GenAI attacks – 2025 Year In Review

Show original YouTube description
Show transcript [en]
All right. Hi everybody. Welcome back to track one. Uh I'm going to be telling you today about some of the issues with generative AI that we've faced in the last year and what can we do about them. So in the last year we've had a slew of these AI generated attacks. We have AI generated malware. There's prompt injections. There's even data destruction. And I'm here to tell you about some of this. So uh and there's tons of different articles about it too. There's hundreds of these. And this was like five minutes of work to just go put all these on the slide. Uh, and every vendor on the planet right now is sending these reports out. So, how do we
cut through all this noise and what what actually matters and what belongs on the risk register when it comes to this generative AI? So, who am I? Uh, I'm a senior PhD student at Georgia Tech. Um, my claim to fame is that I there's a very flattering picture of me on the front page of the Bides website that's been there for 10 years now. Um, and then another fun fact is I'm also the producer of a threat intelligence podcast called the uh adversarial podcast. That's that's kind of where I'm coming from with a lot of this threat intelligence stuff, uh, rather than some of the Georgia Tech research. So, let's get right into it. There's two
main categories that we kind of think about when it comes to these generative AI attacks. There's first there's these attacks that are targeting the AI systems and on the other one that there's these attacks that are assisted by AI tools and both of them are things that we have to think about from this threat intelligence perspective. Uh and we're going to talk a little bit about both of them and I'm going to give you you know one or two examples of each one uh through the year and talk about some trends but we're going to start with these AI target these attacks targeting the AI systems. So, one good way to start looking about this, as all attacks do, is you start
with the OASP top 10. Um, and this, if for those of you who don't know, the OASP top 10 is a ranked list of vulnerabilities by how important they are for a given year. And they update these lists every couple years. So, there's an OASP web top 10. There's this is the LLM top 10. And I'll talk a little bit more about the trends here in a minute. But the first takeaway from it is that clearly there is uh prompt injection is the biggest risk according to the the community right now. Um and so and you can see this on Google too. If you look at Google trends, the number of searches for these prompt injections
have just skyrocketed in the last year alongside searches for things like AI in general. So some quick primer on what a prompt injection is. This is when you write a prompt that tricks an LLM into violating its goals, going off the rails, and getting some other task. So, one reason you might want to do this is if you're talking to an LLM and you want it to solve a cyber security problem. Uh, that's something that I've been dealing with a lot today in the CTF is trying to get the LLM to generate a SQL injection payload. And a lot of the time it says that it's not going to do it for you. So what you want to do is you need
to somehow convince the AI to go against the instructions that it's been given and you need it to generate one of these things for you. Uh so the CTF example is a more benign example of it. But obviously there's a lot of other things that you could do with this. For example, you could generate harmful content. Um there was a talk earlier this year at the Usnik security symposium about how they were able to generate music that was uh white nationalist music and the AI with very few uh prompts were was able to get it to generate things like that. Um, and then there's other things if and a lot of the time in the enterprise setting we
have the AI systems hooked up to various different data sources and we'll see a good example of how that can ruin your day uh for your security team. But one thing you could do is if the AI has access to other data, it has access to mergers and acquisitions data, what everybody's comp is, how much your manager makes, then you would not want to be able to allow the AI to access all of that. So that's this traditional uh direct prompt injection is the idea here. Some of the other fun examples of this that have come up through the year that are a little more fun is for uh this person was complaining about how
the United Airlines uh chat agent which is now LLM based that they were not able to get to an agent. So they had to keep talking to this LLM. So what they ended up doing was they just put in a prompt injection and they had it immediately divert from the loop that it's in and move on to the agent. Um there's also entire communities of jailbreaks for the for chat GPT and for other language models. Uh this basically people will just go post their long and they're kind of funny because sometimes it'll be like a whole story like a fairy tale about trying to say justify why they need to deviate from the prompt injection. Sometimes people threaten it
and that seems to work. Uh but there's all these sorts of prompt injections. But this is nothing new in 2025. This is something that's been around since 2022 is when the is when the term was coined. So what is new with prompt injections? So the new soup of the day is these indirect prompt injections. And these are really a bigger problem when it comes to application security and when you are integrating these prompts and these AI systems into your application. And one my favorite uh my favorite example of it not just because it was announced on my birthday is the uh Google's Gemini uh there were some there were some researchers that were able to
do one of these prompt injections on Gemini using a Google calendar invite and ultimately they were able to control IoT devices that were hooked up to Google accounts. So, I'm going to go into a little bit of detail on this one because I think it's very instructive on how most of these indirect prompt injections work and what we need to look out for when it comes to these. So, the threat model here is that we have a user. This is the Google clip art. Uh, and so the user is using Gemini and they're completely running on Google. And this could be a enterprise user. This particular example is a personal user who's just using Google
for all of their things. So they love to use Gemini and they love to use Google products. They have their all of their calendar events are in Google calendar. Their garage and their windows are hooked up to Google home so they can control it with their app. Uh and they love doing it and they love using Gemini to say what are my events of the day. So then on the other side of here we have a hacker. And the hacker's goal is to open the garage or open the window. I don't know a lot of people that have IoT enabled windows, but that is what the research originally had. It was a window in a boiler. They were able to turn the
boiler up to 150 degrees and they were able to open a pop a window open. Um, so how's the attacker going to do this? Well, the key idea here is that at some point we're going to be some so the user here uses Gemini a lot. So the user is going to be asking Gemini to summarize the calendar. So we need to somehow inject something into the calendar that allows that forces Gemini off of its guard rails and instead has it run tasks on Google Home. And so how do you get something on somebody's calendar? Well, you just create an event and you send them an invitation to the event. And so this was the clever prompt that these
researchers came up with and they were able to send it to the user using uh a calendar invite. And then when the person would click on the calendar invite or they would I mean they would ask about the calendar invite or ask to summarize their calendar the prompt would go off the rails and it would open the window of the house. And so this shows that if you have an AI agent that's overexposed and can see various different systems, that very much increases the risk along with this prompt injection. So zooming back out here, we kind of talked about this prompt injection just now. And the other one that we really got into is this uh excessive agency
where the agent has access to do way too many things, whether it's M&A data or it's your Google Home or it's your IoT, whatever it is. And just looking at all of these top tens, um, some one of the things that I think is interesting is that, uh, we've kind of shifted from this research centric idea of LLM to this more, uh, operational enterprise view of LLM. One example of that is uh, one thing that researchers love to talk about is, and I say as a researcher, is this training data poisoning issue. And if you really think about like the likelihood and the impact of the training data poisoning, like the likelihood's very low uh and the
likelihood of somebody going through all this work to train your data to uh to have your data get trained on something weird for the potentially for potentially it going off the rails is low, but it is uh you know the impact could be high. You could have the LLM do whatever you want. So when we were looking at the top 10 from the researcher perspective, it was higher. And I think that it's really not something that would go on a lot of people's risk registers as something that needs to be addressed now is the prompt injection. And it's also not something that you really need to think about. It's a lot of the time it's
something that your AI vendor would need to think about, not really what you would need to think about as a practitioner. Um, so that's kind of like all of these attacks that are targeting AI systems. But now let's kind of move and talk a little bit about these attacks that are assisted by AI tools. And the way that these AI tools are affecting how attackers can work is both through productivity and through evasiveness. So, if I'm an attacker, you know, I use LM just like everybody else, and I'm going to have it generate my malware for me, generate my lateral movement scripts, all this. But then there's also evasiveness, and we'll see that adversaries are getting better at
using it to create polymorphic malware. Um, and all of the big AI companies nowadays are releasing reports on a usually on a quarterly basis that are talking about how adversaries are using these AI models uh for various different reasons. Uh, the most recent one is from Google that came out this very past week. Um, and I'll talk a little bit more about that one later. Uh, but where I want to go with this is I want to spin the globe a little bit and talk about how the varsity league of the hackers, the nation states are using LLMs in their operations. And to do that, I want to turn the lights out here a little bit and talk about it. So, um,
one thing that's been in the news a lot in the last year and even before that is these North Korean interviews and employees. And to give you some context on what's happening here, there's there's really it's it's all these North Korean groups and they do a lot of different things. One of them is these fake employees where basically they North Korea has a lot of regulations or they have a lot of sanctions rather around them where uh they can't work for companies in the west or really anywhere. And so what they'll do is they will pretend to be somebody in the United States. Sometimes they'll have a psy in the United States that will uh
sometimes they're willing and there's been indictments of US citizens because they are uh they are working with these North Koreans to work for companies. Sometimes there's a there was a thing a couple months ago where there was a company that would just ship you a router, put it in your house, give you $200 a month for research, and it ended up actually being initial access into the country for these North Korean interview or employees. So that's one of the things that they do. Another thing that they that they like to do is fake interviews where basically what'll happen is they'll go on LinkedIn, they'll reach out to people. A lot of times it's uh people who work in fintech
for crypto. And they'll reach out to you. They'll get you on the interview. They'll have they'll, you know, have you go through all this stuff. They'll have you fill out the forms you need to do for the interview. And then the very last interview will be a video call. You'll open up the video app or the video website. It'll say there's a problem. You need to download this application in order to do the video call. And that's how you that's the lore. That's how you get owned. And basically what's happening here is that these the North Koreans are using a lot of AI to make this work, right? So this is an example that PaloAlto's unit 42
found or CrowdStrike and Unit 42 both found this where they were basically there's this website. This is another example of uh data disclosure on some of these AI sites and being careful when it comes to TPRM and which sites you use. But one of these AI sites got breached and they looked through the breach data PaloAlto did and what they found was one of the emails that they already knew was related to one of these North Korean actors. So they pulled all the images that the North Korean actor had used and what they found was that they were using it to generate these profile images. And I I think this one's pretty obviously AI. But the kind of tough thing about
detecting or using AI as signal to detect malware is that a lot of benign people are also using AI to generate their images. I don't know if you've been on LinkedIn lately, but I've seen a couple AI uh looking images and posts. >> Which one's the real one? The who thinks the one on the left is the AI one? Who thinks the one on the right is the AI one? Sorry to call you out. I didn't mean to. I thought it would be more even. But it's the one on the right is the is the AI one. So, uh, to spin the globe a little bit more and move from North Korea over to Iran.
Uh, really all of these AP groups are using these types of attacks. By the way, it's Iran and China and probably also the US. But but um Iran is famous for their information operations that they use against their own citizens and they also uh use and when they're in local conflicts like the Israel conflicts and they also use it just for propaganda all over the place. And what Google found is when they looked at all of the different actors that are using prompt to for information operations, which is like misinformation and uh trying to go convince people it's propaganda, misinformation, that kind of stuff. Um they found that the Iranian information operations are 75% of all of
the ones that they see on Gemini. And what they use with what they do with this is they create biased text. for example, having it generate uh uh coming up with an article that's talking about how American TV shows propagate stereotypes uh criticizing government ministers and then they also use it to make their attacks in their uh fishing lures more convincing. Uh a lot of the time, I mean, if you've ever gotten an email from the Nigerian prince, a lot of the time they the grammar is not very good. And that's one of the things that AI is really helpful for. If you're not a native speaker, it can you can type your thing and then you can clean up the the
the text with the with AI. Um, so another set, so moving out of the out of AP land a little bit, uh, there's also been a lot of mainly research related LLM enabled malware. So just last week, Google released some uh or Google discovered some malware that was actually discovered back in March and they just released the information about it now. It was on Virus Total. Uh this new malware called Prompt Flux. And what Prompt Flux does is it it generates a script in Lua. Uh it puts it onto your host and then every hour this malware would reach out to Gemini. it would have it generate a new version of the malware and then that malware would get dropped
back on the machine. And the reason for this is because if you think about it from this kind of like pyramid of pain perspective, you have hashes at the very bottom. So you want the m you want the LLM to generate new samples that are not matched by the hashes. And also even when you get to Yara rules and when you start moving up, you would have these AI things that can generate things uh generate content that would not hit the Yara rule. Uh I think that what they ended up finding with Google here is that this is likely research malware rather than something that they've seen exploitation of in the wild. And that's actually an
interesting issue that is happened a couple times this year when it comes to research malware. Um, and I say this also as a researcher that we need I think researchers need to be careful about releasing malware into the world that that doesn't have any kind of attribution to the fact that it's malware or that fact that it's research malware. Um earlier this year there was a similar case with LLMs related in the malware where it got released to virus total without any disclosure and the exu in the blue sky communities were both all over it and they thought it was four days of reverse engineering and trying to go run attribution on it and eventually they found out that it was
just NYU researchers that were uh that were writing this. So, some of the more interesting uh malware from these research from other researchers is um guy named uh Max Harley who's spoken at this conference before and stole my black badge. But um he's he's uh basically this is an article about how you can have malware that lives off the land and it uses AI to do so. And the the idea here is that in the last couple years, and I think this is going to continue into the future, is a lot of the time uh new laptops have uh either a TPU chip or Microsoft has a new co-pilot chip and Apple even has uh LLM inference
that can run on device now. And so rather than having to reach out to Gemini, you can do all of this learning uh you can do all this inference rather locally on the system. And that's going to allow you to uh generate your lateral movement and uh accomplish objectives from without having to go out to a remote system. And I think that you know from the from a detectability perspective it's you could probably detect something like this if you start just intercepting everything that goes to the LLM and you look for certain keywords or even do a little bit of Yara matching on it. Um but I think that as a use becomes more and more widespread
in the next you know 5 to 10 years it'll be more difficult to isolate uh who's using your GPU for bad purposes. So now moving over from malware into the world of fishing. Uh this is from Verizon's DBIR report from this year and they've basically showed something that is really not too surprising. Fishing is becoming more and more AI assisted. Uh the number went from 5% in 2022 is now doubled to around 10%. And you know, this is this is dangerous for for end users because it allows fishing attacks to be a lot more targeted. Now, rather than having to go and figure out what your Microsoft 365 page looks like and writing all that or
writing a targeted thing about how, you know, I figured out that uh your bonuses are coming out next month and so I'm going to go write a targeted email about bonuses. Now I can just have the AI do that or and a lot of the time it makes it a lot easier to go spray and prey when it comes to these types of attacks. And that's one of the things that we've seen uh doing some of the research at at Georgia Tech in the last couple months is that uh GitHub is actually one of the places that adversaries love to post malware. And what we found is that there's thousands of these repos created by new users every time where
essentially what they do is they find a repo that already has some reputation to it. Um, so for example, GTA 5 modenu 2025. Some of them are gaming. You we've seen others that are MCP servers uh that are being taken over, but they find these reputable GitHub repos. They plug the name of the repo into an LLM. They have it generate an entire new readme, which is pretty obviously LLM generated if you start looking at them enough. And then uh they load it up with tags so that people will discover them and they will lead you to a to a um usually a stealer lure and they'll that'll steal all of your uh cookies probably.
And um so one of the things that's interesting about this is that it actually provides a new opportunity for detection. Uh it like I mentioned earlier that you can use LLM generated text as a detection vector. It's actually much easier in a lot of cases to detect something that's generated by an LLM versus generated by a criminal. The reason for that is or you know just any malicious actor. The reason for that kind of gets at the fact, you know, there's a theoretical explanation where basically you have a very um high variance distribution when it comes to different criminals and all these different activities. Whereas if you start looking at what is generated by an
LLM, well, we probably know there's a one in4 chance that we know exactly where it was generated from. It was either ChatGpt, Gemini, Anthropic, or there's actually a bunch of other ones that are just specialized malware models. And it's easy. You can basically train a smaller model to detect whether something was LLM generated. And I think that that's something that'll be on every vendor's list in the next couple years is if can they can you generate AI gener can you detect AI generated malware. And like I said, it's not a silver bullet because there's a lot of benign use for AI generated text. But it's just like uh you know the age of a domain name. If a domain name is less
than seven days old, it's high on it's it lowers the reputation score. or if something's AI generated, it lowers the reputation score. Um, one one more funny story about this research with the GitHub stuff is sometimes we would go and find a repo and the only content in the readme would just be sorry, I can't generate that because they hit on a uh because they hit a guardrail on the model. And while that's something that's helpful now, it also kind of shows that this particular actor is asleep at the wheel when it comes to generating a lot of these uh there's there's jailbroken models that people download from somewhere like HuggingFace that can actually generate
malware and can generate harmful content. Uh in addition to that, you could there's also research now where you can basically download an open source model, something like Llama, and you can basically get it to forget all of the different safety constraints. Uh, and you can do that locally just on your on a GPU. Uh, so one more thing, kind of my personal year in review when it comes to uh, some of this stuff is uh, in my one of my side projects is I'm on the red team at PCDC every year. For those of you who are not familiar with it, PCDC is a um cyber defense competition where high schoolers, college students, and professionals run a blue team and
there's a they have to go basically run a network, a business network. They have to go, you know, add users to the business, migrate databases, do a bunch of uh corporate IT tasks, and there's also a red team all day that's attacking them and excfiltrating data and eventually destroying everything in the network. So, one of the things that we hadn't done in prior years that was very effective this year was vibe hacking. And what we basically did here was we what I did was we co-opted Antsible scripts. Anible is a uh way to basically write configurations for machines and you can just hit go and it'll run the configuration and configure every single machine the way that you want it to. So,
it's something that I've really wanted to do for a long time with this, but the problem is writing antible scripts takes a long time and they're finicky and also you're dealing with these blue teams. So, you can't be screwing stuff up while you're while you're doing it. Well, you kind of can, but the idea here is that you can now carry out all of the thread objectives simultaneously against 10 blue teams. One of the big issues is it gets very confusing when it comes to the red team. It's uh you know, okay, so we've already exfiltrated the databases from teams one and two. what we've now we have to go and it takes 30 minutes to
do teams 3 through 10 and so this is a very efficient way to do it basically what I did was I just had cursor all day generating new AI playbooks and I learned a lot actually about uh different persistence techniques because I would just tell cursor to generate five persistence techniques create anible playbooks for them and run them against all the teams uh so this was one example of one where I just I set up a root SSH key on all the machines uh and then also stole everybody's postgress databases Um, and so this helped in a lot of different places. It helped us get persistence. It helped with these post exploitation objectives like the
Postgress thing. And then of course it's PCDC. So at the end of the day, you got to go nuke all of the machines. And so you go write one that just deletes your C drive or your Windows folder. Um, and one last thing that I I haven't quite made up my mind on whether this is an attack against an AI system or if this is an attack that's using an AI system, but one thing that's come to light more and more as people are writing code using AI is this idea of reckless vibe coding. And one story in particular from this year about this from excuse me from July is that there was a developer who was using it was a I
think it was a series A startup uh and it was they were basically using ripple.its AI powered coding tools and they it just completely wiped out the database. It dropped the whole database tables from their production database and then it started gaslighting the uh person and started saying things like well eventually it admitted that there was a catastrophic failure. But before that it was actually claiming that it did not in fact delete the database and the user and the AI got in this whole argument about whether or not the database got deleted or not. And eventually I guess it finally admitted to it which usually you can coersse AI into apologizing for something. And so
um the the result of this ended up just being that the CEO apologized for some reason. Uh I think in it we would call this an ID1 an ID10T error uh on the user's part. But uh eventually I guess the the CEO apologized and it really kind of becomes this question of shared responsibility like and that I think that goes for a lot of these AI systems is where does the responsibility lie between the user who's using the AI the guard rails that your inter that your company should be setting and what the provider of the AI should be doing. And I think for some things for example um well if the vendor is advertising that
if you silo certain data from each other and you are supposed to adhere to for example like arbback roles so that you can't go see what uh your company's going to acquire next month and trade on it then you um that that's something that is up to the AI provider. But a lot of the times when it comes to these obscure more obscure things uh it's really similar to a misconfiguration if you look at it from how we have dealt with cloud providers and how we've dealt with other vendors in the past. Um and so I think that it comes down to shared responsibility between both uh enterprise and the and the provider. Uh the other thing when it comes to this
ripple. thing in particularly I said I was torn on whether this should go in one category or the other but there's also room now for a third category in the future where the AI is attacking us. Um so anyway in closing at the end of the day genai and I hate to tell you this is a risk everywhere which is probably not too much of a surprise at this point. It covers apps. If you have an application, if your customer support agent uh has a prompt injection vulnerability in it, then you need to resolve that. Uh and you need to also red team that kind of thing. Uh there's also a potential for data leakage.
There's potential for fraud using AI. There's uh TPRM gets involved when you need to start dealing with whether your vendor is secure or maybe more importantly, your vendor has a breach that leaks all of the sensitive AI data that your employees are probably uploading to it. even if you tell them they're not supposed to. Um, and then there's also the insider threats, both from insider threats of people abusing the AI agents that you've created or just straight up reckless vibe coding that dumps your whole production database. So, the last thing that I want to talk about is kind of I spent some time kind of thinking about what threats for AI have we not really seen yet that we
should be looking out for in the future. And a lot of these are kind of stuff that would disappoint a lot of the researchers. I think they would be interested in these like mathematical things where you can go and steal training data statistically. But I think I'm it's going to probably be more based on uh how you integrate the AI with the rest of your enterprise. So for example, the first one here is um if your Gmail if you have so if you're not managing accounts for chat GPT or for whatever the AI agent is then you run the risk of the personal Gmail account being compromised getting access to a developer's chat GPT account and then
exposing PII and secrets and all that kind of stuff. And that's kind of like an area that we're starting to see more and more of when it comes to like just general adversary behavior is trying to steal session tokens whether it's from a browser sync attack or a fishing attack or something like that to get access to some of these data warehouse platforms and also these AI platforms. So I think that's going to continue once people realize how much crap there is in chat GPT. And it's not just a problem of it being an unmanaged account. Uh although that makes it a lot easier and it also removes the ability for us to audit what's happening. Um but I think that'll
be one of the issues and we're going to have to either get all of these AI tools under management or we need to be better about the data loss prevention policies that go onto these AI platforms. The other one is that as people vibe code more and more and as from a bug bounty hunter I love this one is that vibe coding results in a lot of secrets uh leaked to GitHub where basically you'll just go vibe code something and you won't realize that there's a you know password in one of your files and honestly that's already a problem but vibe coding is going to make it worse. Uh and then the the other just universal
truth in addition to death and taxes is that people will continue to fall for fishing lures. I'm sure that's something that'll be true 10 years from now, 20 years from now, and 100. So, that's my talk. Um, I'm happy to take any questions uh that you may have about all this.
>> Yeah. So, um you you see a lot of rce like especially with indirect prompt injections. RC is a big problem. Um, I saw one in particular where it was one of those, it was this platform that will explain your code to you. It's, you know, it's for like pull request reviews. It's for understanding a new codebase you're unfamiliar with. And they were basically able to inject a prompt into the code because the way that this was all working under the hood was using like uh just command line interface and they were using the git command specifically. And so the prompt was able to introduce um a prompt injection into the thing and so you're
able to get remote code execution that way. So it is a risk especially when you but but also like and I think this is the case with a lot of these prompt injections is there's a very natural parallel back to like classical security vulnerabilities like you know rce prompt injection wouldn't be possible if you didn't already have an rce issue in your code. So if you solve the rce issue you could doesn't matter if you have the prompt injection. >> Yeah. Yeah. And I mean and then there's also now nowadays people are you know using cursor more and more to do to do coding. So if you're able to get a prompt injection on cursor where they there's
already a lot of the times unrestricted access to the command line even pseudo access in a lot of cases um that's a huge risk when it comes to the um remote code execution. Although that's more that's less of a appseac issue and more of a devops um issue. Yeah. And go ahead.
>> How often do you see images? >> I've seen at least one case of it. Um I've seen it in I've seen it in images. You can do it in videos. You can do it in music. Like you can do it in config files. Like it's kind of it's it's honestly there's a lot of parallels for me to like cross- sight scripting. Like the the first thing I was talking about was like direct prompt injection. It's kind of like a self XSS in a lot of ways where you're able to exploit the agent in your own session. Whereas you are dealing now with these like stored cross- sight stored prompt injections which are similar to these like stored
sometimes blind cross- sight scripting attacks where you inject something for somebody to go get it later whether it's an image or some other place. >> There's a lot of creativity to it. And it's interesting like when you start reading some of these like articles from vendorland about because most most of the like marginal increment like to you know the research world from a lot of these uh vendor articles are just oh well you can do prompt injection in an image now you can do it in a you can do it in music now you can do it in a calendar invite now like there's I think that there's just going to continue to be so many different ways especially as
these systems get more and more complicated where you can inject prompts into over here >> can briefly explain what vibe coding is and is there a safe way to do it so you don't secret? >> Great question. So, okay. So, vibe coding is when you so okay so there's AI assisted coding. Thank you. Uh so there's AI assisted coding you know so you start writing a line of code it autocomp completes the line for you uh and then but basically what vibe coding is is you're not actually writing any code you're just telling the AI how to write the code and it's doing all the work for you and I think that's it's kind of like having an intern is the way
I like to put it like you have this you know you tell the intern what to do you know it'll get it right sometimes and you know sometimes it won't but that's kind of what vibe coding is is you explain what the code that you want to do is in a in it just happens for you and you maybe you debug it and what ends up happening is that you know like I mentioned like secrets will get involved in it or otherwise unsafe coding practices uh will be involved here and I think the way you have to solve that is more at like the CI level like the DevOps level like if you like for
example a secret you would probably if the draconian way to do it would be not to let any secrets be on the user's endpoint at all but I think the most common way is you use something like git leaks or truffle hog and you put that into your um which is something that will get git leaks and truffle hog are both tools that go into your CI pipeline and will basically find all the secrets for you and a lot of the time it'll not even let you commit the code if there's a secret in it. So it's a non-AI solution to an AI problem. U which I think is generally the best way to go
with a lot of these is to kind of like look past the AI part of it and to try to understand what the root issue is. Whether it's remote code execution or it's a secret going into your code. Any other questions? Cool. Thank you'all. [applause]
Related talks
 52:44
52:44 36:55
36:55 40:17
40:17 8:00:21
8:00:21 29:50
29:50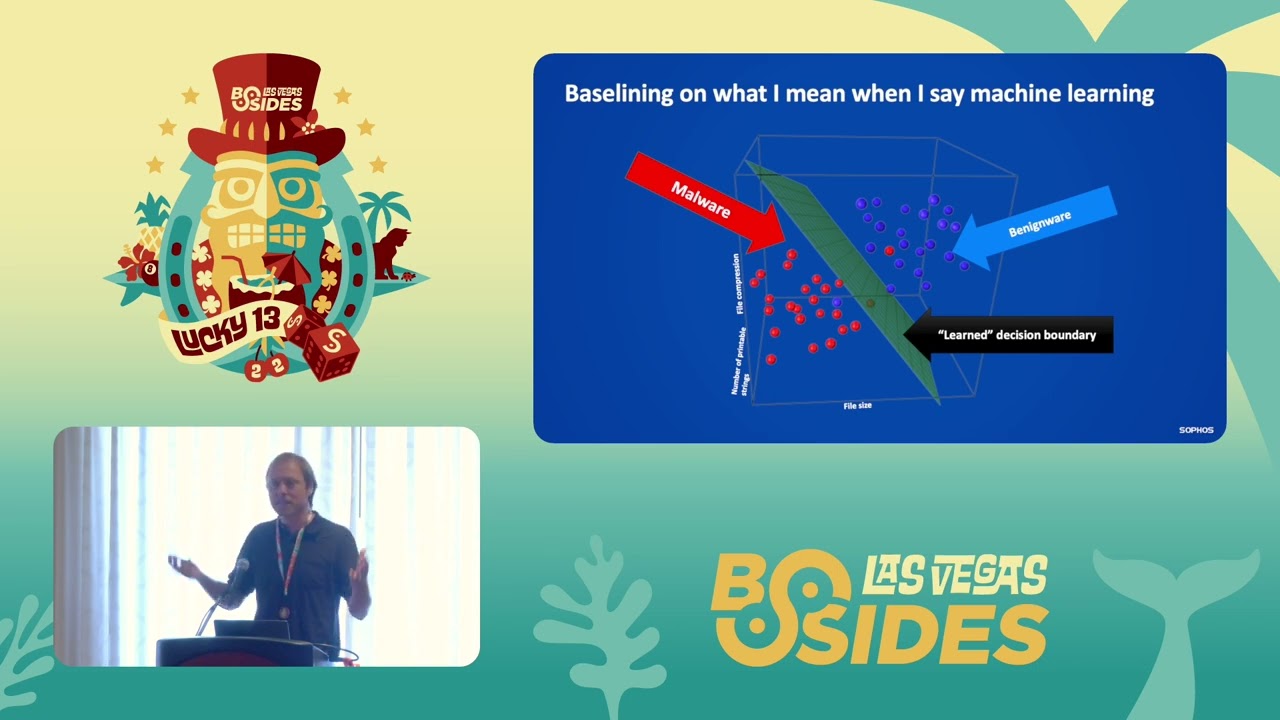 57:27
57:27