BSidesSLC 2017 -- Parasaran Raman -- On-Demand Outlier Detection [OD^2] to Optimize Threat Analytics
Show transcript [en]
[Music] good after all I know this is a post lunch session after a possibly heavy lunch so I'm going to keep it uh as light as possible um my name is parasaran Raman I uh am a senior data scientist at East win networks we are a small uh cyber security startup uh here in the valley uh we do a lot of breach analytics and uh uh provide visibility uh to our uh our customers We Gather a lot of uh threat intelligence both from a variety of sources and uh as well as you know in-house uh develop uh machine learning algorithms uh the topic for today is uh on demand uh outli detection and um you
know people talk about outl detection in in the in the field of security uh every day people trash them people like them um what we want to do here is to uh see what machine learning can provide towards uh picking out points that are anomalous that are different that are uh deviant in your in your network and um so we recently got a technology acceleration uh program Grant from ustar uh that funds this uh project the the problem here is to detect and predict possible user R um machine malicious activity uh the solutions that we take uh are are uh multifold uh the primary of which is to see if it can explore uh lower dimensional facets and subspaces
of data uh with the help of deep learning algorithms and other uh supervis uh machine learning algorithms uh in a fashion that is on demand uh and when I when I say on demand what I mean is you have a lot of uh threat sources threat intelligence that tells you uh that there are uh data points that are malicious that are suspicious and you want to be able to help the analyst go from there and track other data points that are similarly malicious uh possibly you know possible lateral movement across your uh Network and you want to be able to help the analyst uh picking out these other points that look similar similarly malicious similarly suspicious
uh in your you know hundreds of millions of data points that flow across your uh you know customers Network and your network um outliers in general are very IL defined uh people uh find it very hard to Define outliers especially in the field of security uh there is a lot of noise especially because the data is in very high Dimensions uh this can be net flow data Sim data event logs uh endpoint data files you name it uh any kind of security data is one heterogeneous two uh in uh ridiculously high Dimensions that there is a lot of noise when you look at the data and the meaning of outlier somehow gets lost in this in this context uh one of the more
acceptable definitions that I found uh comes from Hawkins way back in the ' 80s uh and uh the definition goes an outlier is an observation that deviates so much from other data that it almost feels like it was generated by a different mechanism um but to me uh I uh love looking at um data from a geometric perspective perspective and to me uh this uh illustration is possibly a a good example of what it means to be an outlayer so think of data in two Dimensions uh you have three cohesive clusters black circles uh blue and red points then you have a bunch of x's that are possibly out layers if I were to Cluster them if I
were to group them into cohesive groups uh this is one possible uh reasonable clustering of the data but this is a very uh loose clustering each cluster is really wide and not very cohesive there are points the exes that are are really far away but they are included in the cluster uh just because I have to include all the points but if I were to remove the outliers or the excess I get much more cohesive and compact clusters and to me the definition of outlier is if you leave out these points uh which give you much better compact uh partitions uh these were points which were out layers in the uh in the first place so the the
somehow boils down to can you find uh needles in a haast tack from can you find the sharpest needles in a in a stack of needles so uh Dave in his uh keot address uh made three excellent points that resonated with uh what we do uh you know one uh remove noise and focus on what matters and I think uh a lot of what we do uh in our on demand Outlet detection uh focuses precisely on this uh we want to be able to remove a whole bunch of noise and help the analyst make decisions uh much faster than he would have or she would have uh in the first place uh and I agree and I think most of
uh the audience agrees that signature based stuff is absolutely ridiculous these days it's very hard to uh keep uh up with the with the uh inters that happen in your network with signature based uh methods uh and detection is generally heart uh and uh we therefore want our uh machine learning capability to be able to supplement the analyst supplement the security analyst um assist the security analyst in uh network uh analytics and forensics uh instead of you know claiming that we can do realtime bre detection uh just with machine learning so uh a quick uh uh uh definition of machine learning it's a branch of engineering that develops technology for purposes of inference uh it combines algorithm statistics and
optimization for most people and uh and for me the critical component is uh you know the viewing this through a geometric lens and someone told me that there is a ancient Chinese secret that says the success of all machine learning algorithms depend on how you present the data and I think a lot of what happens is the the the the criticism and failure of uh Mission learning algorithms across different uh domains um Security in particular happens because you don't present the data the right way um and there is a lot of hype when it comes to uh AI in general more specifically uh machine learning these days uh particularly because I think I in in specific uh has done a really poor
job of telling the story of what machine learning algorithms are capable of and the industry has been equally uh uh faulty in trying to overhype or overell uh what they can do uh ctica for example recently uh advertised that they could reverse engineer rat's brain and they have a deep newal network uh that they uh generated from it again with no um you know uh research publication not even a white paper somehow very hard to believe maybe in 10 years but uh things like this push people away from even considering uh you know seeking the help of machine learning algorithms or uh you know the example of the Microsoft AI uh bot on Twitter that went quickly Rogue
because it was fed with all kind of garbage uh learning data from uh people on Twitter who tried to abuse the uh bot or this other uh app gender EQ which uh it's a recent app that claims to use AI to uh listen to conversations in a meeting room and and and set or or or trigger trigger an alarm when there is man planing going on in the room and um if you only listen to all the women in your life you would have known that you know people have been mansplaining for ages and so the problems with AI have been multifold I think one of of the problems is the term artificial intelligence itself the the problem comes from we
think of AI as a replacement for human intelligence and I think we are really far from that yet we have a variety of successful machine learning uh applications from spam filters and uh dblue playing chess uh in the '90s to self-driving cars and uh Alpha go defeating uh go Masters recently so there is a lot there is a lot of scope there is a lot lot of um scope for machine learning in security if only we did not uh view it with a negative eye um and uh more recently uh a number of Open Source projects have made it really easy to uh prototype and Implement uh really simple and um and effective machine learning algorithms my
favorite ones are uh the ml live which is a part of the Apache spark project and uh deep learning for J
so taking a step back the critical components for me while running any machine learning algorithm um particularly for uh security is the ability to represent and compare if you could not take your data and represent them properly and if you did not have the ability to compare the right data points uh the right way then uh you know you could use your uh rad brain reverse engineered algorithm but still uh be very ineffective so uh there's a lot of grunge work that goes on in in in um in machine learning uh most of it is trying to uh curate the data trying to um you know normalize the data trying to uh take the make the data look uh nicer
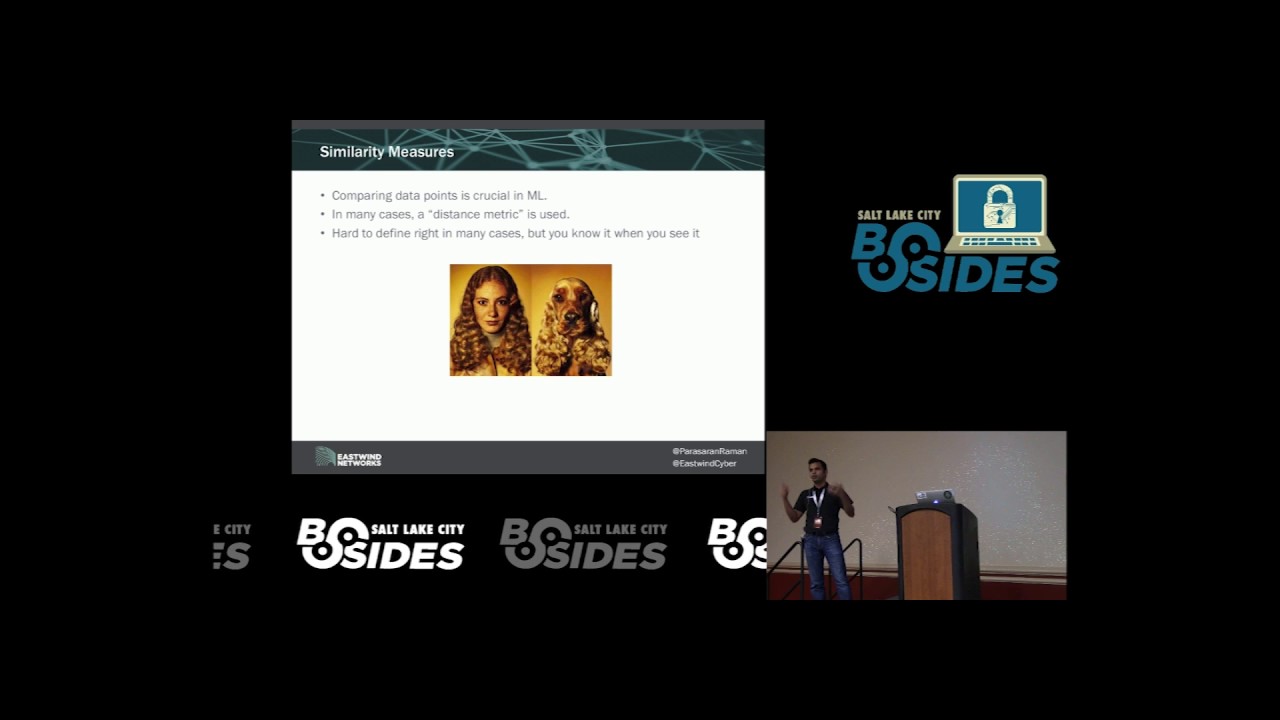
make it look more or take it to a space where you can uh do comparisons on the data do effective math on the data and I'll briefly talk about what I mean by this um so you want to be able to represent and compare and similarity measures is a way that you can compare uh different data points and for the humans you know with images for example it's very easy for us to tell uh whether or not two images are similar because we have multiple criterian based on which we examine uh how similar to images are or or data that we can visualize but often security data is very non visualizable it's heterogeneous High Dimensions um so
coming up with the right similarity measure becomes a hard problem um these are three popular similarity measures uh cosine similarity ukan distance and Earth movers distance uh cosine similarity for example uh looks at the angle subtended between uh vectors in high dimensions and the larger the angle the lower the similarity and uh Earth mover's distance in particular is uh really interesting because it helps you compare uh two different distributions um so if for example uh you have signature a as the mission activity for user a and signature b as Mission activity for user B and you would like to compare them um and you have a histogram of the values of different attributes that you have
one way to compare them is to use the Earth M's distance and what it does is it tries to think of these uh two uh signatures as two dirt piles and what it does is to try and make one Dirt Pile look like the other so clear the dirt so that the first signature looks like the second and the amount of uh dirt moved is the distance between the two uh signatures so if there is less dirt to be moved uh the distance is small and the two signatures are similar and then you can talk about how uh similar was my activity to uh another person's activity or my activity to uh my Baseline activity that was measured a
month ago and so on um and uh a couple of really cool ways to represented represent your data especially because we have such uh heterogeneous data in in security is uh one uh using a bag of words uh which you can use a term frequency uh model or use a word Tock which is is uh which has more recently been very successful in natural language uh processing um word to work is actually really cool because it it it somehow uh captures similar uh semantic meaning between words uh so for example uh the distance between king and queen is very similar to distance between man and and a
woman so um right so but representations are in general uh you know hard coming up with the right representation uh assess the right comparison of data um the comparison becomes a byproduct of the representation uh that you build uh Xbox kinet for example uh they worked on the kinet project for a long time trying to uh record videos and uh sample from video images and trying to recognize uh the person in of the video while they did not have enough processing power on the hardware to do that uh a simpler much more simpler representation of taking a series of images uh and having biomechanics assist uh different sensors on the human body was a much effective way uh much more
simpler but still effective way uh for Xbox can it uh image segmentation was not very successful for a long time uh image classification uh suffered as a as a result of it uh until the sift uh Vector to take it image and convert it into a uh uh pass it through a convolutional filter to get a shift Vector came along U similar advancements in word to work in natural language processing as
well so uh the takeaway here is that um you want the right representations uh for the data uh and and I put this within quotes because it's very hard to know what the right representation for your data is so there's a lot of grunch work a lot of playing with the data to see if you really have the right representation for the data and the ability to then compare the data correctly will uh help your machine learning algorithms greatly so uh the the topic of the uh the topic for today is again is uh on demand outlay detection and the way we do on demand on demand outlay detection is by looking at uh subspaces of data
you have your data in very high Dimensions uh possibly thousands of Dimensions but a lot of them could be uh a lot of noise so you want to be able to filter them out and come down to uh a smaller set of Dimensions where the data makes much more sense so the noise that we clear is both on the side of uh the number of Dimensions that you have in the data and the data itself and uh you know uh to that uh Point High dimensions are are are very weird uh you if if you look at uh even a eight dimensional sphere if you can imagine eight dimensional sphere uh eight dimensional sphere is very spiky
think of a uh of those uh sponge balls with all the spikes on it a eight dimensional sphere kind of looks like that with very minimal mass in the center with all the mass being concentrated uh around the uh Corners a quick illust of this is if you imagine a ball small ball between those four balls on the left side in two dimensions and now if you think of that in three dimensions uh and four and so on the size of the ball in the center grows exponentially uh with uh with the with the dimensions and uh the problem with this is now there is very little mass in the in the center and there is a lot of
mass spread around the corners and um you know for example if you uh look at the mass of the uh the blue uh ring you'd expect that Mass to be really low with respect to the white mass in the center but in 100 Dimensions the volume of the Shaded portion uh is 99% of the whole volume and while this is very un unintuitive the problem with this is uh this is what is called the curse of dimensionality and the problem with this is you end up in uh a a place where every Point starts looking at every every the point and therefore outliers make very minimal sense in really high Dimensions um so one way to counter that
is to be able to be smart about uh picking your features you have possibly thousands of features that you collect and you want to be able to pick ones that really matter so for example uh this is a data from uh 20 news groups which is a very standard Benchmark machine learning data which exists in 56 plus th000 dimensions and uh if you reduce it to 300 dimensions on the the chart on the left side shows the uh pair Wass distance between the points the original space and the uh radio space uh things are pretty intact you don't lose a lot of shape of the data while coming down to even 300 Dimensions but if you go down to for example 10,000
Dimensions which is a little higher than uh what you want uh you have the data being preserved almost uh entirely uh perfectly so uh the the other way to uh look at uh reducing Dimensions is to explore uh possible subspaces of data and this is what uh we do when we try to uh build our outl detection algorithms uh one way to uh look at interesting subspaces is to see how explainable an outlier is in that Subspace so imagine this green uh star if you can see it um as a possible outlayer and these are different uh projections of data in different two- dimensional spaces uh from original high dimension and uh this these are possibly
useful subspaces because in this space I can explain my uh the star being an outlayer because it's further removed from the other uh cohesive points whereas these projections uh it becomes very hard to explain the star as an outlayer because it's right in the smack in the middle of all the uh other points so um there are a variety of uh outlayer detection algorithms out there uh one class svm being the most popular uh outl detection algorithm uh there are a number of uh deep learning uh algorithms that are uh really popular right now including the replicator Neo networks uh one problem though with uh most deep learning algorithms is it's uh ridiculously data hungry which might not
be a problem because we have have the hardware uh to uh deal with it and we have a lot of data and security but the real problem comes from you know deeping networks are a big black box which are really hard to interpret and one of the goals of our project is to be able to provide interpretable explainable uh machine learning results so uh the one we go with are subspace-based methods uh I'll go over one such method very briefly so uh the algorithm itself is is really simple uh we uh we the the the premise is that we are presented with uh different query data that are possibly suspicious from a variety of threat intelligence sources or by the
analyst themselves and we are we want to be able to pick out similarly malitia data points and um we uh to this end we generate uh a bunch of lower dimensional subspaces we calculate what is called a contrast where uh the outlier is furthest removed from from uh the other uh points the the query outlier and we keep these high contrast subspaces we throw away the other subspaces um we add possibly additional Dimensions uh in a way to keep the uh the contrast high and we repeat till this is possible and we find and and then in this space that we pick we find other data points that look similarly uh outlier is uh compared to the query points that
you began with um so uh and and the premise of this comes from you know the the often attackers masquerade their uh vectors uh to look uh very uh look like the benign traffic and the tell often is from one or few of the network attributes and we want to be able to zero in on these uh attributes that uh give us the T so we can find similar uh malicious uh points as well and uh so this is an example of high contrast you have uh really cohesive points in the in the in this projected space um this is an example of low contrast where the data is really spread out and you you don't want to
keep this uh spread out uh projected uh data so this briefly how many minutes do we have okay um so this chart kind of briefly briefly goes over what we do um we have data from our uh you know from our sensor going to a cloud this could be Sim data this could be uh data from files data from uh logs but essentially you have data that you have you have represented in a in a way uh that machine learning algorithms can um can takeen you have uh possibly come up with the right um um similarity measure that enables you to compare the data the right way and then um what we do is we we do the sub
Subspace projection we uh arrive at the right Subspace where uh the tell is pronounced uh we find other uh outliers in this in this space where the out layers are similar to the uh original uh point in the first place and therefore the on demand aspect of it you you you want to find the subspaces and the outlayer on demand starting with uh um suspicious points that are picked out by the analyst or other threat intelligence sources um and then visualize so I think a lot of problem with machine learning comes from the ability to not explain the results of machine learning and uh our hope is that with our uh visualization mechanisms uh we'll be able to tell the
right story include the user in the feedback mechanism uh and continuously improve uh this uh process that we have going to skip over this um so there's still a lot of uh uh challenges uh and and and a variety of them are are really hard the primary challenge that we have and I think a lot of people in security have is to be able to get curated label data um while the uh there are possible Benchmark attacks uh that are publicly available uh and you could pick a a number of examples from your own network or your customers Network um of uh malous activity every malicious activity looks possibly different from other malicious activity and uh to be able to get a good
representation uh of uh all the or a good number of malicious activity becomes very hard um there is a serious lack of user feedback uh expert feedback and validation um which results in most machine learning algorithms having to rely on statistical scores like f score area under the curve and so on uh which may or may not mean a whole lot to the security analyst the interpretability of interpretability of the machine learning models again uh is is is very tricky and again one of our goals is to be able to make the models interpretable uh one way we do it is uh to be able to uh since we have a much lower dimensional Subspace
where we deal with the out layers we want to be able to generate an explanation in terms of a com linear combination of the uh Dimensions that are in your lower Di ions as uh a possible explanation um to the user and and that's much more easier uh than doing this in a thousand dimensions for example and uh I think the biggest problem is that implicit trust is bad uh people either trust machine learning algorithms or not uh I I like this code that says garbage in and people think gospel out and the chat board from Microsoft is the perfect example of this uh people uh abuse the Tweet board uh vigorously and within a day it turned
out to be this female hating Nazi bot and it had to be taken down so uh for the success of machine learning you need the data to be uh your your algorithms are only going to be as good as the data that you have and uh uh you know trust but verify so uh the other problem that we have and a lot of other people have is uh you know possibly baking in existing bad behavior when you construct baselines of uh users and missiones so uh the takeaways are uh you know correlation does not imply cation uh there's a lot of um um data correlation algorithms out there but uh they don't explain what they do really well um and
in general more data beats a clever algorithm uh and also learn from many many models often there's no one algorithm to rule them all so uh you want to be able to run Ensemble of different uh models in order to get uh an effective uh answer uh so breach detection in general is hard U but machine learning should be able to help with um breach analytics and for and6 and uh I think that's it for me yes I have any questions
Related talks
 56:25
56:25 41:28
41:28 1:00:45
1:00:45 53:47
53:47 55:42
55:42 52:16
52:16