Navigating the Vast Ocean of Browser Fingerprints
Show original YouTube description
Show transcript [en]
[Music]
good afternoon everyone welcome to the last session of b-side San Francisco 2018 I'm honored to be here in front of you and it's pretty exciting talk first of all theater setting pretty awesome settings out the lounge chairs pretty good I presented at besides this will be my fourth third or fourth presentation some of you may have seen previous ones they've all been non-technical non-security talks my first technical security talk my version of impostor syndrome is I never know enough and I'm always behind you may see evidence of both of those today and I'm fine with that there may be people here who are much more expert on many of the topics I touch on today and if you want to bring
that up in the Q&A I'm fine with that I just want to put that out there that I'm here in front of you with my first technical talk that I didn't think was technical enough to be accepted at b-sides and I'm excited about it I put my best work effort into it and I look forward to having a good session with you so the topic here is browser fingerprinting before I go further disclaimer so I'm a data scientist at a financial institution nothing I say here represents my employer what they may or may not be doing their positions on this topic this presentation is solely about method things I've learned along the way things I think can be beneficial to you
now another disclaimer here this is a blue team talk some of you may be red team some of you may be going back and forth when it comes to browser fingerprinting you may know ways of obfuscating spoofing otherwise messing with anybody trying to capture browser fingerprinting I'm not here to debate that I don't explore that there may be other talks or other sessions where that's covered so from a blue team perspective what I'm interested in is how can we make use of browser fingerprint information for some use cases that are not usually discussed okay so I'm not going to assume that anybody here knows anything about browser fingerprinting or the methods that I go through so it's going to be
pretty tutorial along the way those of you who are experts bare with me so when you hear the term browser fingerprint think of all the information about a browser and here browser means any device that engages in an HTTP transaction any information that is discoverable from the server side about that client so some of it comes across in the HTTP header user agent string accepted language some other stuff a lot more stuff and a lot more revealing stuff is available through JavaScript and other mechanisms that inquire into the user agent screen size browser window size browser plug-ins fonts set session ID information html5 canvas and there's even ways of timing what the client is doing that can be sometimes
folded into fingerprints as far as I know there is no standard definition of the entirety of what can be in a fingerprint I believe from the literature I've seen the different people sort of focus in or limit the feature set to some things or other things but it's a potentially a very long list open to creative interpretations now one of the key things about browser fingerprinting how can this qualify as a fingerprint well each one of these pieces of information carries information about how unique or conversely how generic a given browser is and one way of measuring this using information theory is the measuring the entropy in bits so if all the browser's in the universe have one of two values
for any given variable then that would qualify as one bit of entropy okay so the higher number of bits of entropy the more information you get about a particular value so plugins and fonts here on this list provide the most information whether cookies are enabled or not provides the least information in general browser fingerprinting combines information across all of these so the challenge of fingerprinting if you're going to do anything with it is how do we combine all these different signals into a common signal we can do something with so the most eye-opening academic work has to do with the html5 canvas below here I don't know if you can read it I've got some text from the article
the thing that jumped out is you write to the html5 canvas you read it back and you hash the result and this makes dealing with the canvas fingerprints almost as easy as dealing with cookies from the server-side okay and this academic article says that this is 18 bits of information and you can see that tops any of the other versions of it I believe I don't know but I believe some approaches to fingerprinting only deal with things like the the html5 canvas where you can aim to get one signature to uniquely identify okay if if you've never had your browser fingerprinting you can go to this site this is a service offered by Electronic Frontier Foundation and
click the button that says test me and it will give you a readout of your fingerprint and how distinguishable your browser is from every other browser that they've seen so they've accumulated a database that they've applied this to and I think this is an informative thing I meant they have some screen captures here if any of you use the tor browser you can go visit web sites and the tor browser will give you a pop-up warning if that particular website is trying to fingerprint you so I went to a couple the popular sites go to the Facebook homepage even before you complete the login process yes there you're being fingerprinted you go to the Google
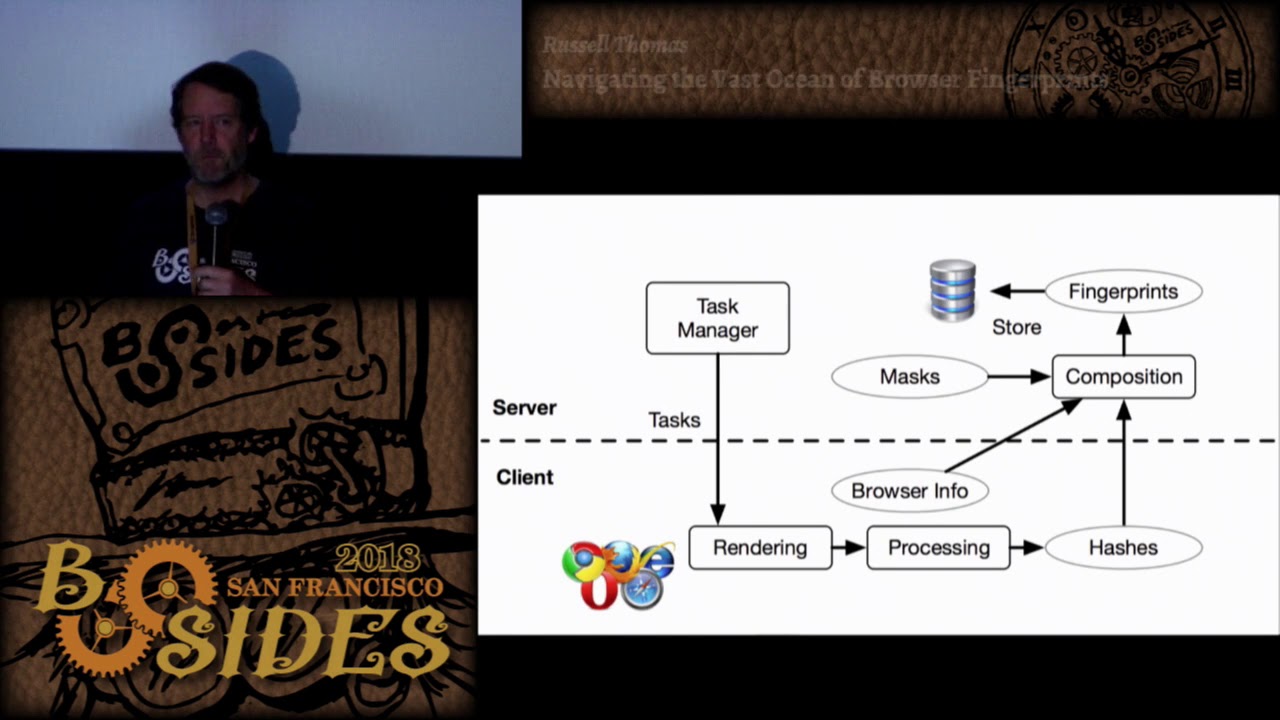
homepage search box no you're not being fingerprinted I have no judgment about that choice what it means what they're doing with it it's just interesting to know okay so now let's talk about the goal of this exercise for the purposes of this talk for people who are in blue teams the most famous infamous well-publicized use of browser fingerprinting is to associate a particular session activity with a particular device for validation fraud prevention surveillance lots of other things I pulled this block diagram it may give you an idea somewhat of what's going on on the client and the server side the key thing here is if you look at the line from that circle that says
fingerprints in the database they're not really doing much more than capturing fingerprints and storing them away and they're gonna look them up later to see have we seen this fingerprint before right now if this is associated with a login activity you might say I'm seeing a fingerprint associated with this login does that match any the fingerprints I've seen before with this account right so it might be part of some access authorization process but this does not get at the core use case that was driving our need so what we needed was general-purpose fingerprinting where we could do all the fingerprinting ahead of time and then answer questions related to fraud detection prevention response maybe even marketing type applications
where we would want to know are we seeing any browsers roughly like the browser's we're seeing here anytime in the past so the key question is we need a space of browser fingerprints with some kind of distance metric that we can use in our models it says give me only the browsers that are somewhat close to this or give me the browser show me all the browser signatures or fingerprints that are close over the last two or three or five years because I may want to track the trajectory of given users as they upgrade their system now a key thing many of you know this but as you use your system is you upgrade your
software you will acquire different signatures your user agent string will change somewhat a little bit or on major revisions maybe a lot you're going to be acquiring fonts you may be shedding fonts if you do it on purpose likewise with with plugins so even for an existing user for an existing device if I have an existing device a lot of the things that I'm that fall into this fingerprint category are not actually fixed and so you want to understand how they might change over time let me say one other thing so this became important in the context of fraud investigation because the question arose is in the fraudulent activity are we seeing use of toolkits
that are being used in other places is there a connection between recon activity and actual exploit activity so really trying to get a much broader sense of over the life cycle of exploitation maybe as multiple threat actors might be involved who might share common tools can we see commonality among them so as far as I can tell and having read the literature could not find any tool or method to solve that problem which is why we went down this path so my job day job is a data scientist and I told my boss it's a challenging problem and it requires real data science thinking he was excited to hear that rather than just some hive
queries and whatnot that we usually do so quick show of hands how many people are considered themselves data scientists how many people actually have done machine learning and Cagle contests or anything else feel comfortable knowing about machine learning so the folks who raised their hands for everybody else I'm going to share something with you this aspect of machine learning our data science is about feature engineering it's about what goes into the models and what I'm talking about today I'm not going to be talking about machine learning modeling training hyper parameter tuning all that stuff this is all the thinking that goes up in front of it now one of the big trends recently it's associated with this word called
deep learning is we're not as data scientists going to think about what we feed into it we're gonna feed in whatever we can find and we're gonna have the algorithm sort out what the features are now if you some of you may be aware that Google Translate went through a big generational change three four years ago so prior to that they had a bunch of machine learning models that had built into them things that were trying to recognize parts of speech and other grammatical concepts and they shifted to technology related to what's called word to vac which is word to vector this is a deep learning technique which says no we're not going to provide any of that information at
all the algorithm is going to figure that out we're gonna throw tons of data at it and the algorithm is going to figure it out so it may be tempting in fact I'm going to show you some preliminary work here today where you treat this is the same the approach I'm recommending takes a different angle so hopefully that makes some difference so in fact I want to contrast three different approaches you might take most of us in the room who have familiarity with UNIX tools we have familiarity with tools that evaluate text files and how different or similar they are and highlight the changes the first method is really closely tied to that this string at a distance so if you took the
fingerprint you just concatenate it all together call that a string and then did edit distance maybe that helps solve the problem second method similarly you're creating giant strings out of these the structured data but you're going to apply some deep learning methods in fact the word Tyvek method see what happens there so the third method does not take that approach says we're going to keep this structured information structured we're going to apply domain knowledge in the encoding and then once we're done with the encoding we're going to concatenate the results now watch at the end of this presentation which you're all walking out thinking the words muttering the words to yourself sparse distributed representations sparse distributed
representations is Alex Pinto in the house by any chance okay so some of you may know Alex Pinto is one of the more well-known well-regarded machine learning information security guys his company just got acquired by somebody so he's in a good place little is known about the underlying technology I have reason to believe that steampunk deep learning is the core of his technology but I can't verify this photo so the deep learning method again you're offloading to the algorithm the the task of feature izing making sense of this and conceptually that approach is valid because if you have a Hadoop store and you have all your HTTP traffic over years and years you've got no
shortage of data so maybe this approach works so the sparse distributed representation I'm going to talk about the benefits first because I spent a lot of my career in management and marketing and then I'm going to talk about the technical part and close off a little bit of implementation a little bit of results so the key thing about sparse distributed representations as opposed to condense representations right if you have five different browser types you might have a code that densely in a bit string of three or four bits and every category has a unique bit string sparse distributed representations spread that out out over fifty or a hundred bits and the advantage of it is it's much
easier to combine features with different domains and granularity you can do relative air easy partial matching fuzzy matching boolean operations even fuzzy boolean operations without descending into regex so not germane to this application but sparse distributed representations are very robust to noise erroneous and missing data a couple of other things sub bullets here I have listed that apply if you're plugging this into a machine learning model but everything I'm going to talk about today is what you do that short of that and if you don't use machine learning at all and the key thing for me here is the last major bullet is you can do this manually meaning I as a programmer I've taken
there's a company called Numenta based here in Mountain View they have a system called hierarchical temporal memory their front end to this our sparse distributed representation encoders so I've taken their encoders and applied them to this exercise and it didn't require any fancy expertise from from anybody so that was a real advantage the other big advantage for me was if you use method number two you have to keep retraining your encoder all the time you may put five years of data into it but you're going to have to keep retraining that month after month is new fingerprints show up because whatever encoding whatever vector space that is been created will be and not necessarily gracefully
so the method I'm describing you do have to keep upgrading it as new signatures come in but it's not a machine learning retraining exercise so it has dramatically different consequences on the resources and the skill set you need to do it okay now we're getting down to brass tacks what the hell is a sparse distributed representation I'm going to walk you through step by step so you can understand the basic concepts and after you understand this slide you'll be understand I hope a wide range of encodings that follow the same patterns okay so the inputs here are a series of integers these could also be floating-point numbers but the point is they're just scalar numbers the output
when you specify the encoder you specify the total number of bits that you're going to encode the number of on bits within that total set and the encoding is where in that total set you put those on bits okay so by convention in the first element is encoded in the first this case ten bits the second element here is encoded in just shifting everything over to the right one and so on now the important thing for sparse distributed and coatings are is the overlap because the overlap determines either a full match or a partial match or any other sense of how close or distance these things are so in the blue area so you can these are
all of the encoding that have at least one bit matching the first one zero so the key idea in sparse distributive representations is your encoding your distance metric and your encoding your rules for capabilities for partial matching in the encoding itself which really takes a lot of work off of your logic and your systems that come later now another feature of it is you can feed the system the encoder it's able to decode or produce matches to bit strings that do not conform to the encoding structure so at the bottom here I have a bit string labeled F that has two on bits and if you perform a matching operation and you're counting any matches greater than zero this will
match all the inputs between 0 and 20 so in the same sparse distributed representation you could represent all the numbers between 0 and 11 any subset you choose and you also get a sense of how how distinct you want these to be if I'm looking for a 0 do I want to sometimes return to one if that's a fuzzy match now there's a couple key variations here one key feature of a sparse distributed representation is you can come up with what sorta called periodic encoding so think of days of the week sunday is just as close to Monday as Monday as to Tuesday and so on so even if you number the days of the week 1
through 7 you want to come up with a distance metric or similarity that that wraps around so the way you do that here is you simply shift the bits so the there's an overlap between the last element and the first element let's see one other item here so the other key building block here is how do you encode categories the way you encode categories is the same as here but you don't have any overlap or you have some predefined overlap if you want to have commonality between categories but let's say you have disjoint categories you simply use the same mechanism here you just define it so that there's no overlap between the bit strings and everything I'm
describing here and waving my hands around this happen happens in the code that sets up the encoder to the first place and once you run it you never have to revisit these things again it just works so there's two generic ways to store and manipulate these one is the binary array and for some purposes especially if you're feeding machine learning that's way to go for a lot of what I do I store it is integer lists of the ones therefore the size of my SDR is only it's the length of how many on bits that I have so I might have a thousand bits or a hundred thousand lists bits if I have a bunch of those that are empty
they don't take up any storage space and when I'm looking for overlap all I'm doing is matching integers do I have the value of eleven and both of them for example so these are kind of interesting when you look at them individually but they're really powerful and really useful for this application if you look at them together here I've got three different types maybe they have three different configuration parameters I can combine them into a composite encoder that takes a structured input the structured input basically Maps the first value in the structure to the scalar encoder the second value to the categorical encoder and the third into the periodic encoder and I can inquire that composite encoder for a similarity
or distance value just as I would the basic one so you get a richer distance metric without increased complexity in the programming interface and the semantics of it so here's an example handling version numbers I don't know if any of you have had experience trying to encode version numbers into a metric space but version number is it's 1.5.0 dot three and they've some of them have text thrown in unless you treat these as edit distances it immediately gets to be complex maybe you punt on all the differences and you just look at the major revisions but in a lot of cases you might find important signal in how often again instead of browsers move from move
through their minor revisions you might find some patterns there so I don't really want to throw that information away so the approach here is you build a composite encoder focus you basically parse the browser version number and you feed it into different types of encoders that handle each piece and then you composite them together so I want to share with you some results these are work in progress so this is preliminary I'll be posting the work as I go on a github site available for use the the encoder software I'm developing will be open source so you can use this if any of you work in a Hadoop environment you can use this the Python
software in your MapReduce code so it should be pretty usable so what I'm testing is I'm focusing on just the huge user agent string is my test case and doing these three different approaches and the sub-bullets here show the pipeline of work in case you haven't seen it here's a sample of the the browser strings I there's companies that do parsing of this and will feed you the parse results for this exercise I chose sort of my own little parser pulls out some key information agent the agent version operating system operating system version device if you look at some of these strings there's version numbers all over the place so it takes a fair bit of parsing skill
to figure out which version number you're going to pick up depending upon what some of the other parameters are so here's an example of that compositing that I was talking about before I have different types of encoders for different pieces of this okay so here's the kind of results I'm getting and the ways I'm evaluating it so as a data scientist it's the first thing I always do is I ball the results before I do any tests before I do any fancy stuff so here I am I created distance matrix so n by n distance matrix and then I run it through multi-dimensional scaling with three dimensions and then I visualize it so I'm looking for here is I don't know if
you can read the text at the bottom these are color coded Mac Android Linux Windows and other string at a distance not everything is clustered in the same place maybe that's good maybe that's bad I see a bunch of very tight clusters that could be significant now if I can bear that against the dock to vac approach that gives me much more diffuse clusters this could be more useful information if I'm trying to discern certain types of changes now I apologize advance I'm when I give presentations I don't tease the audience I meant to have this part done for this presentation was working yesterday and today to do that it's really work in progress so I'm
gonna have similar visualization for the SDR encoding and the key result the payoff is I want to track trajectories of actual individual user devices and the test case here is I should be able to show the SDR encoding does a better job of discerning evolution of single devices than the other two approaches here is a test case using a much smaller data set this company edgar provides a service for parsing browser strings excuse me user agent strings go to the website that i pulled the data from them but they've they've done all the hard work to figure out how to parse user agent strings but with just a hundred and fifteen data points rather than
looking at all the fuzzy clusters you start to see how scattered these things are in space and if you really care about fine grain distances it's not enough to have just everything threat show up in one blob and it's also not very comforting to have these things spread out all of the case where you may be losing information about their relationships so last thing I want to share with you since it's the last day of b-sides it's my nomination for the coolest creatures in InfoSec the capybara which is from Brazil I noticed the goats standing on the head over here that is a pretty cool creature and the monkeys that are doing the cleaning of it and I mentioned Alex
Pinto before Alex is also from Brazil so I often associate Alex and his personality with the capybara so here's your T key takeaway sparse distributed representations the key is they encode similarity similarity is not computed afterward you can derive it by different ways one key thing is really important you can do weighting and filtering if you have 20 or 40 or 80 encoders if you filter some of those out you're basically enhancing or removing some of those factors in your distance calculation and that's really the key to some the applications we're working on nothing I described here requires machine-learning doesn't even require data science background I'm going to be releasing the Python code and some of
the our code for visualization capybaras are cool so as Alex Pinto because they're from Brazil so the end of my presentation any questions comments I can't see everybody's hand
anything anyone all right so for my benefit cuz I maybe I'll see feedback forms later show of hands how many people were think what they heard today was surprisingly valuable okay how many people think today's talk was a waste of your time and you're only happy to be here because of the comfy chair alright I appreciate that so everybody else is in between that's cool all right so thank you all very much for your time I'm available afterwards for a few minutes I may even see up in the happy hour [Applause]
Related talks
 28:29
28:29 29:24
29:24 32:13
32:13 30:17
30:17 38:53
38:53 32:39
32:39