that we have to have to keep up with but I want to talk about detectors as code and the way that we do detection engineering at soteria so we do a lot of MDR work manage detection and response where we're doing this on behalf of our customers and in order to make this scale we have to do a lot of this via code right so first and foremost why don't we just you know use the GUI right uh and and these are the reasons these are the things that I've seen over and over again as we looked into different security
operations centers or looked at different people trying to defend their Networks you have people who just kind of log into their Sim they write a query they think this is a good query I'm going to save that and make it a detection capability or you can do the same thing via EDR or whatever and you uh you're left with a lot of questions one you don't really know what you have right you know you've got a lot of people who are going in there and saving rules uh creating new queries but if somebody said hey you know can we detect X right can we detect this new Microsoft Felina exploit that came out earlier this year uh you know everybody's kind
of looking around at themselves and and uh you know maybe we can go and look at the list of queries but there's no real uh core base of knowledge of what the capabilities are in a given organization another one is you had no idea if these rules really work and that's really tricky in a lot of environments right you write a query it comes back with nothing and you're like well did we just not get popped or uh is this a bad rule I don't know so there's no real rigor around trying to figure that kind of thing out uh or the opposite can be true you put in this new detection capability and then the next thing you know your your
Sims flooded because you've got you know 10 000 hits coming in a second uh because you accidentally wrote a rule that will detect on any new processes launched within the environment uh and then uh and this has happened right uh and another thing is like mysterious alert so you have some genius uh you know Sim engineer who writes her her Rule and saves it and then uh then an alert fires in the middle of the night and your overnight analyst gets the alert and says what the hell do I do with this I don't know what this means how do I investigate this and you know it's pretty much worthless in that sense or somebody goes in they they make a
change to a rule and it breaks everything but nobody remembers what it was like before and you're just kind of left there's uh stuck looking at it right so this is why we take a detectors as code methodology right you want to be able to track requirements uh from a detection standpoint from where did this requirement go to how did it get implemented and vice versa what is this detection can we track this back to the requirement that that made it exist in the first place having Source control using developer tools like git uh will allow you to have a full history of that detection capability from the time it was first created every change that was
ever made and you can attribute each of those changes to individuals within your organization uh you can establish coding and documentation standards that way you make sure that when people create these new capabilities you have documentation to go along with it that way it survives past the the mind of whoever created in the first place uh you can do some unit testing and you can do some some continuous delivery type of stuff so all of this is really trying to implement these uh these these capabilities that software Engineers have been doing for years right like cicd is the buzzword that everybody uses and usually people are doing continuous deployment not necessarily integration but the software Engineers have been
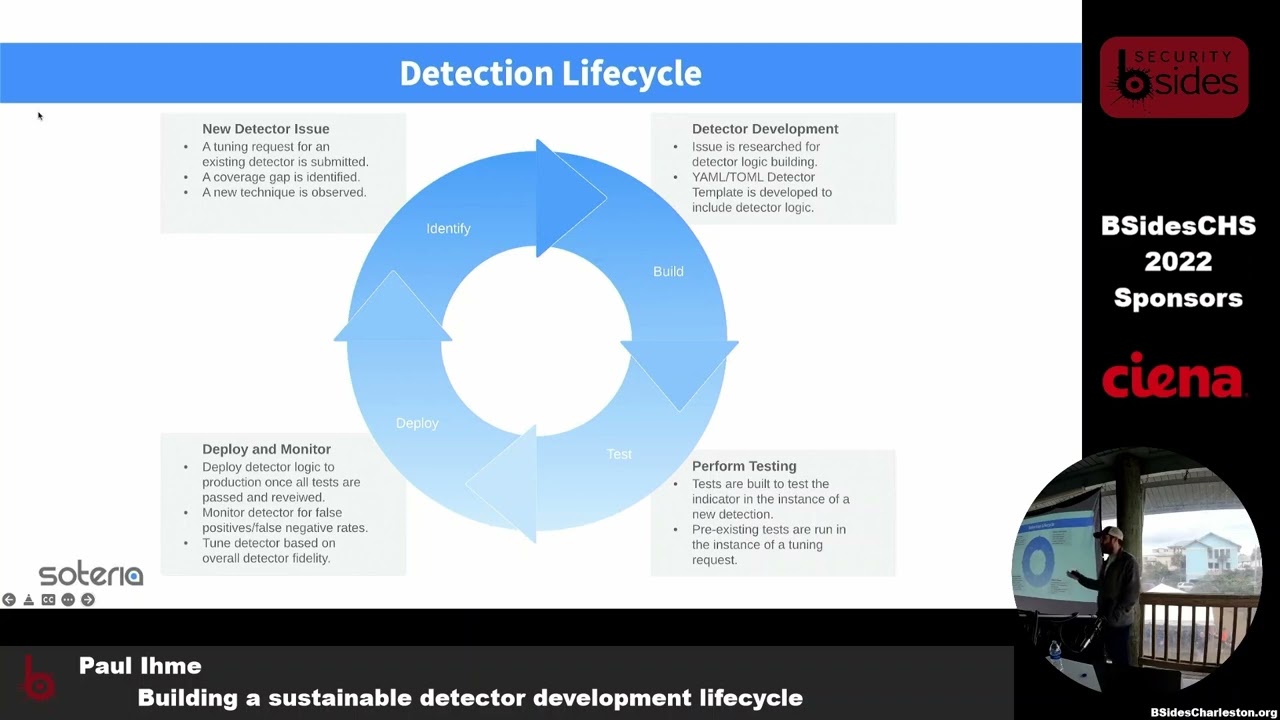
doing this forever and there's no reason why your your security operations team shouldn't be doing the same thing because it works and it fixed a lot of problems so uh we're going to talk about our approach how we go about implementing detectors as code at ceteria and we're going to talk about you know we've been doing this for five years and we've screwed up a lot so we're going to talk about some of the things that we've learned along the way and uh and how we've gotten better over the years okay so real quick uh just talking about our detection life cycle so this is a little bit oversimplified but at a high level this is how it works right first you
have on on your upper left you have a new detector issue so somebody's got an idea or I read this thing on Twitter or Mastodon now I guess or uh you know some offset guy you know came up with this new technique that uh that he wants to know if we have a capability for so you say hey we got an idea can we detect this you go and research it say nope let's take a look then that gets passed over to your detection engineering team so they can go out and build this detector and that may mean using tools you already have to write a rule it may mean going out and procuring some new technology that to
fill that Gap or some combination or changing the way you look at it but you have to uh to figure out how to develop this logic and this capability within your organization and then you're going to do testing right because we're not going to put anything in production without testing it right so we're going to find a way to test uh test these new capabilities against some sort of telemetry that we can generate to make sure that it works the way we want to and to make sure it's not you know Ultra false positive phone prone so it's not going to flood your team with a bunch of noise that's not useful then you can deploy it and you're going
to learn lessons once you actually deploy this in production because nothing ever Works in testing like it does in production and it's going to just go around in that Circle and and you're going to continue to refine these things so phase one uh submitting new detectors right uh the way that we've done this is we just use jira right because we're we're trying to mimic the way that software Engineers do this and and really we just want a few different things one what are we trying to detect what should we be looking for in uh in this detection capability uh we want to have some labels and tags just to make it easy for us to categorize these
things and report on them that's easy and then links to reference material where we have them so going back to some of our lessons learned over the years we used to have a whole lot more stuff that we would ask for when somebody submitted an issue like this and really it's just a barrier to entry nobody wants to write all that who can be bothered with uh with doing all this research right we were asking people to like go ahead and put all the miter attack IDs in there that apply to this tell us about all the potential false positives that might be able to come up and it's just uh you know nobody wants to do that right so we
have we have offensive security folks you know we've got security advisors we've got people who just read blogs and what we wanted to do was create it in a way where anybody could go and just submit an idea and have a very low barrier to entry that way we could go and triage it uh another lesson that we learned is when we first started this we just did this for new detection capabilities and uh you know what we quickly learned is we're going to be doing a lot of tuning a lot of changing to existing rules so we actually created templates that are very similar but also applied to tuning existing detectors that way uh for our
uh our security analysts who are actually triaging alerts on a day-to-day basis they have a very easy way to go submit this back to the detection engineers and make sure that they get the information they need so they can also go and link to like hey we get all these false positives here's some deep links into our tooling for some example events that we don't want to get alerts on anymore can you go fix this makes it very easy and then finally we started using you can see the uh you know create branch and and create uh pull requests we started using smart commits and and GitHub because it allows us to link back to this jira project uh that way if
somebody wants to know like what is this what does this pull request actually trying to achieve and like who who requested this thing it makes it very easy to just go map these requirements back and forth so that's really what this is all about uh you know the first time you go through a sock too if anybody's ever done that that's that's what your Alternatives always want is like this audit trail from you know this requirement into into production so we started mimicking the the same processes that our engineering team uh used to apply to a detection engineering phase two so now we're gonna go to the uh uh develop a detector and uh in a one
hour long version of this talk I would go through and actually create this uh in in real time but uh since we've got 30 minutes uh these are the fields that we we demand that have to exist and be well defined in each one of ours and I'll go through this like you need an ID uh we'll have a status right that could be the archived for for capabilities that will retire some things are just in that testing phase so we're not going to push these out to all of our customers yet we're just going to do it in a testing environment or uh active obviously means yeah this is out there uh description uh this is again one of
those things that makes this useful to people beyond the person who actually wrote the rule uh having a human readable narrative description of like hey here's what this thing is looking for and why it matters references right if you've got blog posts or or you know tweets or tweets or uh you know whatever that you can point to where people are talking about this uh make sure that there's like good reference material because you don't want to write a whole blog post in your documentation here uh miter attack mapping because obviously uh and then investigation and response guidance right so if your most Junior security analyst gets this Alert in the middle of the night what do they
need to look at how do they investigate what are some common false positive scenarios that might exist that you've seen when do you escalate let's do a more senior analyst or is this something that you know immediately escalated and starts your on-call process so making sure that if somebody gets this and they've never seen this detection fire off before they at least have a place to start and they know what to do and they're not left in the dark uh you know some general notes for things that don't really fit neatly into any other categories the actual detector logic and then verifiers so we're going to do our unit testing which is what we want to talk about next right
so unit testing for anything that we're going to put into production we want to know does it actually detect the thing that we're trying to detect does it uh does it detect unintended behavior and then is that uh is that unintended Behavior going to be so noisy it's becomes useless right is it going to be resistant to super high numbers of false positives and then is it resilient enough to withstand Behavior Uh evasion tactics right if you just change the uh the the camel casing of this command is it just going to break everything right is this uh is this detector looking for commands being run on in a specific directory or if you change
the name of a binary is it still going to fire or if you change the port that you're using to uh to you know do this command and control protocol is it going to bypass so making sure that you have these these capabilities to uh to bypass that and test it automatically so some lessons learned here uh you know I mentioned the the old uh the old alert that fires on every new process yeah we've done that so uh that's uh that's something that we learned very early in the process right is every every detection for any type of activity should have a very generic false positive test of like here's just like some process launching and if this
process launching fires this detector then that's bad get rid of it right another thing that we learned is is that you can't really spin up I mean you can and we did for a while but like spinning up containers to run Atomic red team or Caldera or whatever every time you want to go build something super time consuming and then after you start doing this at a high enough scale it takes hours to go and build and deploy new rules to your customers and that's not going to be acceptable so uh so you really have to shrink that feedback loop and make sure that your detection Engineers can really test and understand that their things are working
uh as quickly as possible so one of the the core tools that we use on our uh in our detection platform is uh lima charlie so they're a sponsor today these guys are great if you didn't talk to them you should have uh but they have some really amazing capabilities where you can do replays right which is roughly the equivalent of the Sim of being able to search against historical data and see if your queries are going to hit on anything but what you can also do is you can copy out Raw event data from from the limit Charlie platform in Json format save it to a file and then say replay this rule against a series of events and tell me
if it's going to fire or not right so that's what we started doing within our uh within our detection engineering practices we can go and we can work with our offensive security team or we can go and pull real data from a client where we detected some weird thing that we'd never seen before we can pull that event data anonymize it so we're not you know having actual usernames and IP addresses in there save it within our detection and then every time somebody makes a change to this detection we can say hey this should hit every single time so if somebody goes and and puts in some sort of tune request and it causes this
detection not to fire on this event then it's not good and it needs to fail that fail that unit testing and not be built so uh what we ended up doing uh even still we we had to do a pull request every time we wanted to test something because this was part of our build Pipeline and this continued to cause frustration for our detection Engineers so uh you know everything and Charlie's done via an API so what we did is built a DS code plugin which is where we write most of our rules and we just built a vs code plugin to go and look for these unit tests and actually validate these right there on
our developers workstation that way it takes them a couple of seconds to actually get this feedback so in this uh in this example uh you know what we wanted to do is do some linting and format checks to make sure that the it wasn't going to get some weird syntax error and now they've wasted 30 minutes you know going through the build pipeline for nothing uh Leverage The Limit Charlie replay API to execute uh these rules and then catch overnight events to prevent any sort of untunes right so in this example you'll see and it's kind of weird but uh but this event here in line 276 and this detector that we wrote is named OCTA device registration
false positive event so this is something that we were seeing in one of our clients environments every time OCTA registered a device it would create a false positive for this particular rule so we'd capture those events that cause this to fire and we said this should never fire that we can put these unit tests for the purposes of demonstration and again I would have done this live if I had more time but uh I changed it to fault or to true so saying that this should Fire And now when we run our detector buddy very cleverly named uh when we run our detection engineering tool it'll go through all these verifiers say verify pass verify
password and it goes on down to the bottom and you'll see this verifier failed and then using the limit Charlie API we can print out at the bottom and you can't see the whole thing but we can say this came back as true this came back as true this came back as true and this came back as false so it's a nice debugging tool for our detection Engineers to be able to look and say okay here's the faulty logic that I need to fix in this tool so again this is uh you know it's just all about it's the same with developers right if you're a software engineer you just want to be able to get your feedback going as tight
as you can that way you can fix things and move on and not spend time waiting on something to build that way it can fail and then you have to go back and try it all again right then phase four uh finally uh we get into our the automated pipeline so once all this is done then we want to push the detection out to the detection platform and get it out there going so this is really just a summary of everything that we we talked about so right there on the left this is a flowchart of our entire process you start out with your thread Intel from you know your offensive security or threat Intel team or you know wherever
you find things that idea gets put into Jared passed off to detection Engineers where they will commit something into GitHub using a an issue Branch because we never commit directly to Maine right be a smart commit that's going to be linked back to jira that gets put into a pull request GitHub actions will do all this automated build to uh you know to go and do all of our unit testing make sure it's compatible with the platforms the way we think it is if it passes that unit test it goes to peer review we want other detection Engineers to take a look at this before we push it into production because nobody's allowed to go into production
by themselves uh they can approve the pull request and from that point it gets merged into Main in this case goes straight into the using the lima charlie API gets pushed out to all of our customers and then we're off and running and then all of this you know feeds back into slack because of course everybody uses slack to know whether anything's working at any given time right so I think I I got that in just in time to have some questions any questions uh when you're generating your own sets how do you understand
yep so the question was how do we find blind spots in our coverage and how do we minimize it I think the there's a couple ways but really a big piece of it is miter attack framework right that's the kind of the go-to so we mentioned in in our in our uh in our detector template we're going to map every detector to the miter attack technique so that applies to and during that build process another thing that does that I didn't mention is that it will actually build and update a dynamic you know miter attack tree that you can go and browse to and see what the coverage is and you can see all the red
screens and yellows and and you know whites where you have no coverage so that's that's one piece that's very easily visible a lot of it is is working with customers who are going through pen tests and and just like being very like collaborative with them to say hey you know we found the saying and they're like oh this is a pin test and we said great once you're done with that PIN test can you like tell us if they found anything that we didn't alert on and like let's work together to figure out why and uh you know one of the things that that we've had to come to terms with and I think every Security operation team
does is like you can't detect everything right so you have to you have to just be okay with that like you can't detect unauthorized logins because how do you know if this is unauthorized right so you're going to have gaps you're going to have miter attack techniques that that aren't covered like deleting a file is a miter attack technique if you detect that then you'll destroy you know your team but uh but that's really how we do it so just a combination of using like those known Frameworks and uh and working with our customers and then we have an offensive security team that likes to kind of you know poke at us and like make fun of how bad we
are at our jobs and then we can tell them the same thing uh so we uh it's kind of that competition and going back and forth and saying like hey can you guys detect this and you know hopefully we say yes but if not then we can say oh well let's go set it up and do some testing and and you know put together something to see if we can work out a good way to do that actually this is it a new event generation project when you're using it just like say by another thing already
we uh we we do not use Sigma and we don't pull in pre-built rules but we definitely look at them for inspiration so there's a lot of uh there's a lot of Sigma rules that we have pretty much one-to-one like equivalents of already there's some that that will you know we look at their GitHub repo and we'll say like oh that's a good idea but they do a lot of things that we don't do right we we really optimize to make sure that we have uh when we when we look at this we try to look at attack chains and say can we catch this somewhere and we understand that we're not going to catch it
everywhere along the chain and I think Sigma has a lot of like let's catch everything along the chain in a lot of cases so we try to make sure that we're not getting too much like try to optimize against false positives but uh but we definitely look at that and we're like looking at elastic publishes a lot of rules so we'll uh we'll look at those and we make our rules available to people as well so we we look at that sort of body of work and see what's out there more for inspiration but we don't automate anything because fun story we used to do a lot of network detection and we used the uh the uh
uh the what's proof points threat feed from yeah emerging threats yeah yeah and like you know if you've ever done that like tons and tons of rules and tons and tons of noise and that's what we're trying to avoid is we want to have very very tight control over everything that goes in and we want to know that we built it and we understand everything and not not do any sort of automated rule generation that we don't have that deep understanding of yeah agree with you because when you're looking at those of you that don't know what emerging threats is a rule set that's about 60 yeah detect everything from 1990 going forward right yeah
um but the problem is going through all that data sets and then mapping into minor helps but that all that's matters so please yep yeah yeah and a lot of it like a lot of what we focus on too is behavior based and this is this is another talk right but going into a you know a new CBE coming out right the new like yet another exchange exploit uh if you're going to be looking for that there's there's more generic ways to look at it like looking for shells spawning from IIs processes and things that that will catch every iteration of that or or IES processes providing aspx files and things like that so you can do
like generic detection capabilities where these new exploits come out and you look at them and say hey we don't have to write anything else because we already have coverage uh for that just by nature of this behavior-based rule so that's that's a lot of what we focus on is not trying to detect like the cves to your point like that's what a lot of emerging threats is is can I find this byte pattern that matches this uh this exploit so we try to avoid that because it becomes too like too fitted to the problem
I would say probably 60 40 like High Fidelity like like we we totally have some like stupid rules like looking for a certificate to sign by Benjamin Dopey right who created many cats and those are really signature based rules and those are super high fidelity like if you see that that's always bad news unless it's like a pin tester uh on on your own team but we do a lot of things that are you know strained like uh binaries running out of weird pass so they should never be running out of and uh strange uh you know somebody running who is a system right uh so those types of things is like this could be okay but it could
also be very not okay and that's when it that's when having like this documentation that says like here's what to do and how to investigate this alert really comes in handy
yeah so we have some that are like a good example is like RDP an RDP connection from a public IP address is like a low priority issue like you should probably not have this exposed but you know it's not necessarily something bad but then the same rule but with a successful login uh is uh you know is worse and the same rule but a successful login and it came from Bulgaria is like worser and you know been like kind of escalates and builds on each other like that
Related talks
 36:12
36:12 43:49
43:49 27:45
27:45 40:50
40:50 45:56
45:56 47:48
47:48